Downloaded 17 times






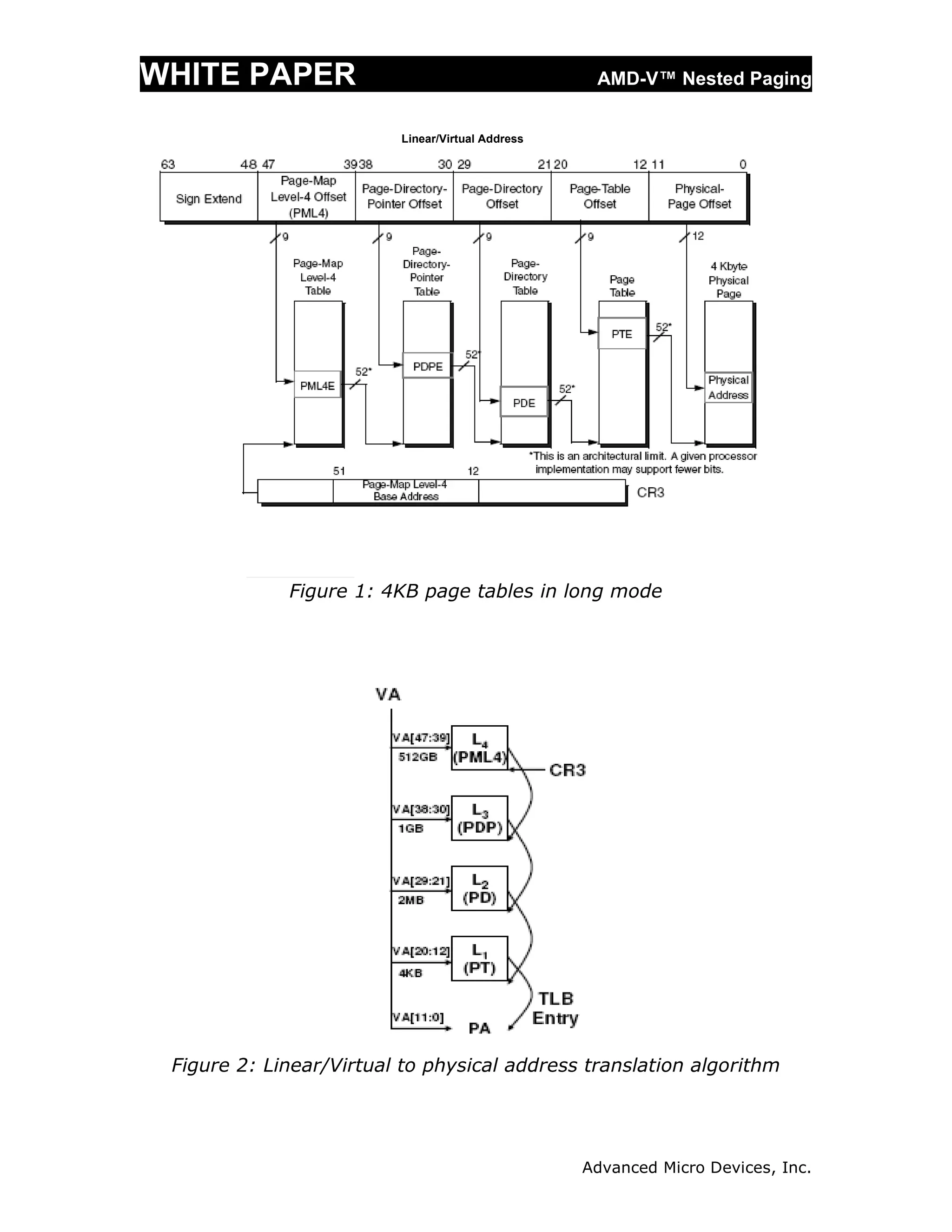



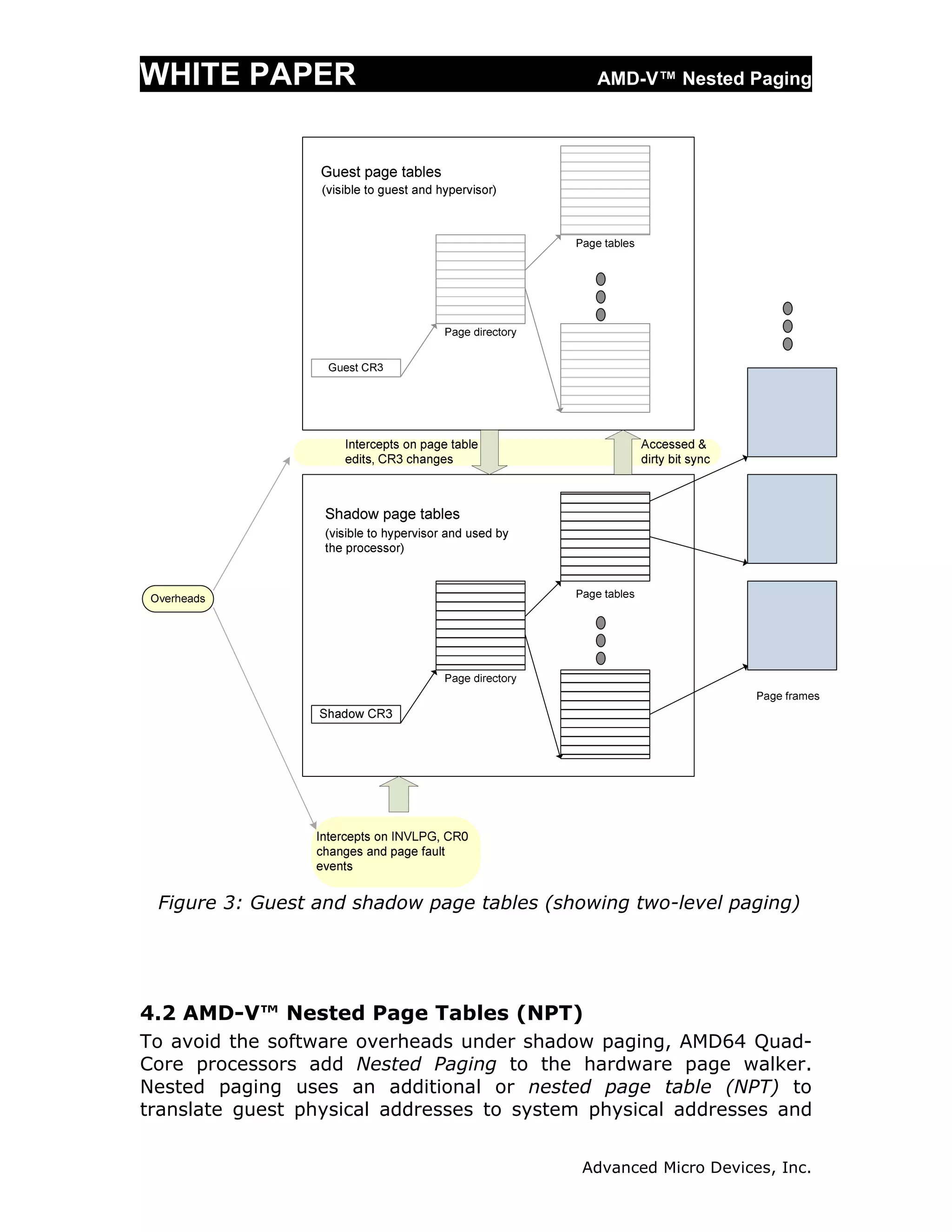






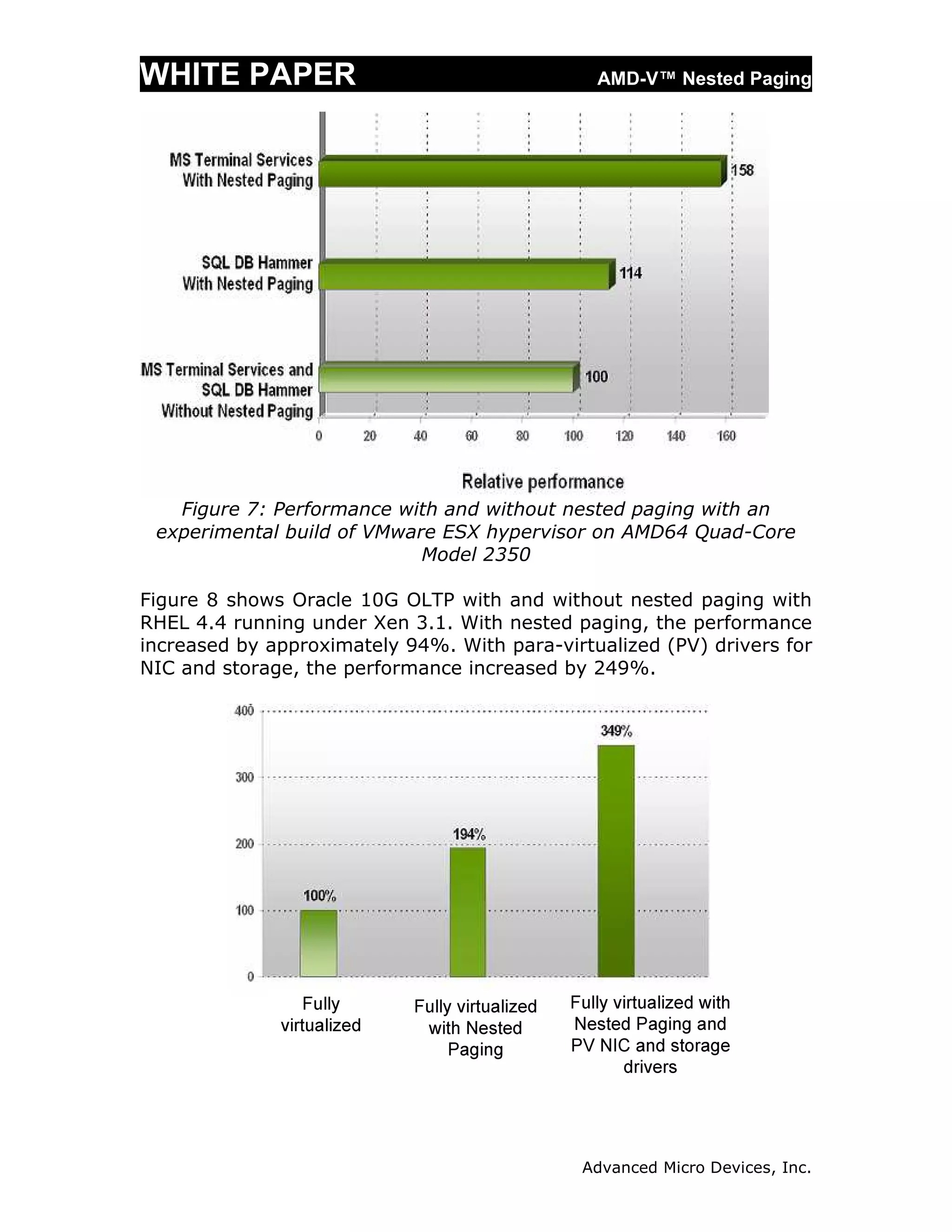


The document discusses AMD's nested paging technology, part of AMD-V virtualization, which introduces a hardware-based second level of address translation to improve virtualization performance. It details the drawbacks of existing software-based paging methods, such as shadow paging, which incur significant overheads, and explains how nested paging utilizes nested page tables to reduce these overheads. The white paper also highlights the advantages of nested paging, including reduced CPU utilization and improved memory efficiency for virtualized systems.

































































































