






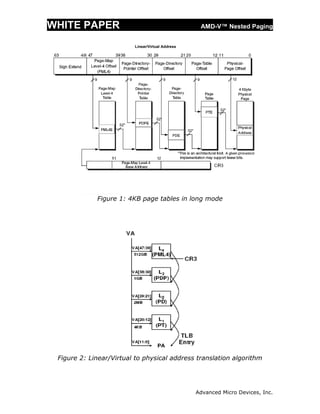



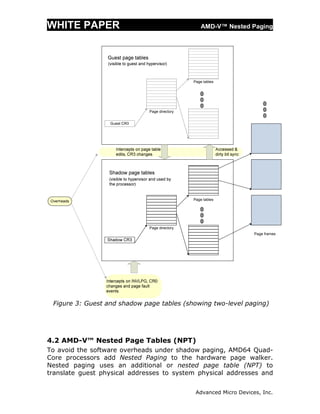






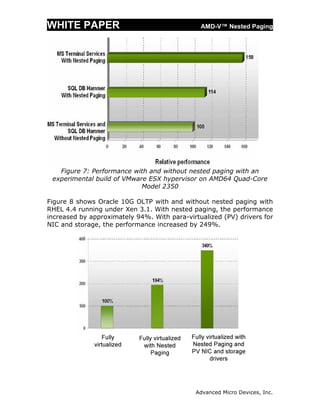

This white paper discusses AMD-V Nested Paging, which introduces hardware support for virtualizing x86 address translation through the use of nested page tables (NPT). Software-based shadow paging techniques for virtualizing address translation incur significant overhead. AMD-V Nested Paging avoids these overheads by using a second level of hardware page tables (NPT) maintained by the hypervisor to map guest physical addresses to system physical addresses, leaving guest operating systems in control of their own page tables. Nested paging removes the need to intercept and emulate guest modifications to page tables and reduces overhead compared to shadow paging.






























































