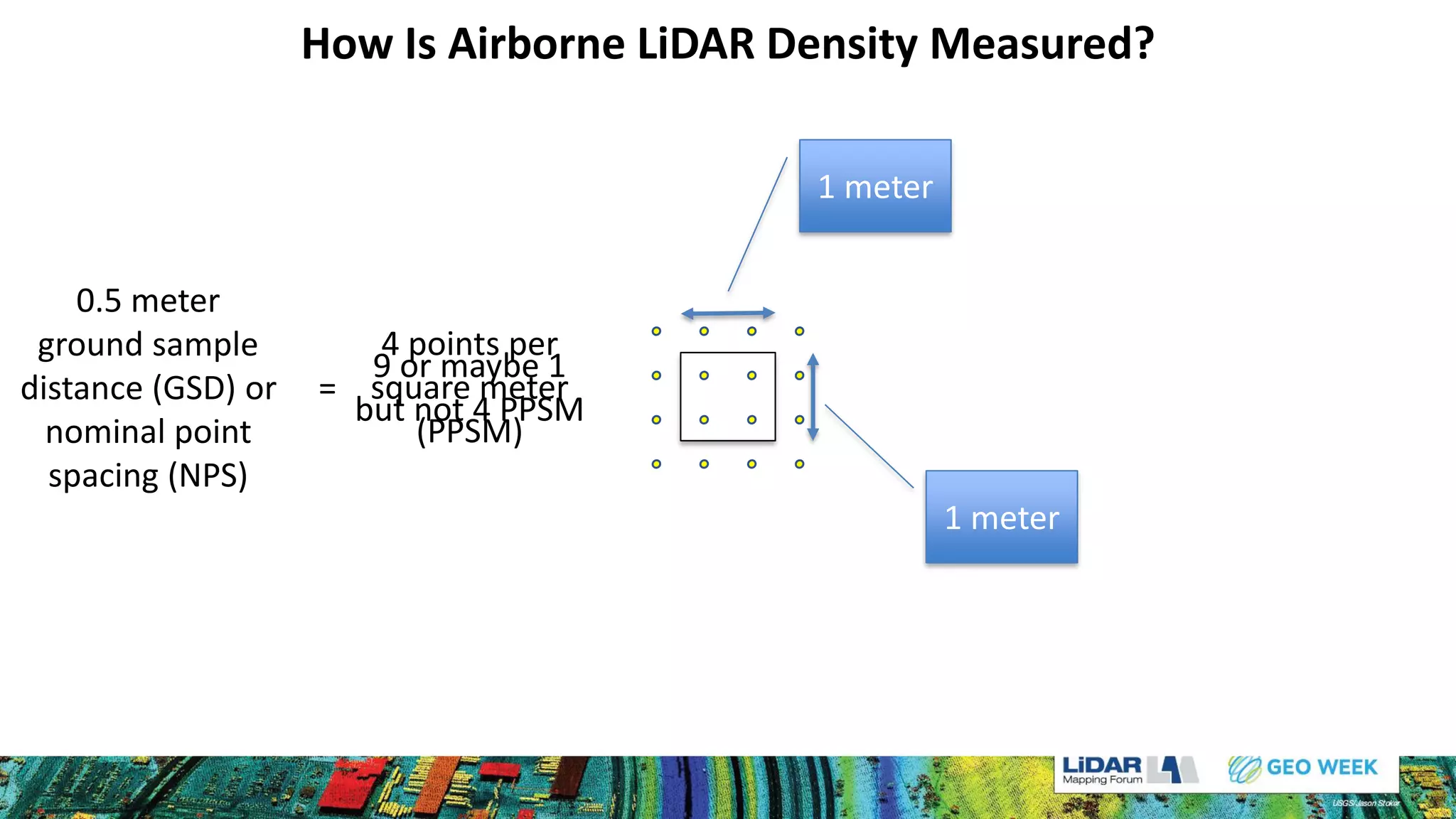
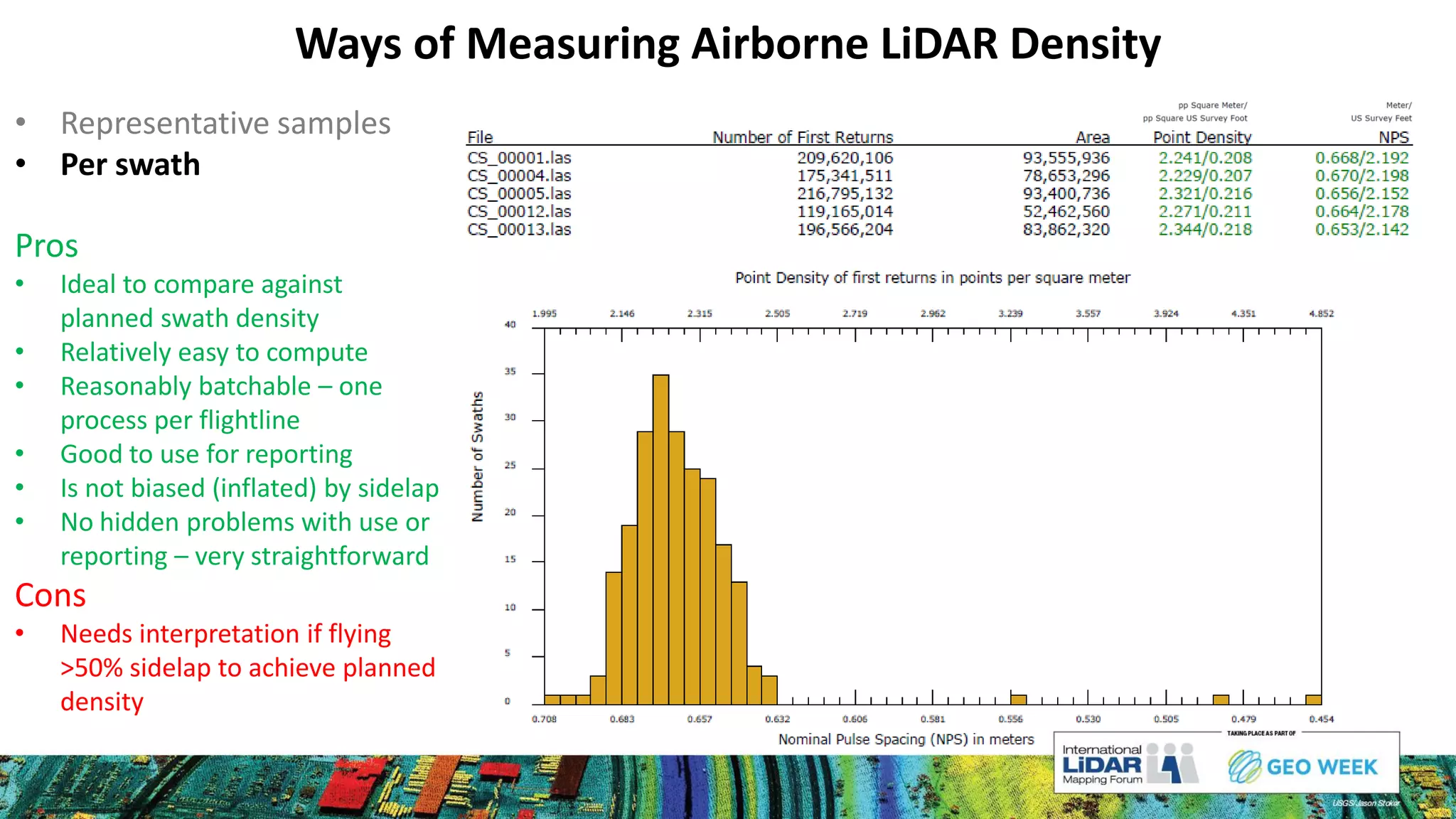
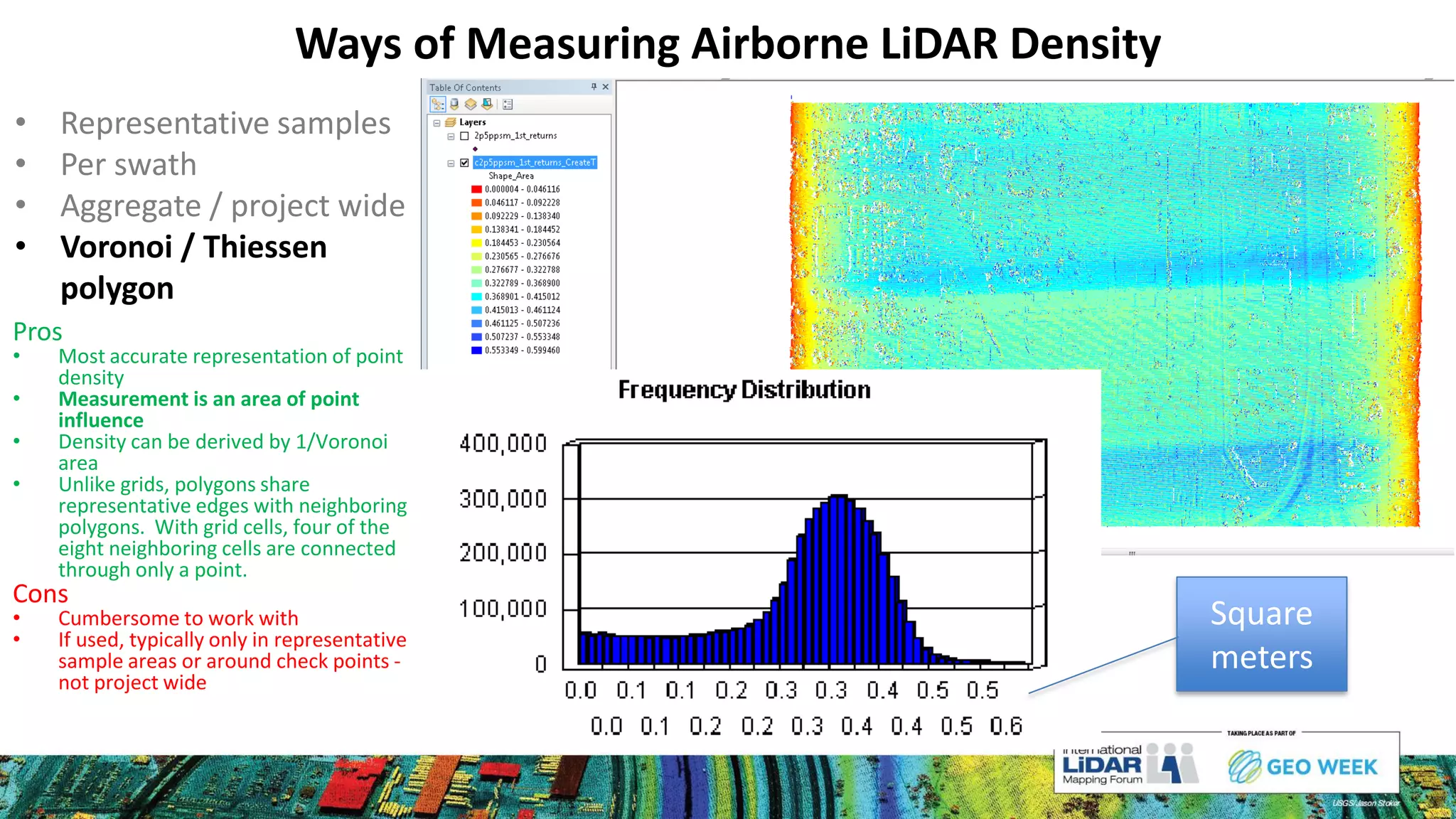
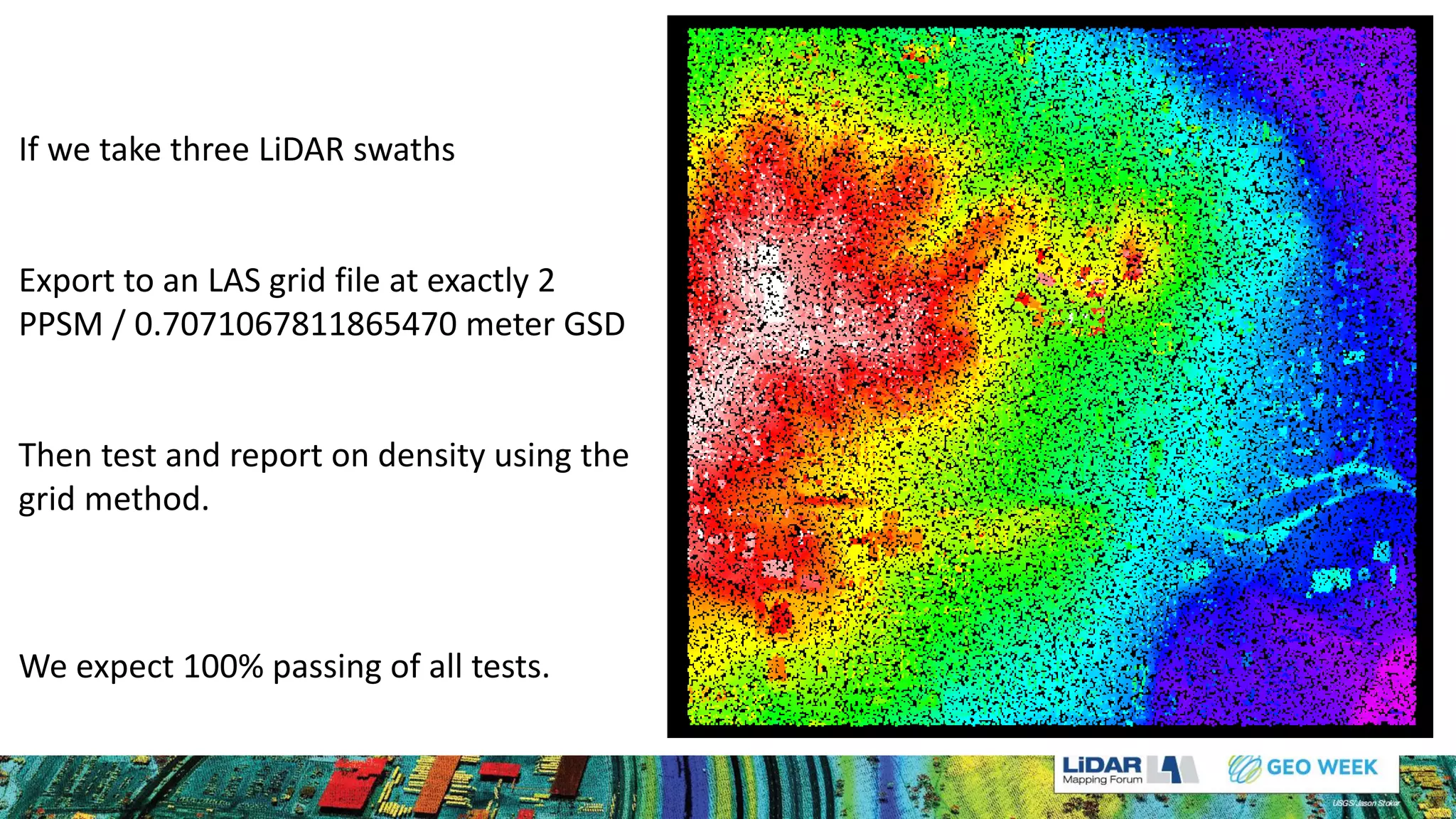
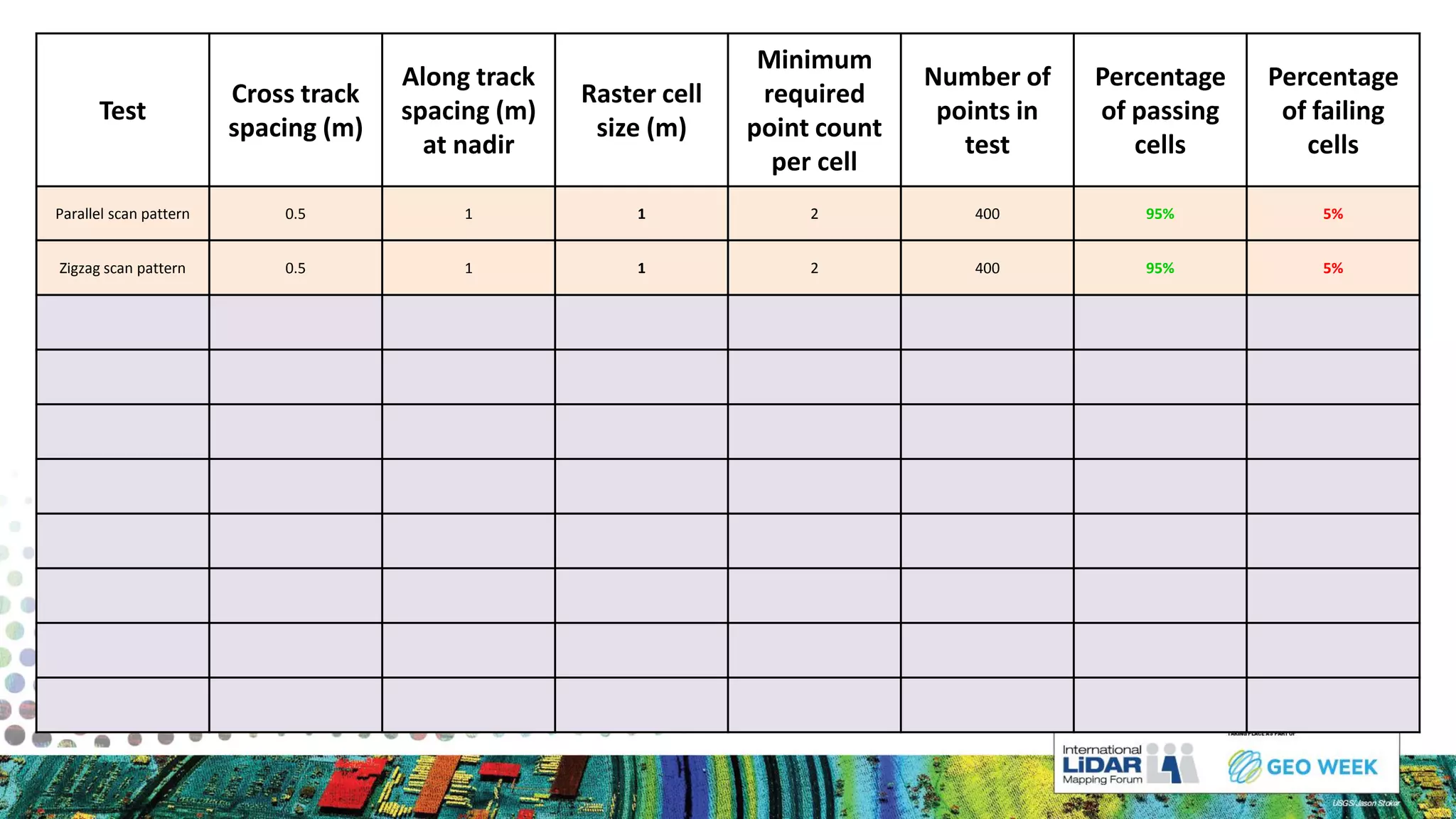
The document discusses methods for measuring airborne LiDAR point density, outlining various techniques like representative samples, per swath, and Voronoi polygons. It highlights the inaccuracies and potential biases in density reporting methods, particularly those relying on grid cells, and introduces the Nyquist sampling criteria as a more reliable alternative. Ultimately, the analysis indicates that poor point spacing can yield misleading pass/fail rates in density tests.