Introduction & History
Whatis Seq2Seq?
A neural network architecture that transforms one sequence of data into another sequence, enabling variable-length input-output
mappings.
2014
Introduced by Google researchers
Sutskever et al. for machine translation
2015-2016
Attention mechanisms added by
Bahdanau and Luong, revolutionizing
performance
2017+
Foundation for transformers and modern
NLP breakthroughs
Reference: Sutskever et al., "Sequence to Sequence Learning with Neural Networks" (2014)
3.
What is aSeq2Seq Model?
Core Concept
An encoder-decoder architecture that maps variable-length input sequences to variable-length output sequences, learning to
compress input information into a fixed-size context vector.
Encoder
Processes input sequence and compresses information into context
vector
Context Vector
Fixed-size representation of entire input sequence
Decoder
Generates output sequence from context vector
Key Characteristics
Handles variable-length sequences
End-to-end training with backpropagation
Uses recurrent neural networks (LSTM/GRU)
No explicit alignment required
Neural Architecture Design
4.
Before Seq2Seq Models
Traditionalapproaches struggled with variable-length sequences and required explicit feature engineering
Statistical Machine Translation (SMT)
Used phrase-based models with alignment
Required extensive linguistic knowledge and hand-crafted features
Rule-Based Systems
Manually defined grammatical rules
Not scalable, language-specific
Fixed-Length Neural Networks
Could only handle fixed input sizes
Required padding or truncation
Explicit Alignment Models
Needed pre-defined word alignment
Complex pipeline, error propagation
💡 Key Problem: No unified framework for learning sequence-to-sequence mappings end-to-end
Pre-2014 Approaches
5.
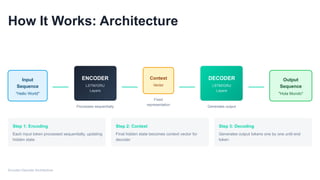
How It Works:Architecture
Input
Sequence
"Hello World"
ENCODER
LSTM/GRU
Layers
Processes sequentially
Context
Vector
Fixed
representation
DECODER
LSTM/GRU
Layers
Generates output
Output
Sequence
"Hola Mundo"
Step 1: Encoding
Each input token processed sequentially, updating
hidden state
Step 2: Context
Final hidden state becomes context vector for
decoder
Step 3: Decoding
Generates output tokens one by one until end
token
Encoder-Decoder Architecture
7.
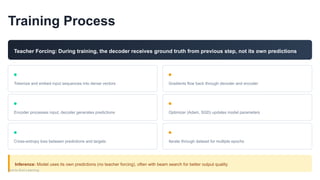
Training Process
Teacher Forcing:During training, the decoder receives ground truth from previous step, not its own predictions
Tokenize and embed input sequences into dense vectors
Encoder processes input, decoder generates predictions
Cross-entropy loss between predictions and targets
Gradients flow back through decoder and encoder
Optimizer (Adam, SGD) updates model parameters
Iterate through dataset for multiple epochs
Inference: Model uses its own predictions (no teacher forcing), often with beam search for better output quality
End-to-End Learning
8.
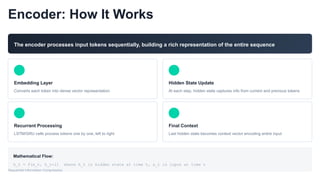
Encoder: How ItWorks
The encoder processes input tokens sequentially, building a rich representation of the entire sequence
Embedding Layer
Converts each token into dense vector representation
Recurrent Processing
LSTM/GRU cells process tokens one by one, left to right
Hidden State Update
At each step, hidden state captures info from current and previous tokens
Final Context
Last hidden state becomes context vector encoding entire input
Mathematical Flow:
h_t = f(x_t, h_t-1) where h_t is hidden state at time t, x_t is input at time t
Sequential Information Compression
9.
Decoder: How ItWorks
The decoder generates output sequence one token at a time, conditioned on context vector and previous outputs
Initialize
Start with context vector from encoder and special START token
Generate Token
RNN cell combines context, previous token, and hidden state
Softmax Output
Output layer produces probability distribution over vocabulary
Repeat Until END
Feed generated token back as input, continue until END token
Training: Uses ground truth tokens (teacher forcing) Inference: Uses its own predictions (autoregressive)
Autoregressive Generation
10.
What Does theModel Do?
Transforms input sequences into output sequences by learning complex mappings between variable-length data
Machine Translation
English → French, Spanish, etc.
Handles different language structures
Learns semantic equivalence
Text Summarization
Long document → concise summary
Extracts key information
Maintains coherence
Dialogue Systems
User query → system response
Chatbots and virtual assistants
Context-aware conversations
Speech Recognition
Audio sequence → text
Voice-to-text conversion
Real-time transcription
Code Generation
Natural language → code
Program synthesis
Automated development
Applications Across Domains
11.
Key Applications: NLPTasks
Neural Machine Translation
Translates text between languages with context awareness
Examples: Google Translate, multilingual chatbots, real-time subtitle
generation
Text Summarization
Condenses long documents into concise summaries
Examples: News article summaries, research paper abstracts, meeting
notes
Question Answering
Generates natural language answers from questions
Examples: Customer service bots, FAQ systems, educational assistants
Conversational AI
Powers dialogue systems and chatbots
Examples: Virtual assistants, customer support, interactive storytelling
Industry Impact: Seq2Seq models democratized NLP by eliminating need for hand-crafted features, enabling rapid deployment across languages and
domains
Natural Language Processing Applications
12.
Key Applications: BeyondText
Speech Recognition
Converts audio waveforms to text transcriptions
Examples: Voice assistants (Siri, Alexa), automated transcription services,
accessibility tools
Image Captioning
Generates natural language descriptions of images
Examples: Assistive tech for visually impaired, photo organization, social
media automation
Code Generation
Translates natural language to programming code
Examples: GitHub Copilot predecessors, SQL query generation, automated
documentation
Video Captioning
Describes video content in natural language
Examples: Automatic subtitle generation, video search engines, content
moderation
Cross-Modal Learning: Seq2Seq architecture's flexibility allows it to bridge different modalities (text, audio, images, code), making it fundamental to
multimodal AI systems
Multimodal Applications
13.
Key Improvements OverPrior Methods
End-to-End Learning
Single neural network learns entire pipeline without separate
components or manual feature engineering
Variable-Length Handling
Naturally processes sequences of any length without padding or
truncation requirements
Implicit Alignment
Learns alignment between input and output automatically through
training, no explicit rules needed
Context Preservation
Captures and maintains semantic meaning across entire sequences
through hidden states
Performance Gains
Translation Quality: Significant BLEU score improvements over phrase-
based SMT
Generalization: Better handling of rare words and novel sentence
structures
Scalability: Performance improves with more data and larger models
Flexibility: Same architecture works across multiple tasks
Revolutionary Advances
14.
The Attention Mechanism
Majorenhancement that revolutionized Seq2Seq performance by allowing decoder to focus on relevant encoder
states
Problem with Basic Seq2Seq
Fixed-size context vector becomes bottleneck for long sequences, losing
information
Solution: Attention
Weighted combination of all encoder hidden states based on relevance
How Attention Works
Benefits
Better long sequence handling, interpretability, alignment visualization
Impact
Foundation for transformer architecture and modern NLP
Bahdanau et al. (2015), Luong et al. (2015)
15.
The Evolution: AttentionMechanism
Problem: Information Bottleneck
Single context vector struggles to encode long sequences. Performance
degrades as input length increases.
Solution: Dynamic Attention
Decoder can "look back" at all encoder states, focusing on relevant parts for
each output.
How Attention Computes Focus
Step 1: Calculate similarity scores between decoder state and all encoder states
Step 2: Apply softmax to get attention weights (sum to 1)
Step 3: Compute weighted sum of encoder states
Step 4: Use this context for current prediction
Bahdanau Attention (2015)
Additive attention using concat and feedforward
network
Luong Attention (2015)
Multiplicative attention with dot product scoring
Impact on Field
Led directly to self-attention and transformers
Game-Changing Innovation (2015)
16.
Limitations - Part1
Sequential Processing
Cannot parallelize across sequence steps
Training is slow for long sequences
Vanishing Gradients
Difficult to capture very long-range dependencies
Information degrades over many time steps
Context Bottleneck
Fixed-size vector must encode all information
Performance degrades on very long inputs (even with attention)
Exposure Bias
Training uses ground truth, inference uses predictions
Mismatch causes error accumulation
Computational Challenges
Requires significant memory for hidden states, slow inference compared to feedforward networks, difficulty with batch processing of variable-length
sequences
Architectural Constraints
17.
Limitations - Part2
Rare Word Problem
Struggles with out-of-vocabulary words and proper nouns without
subword tokenization
Repetition & Consistency
Can generate repetitive or inconsistent outputs, especially in longer
sequences
Beam Search Limitations
Greedy/beam search can miss globally optimal solutions,
computationally expensive for large beams
Data Requirements
Requires large parallel datasets for training, limited performance on low-
resource languages
Why These Limitations Matter
These constraints led to the development of transformer architecture in 2017, which addressed many of these issues through self-attention mechanisms
and parallel processing, ultimately revolutionizing NLP.
Practical & Theoretical Challenges
18.
Modern Variants &Evolution
Convolutional Seq2Seq
Uses CNNs instead of RNNs for parallelization
(Facebook, 2017)
Transformers
Self-attention replaces recurrence entirely
(Vaswani et al., 2017)
BERT & GPT
Transformer-based models that dominated NLP
(2018+)
Legacy & Impact
Foundation: Seq2Seq established encoder-decoder paradigm still used
today
Inspiration: Attention mechanism led directly to transformer architecture
Current Use: Still effective for specific tasks with limited resources
Education: Perfect introduction to neural sequence modeling
While transformers have largely superseded Seq2Seq models in production, the fundamental concepts remain essential to understanding modern NLP
architectures.
From RNNs to Transformers
19.
Key Takeaways
Encoder-decoder architectureenables variable-length
sequence transformation
Attention mechanism solved bottleneck problem and
improved performance
Revolutionized machine translation and enabled end-to-end
learning
Sequential processing limits parallelization and long-range
modeling
Foundation for Modern NLP
Seq2Seq models pioneered the encoder-decoder paradigm and attention mechanism, establishing principles that power today's transformer-
based language models like BERT, GPT, and beyond.
Essential Concepts






































![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)





















