Downloaded 11 times






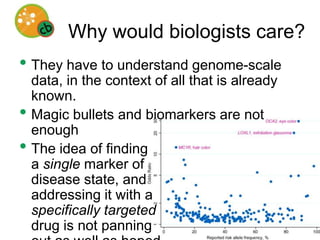
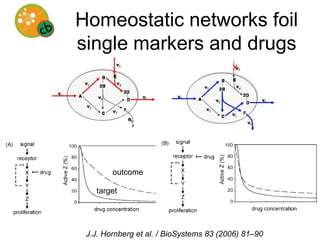
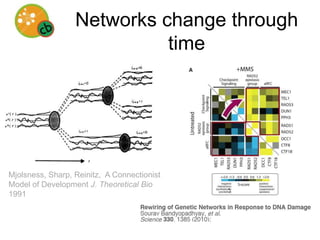



















This document discusses the potential for open source artificial intelligence to help understand molecular biology data. It argues that capturing common sense knowledge computationally has been challenging, but knowledge about molecular biology exists explicitly. An open source AI focused on molecular biology could help explain genomic data by developing a comprehensive knowledge base and using abductive inference. However, explaining biological phenomena is difficult and requires judgment. The document advocates for open source development to gain productivity advantages and build trust through transparency. It outlines challenges and opportunities for facilitating an open source AI community focused on understanding life.









































































