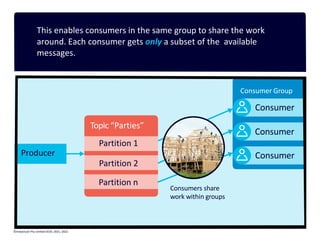
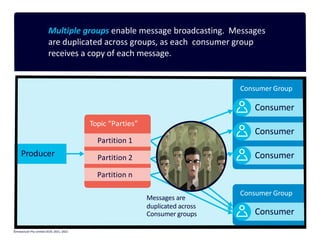
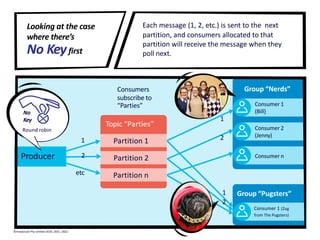
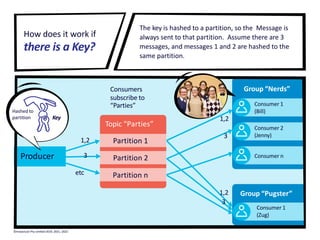
The document provides a visual introduction to Apache Kafka, illustrating how it facilitates message streaming through the metaphor of a postal service. It outlines Kafka's key concepts such as producers, consumers, topics, and partitions, while highlighting its benefits including speed, scalability, and reliability. The document also explains Kafka's delivery semantics, consumer groups, and how messages can be filtered and processed, making it a powerful tool for managing data streams across distributed systems.
![Paul Brebner
Technology Evangelist
www.instaclustr.com
sales@instaclustr.com
© Instaclustr Pty Limited, 2022 [https://www.instaclustr.com/
company/policies/terms-conditions/]. Except as permitted by the
copyright law applicable to you, you may not reproduce, distribute,
publish, display, communicate or transmit any of the content of this
document, in any form, but any means, without the prior written
permission of Instaclustr Pty Limited.](https://image.slidesharecdn.com/avisualintroductiontoapachekafkapaulbrebneropensource101-220608010423-5dfa2359/85/A-Visual-Introduction-to-Apache-Kafka-pdf-1-320.jpg)
![Paul Brebner
Technology Evangelist
www.instaclustr.com
sales@instaclustr.com
© Instaclustr Pty Limited, 2022 [https://www.instaclustr.com/
company/policies/terms-conditions/]. Except as permitted by the
copyright law applicable to you, you may not reproduce, distribute,
publish, display, communicate or transmit any of the content of this
document, in any form, but any means, without the prior written
permission of Instaclustr Pty Limited.](https://image.slidesharecdn.com/avisualintroductiontoapachekafkapaulbrebneropensource101-220608010423-5dfa2359/75/A-Visual-Introduction-to-Apache-Kafka-pdf-1-2048.jpg)







































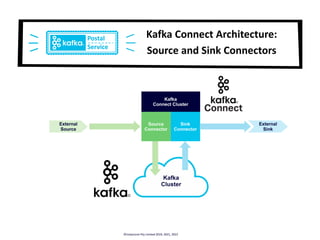


![Tides Topic
REST call
JSON result
{"metadata": {
"id":"8724580",
"name":"Key West",
"lat":"24.5508”,
"lon":"-81.8081"},
"data":[{
"t":"2020-09-24 04:18",
"v":"0.597"}]}
Elasticsearch sink connector Tides Index
Example of a Kafka Connect IoT pipeline:
Tidal Data à Kafka à Elasticsearch à Kibana
©Instaclustr Pty Limited, 2021
REST source connector
{"metadata": {
"id":"8724580",
"name":"Key West",
"lat":"24.5508”,
"lon":"-81.8081"},
"data":[{
"t":"2020-09-24
04:18",
"v":"0.597"}]}
©Instaclustr Pty Limited 2019, 2021, 2022](https://image.slidesharecdn.com/avisualintroductiontoapachekafkapaulbrebneropensource101-220608010423-5dfa2359/85/A-Visual-Introduction-to-Apache-Kafka-pdf-60-320.jpg)
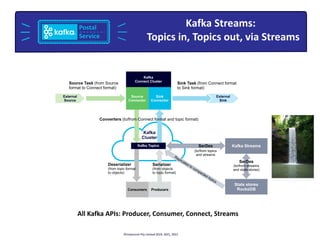
![Tides Topic
REST call
JSON result
{"metadata": {
"id":"8724580",
"name":"Key West",
"lat":"24.5508”,
"lon":"-81.8081"},
"data":[{
"t":"2020-09-24 04:18",
"v":"0.597"}]}
Elasticsearch sink connector Tides Index
Example of a Kafka Connect IoT pipeline:
Tidal Data à Kafka à Elasticsearch à Kibana
©Instaclustr Pty Limited, 2021
REST source connector
{"metadata": {
"id":"8724580",
"name":"Key West",
"lat":"24.5508”,
"lon":"-81.8081"},
"data":[{
"t":"2020-09-24
04:18",
"v":"0.597"}]}
©Instaclustr Pty Limited 2019, 2021, 2022
Connectors
require
Configuration](https://image.slidesharecdn.com/avisualintroductiontoapachekafkapaulbrebneropensource101-220608010423-5dfa2359/85/A-Visual-Introduction-to-Apache-Kafka-pdf-61-320.jpg)






![Dr Black has been murdered in the
Billiard Room with a Candlestick!
Whodunnit?!
[KSTREAM-FILTER-0000000024]: Conservatory: Professor Plum has no alibi
[KSTREAM-FILTER-0000000024]: Library: Colonel Mustard has no alibi
[KSTREAM-FILTER-0000000024]: Billiard Room: Mrs White has no alibi
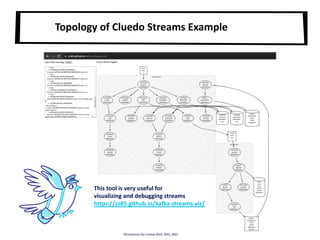
Cluedo Kafka Streams Example
Tracks who’s in
what rooms and
when, and emits
list of suspects
without an alibi
©Instaclustr Pty Limited 2019, 2021, 2022](https://image.slidesharecdn.com/avisualintroductiontoapachekafkapaulbrebneropensource101-220608010423-5dfa2359/85/A-Visual-Introduction-to-Apache-Kafka-pdf-71-320.jpg)






![All of my blogs (Cassandra, Kafka, MirrorMaker, Spark, Zookeeper,
OpenSearch, Redis, PostgreSQL, Debezium, Cadence, etc)
www.instaclustr.com/paul-brebner/
Kafka Streams Cluedo Example (part of “Kongo” Kafka intro series)
www.instaclustr.com/blog/kongo-5-3-apache-kafka-streams-examples/
Kafka Connect Pipeline Series (Tides data processing)
www.instaclustr.com/blog/kafka-connect-pipelines-conclusion-pipeline-series-part-10/
Kafka Xmas Tree Lights Simulation (my 1st Kafka program)
www.instaclustr.com/blog/seasons-greetings-instaclustr-kafka-christmas-tree-light-simulation/
Instaclustr’s Managed Kafka (Free Trial)
www.instaclustr.com/platform/managed-apache-kafka/
Instaclustr Blogs
© Instaclustr Pty Limited 2019, 2021, 2022 [https://www.instaclustr.com/company/policies/terms-conditions/]. Except as permitted by the copyright law applicable to you, you may not reproduce, distribute,
publish, display, communicate or transmit any of the content of this document, in any form, but any means, without the prior written permission of Instaclustr Pty Limited.](https://image.slidesharecdn.com/avisualintroductiontoapachekafkapaulbrebneropensource101-220608010423-5dfa2359/85/A-Visual-Introduction-to-Apache-Kafka-pdf-83-320.jpg)



































































