



![ActionContext and OGNL
An OGNL expression must choose one of the objects
in the ActionContext to use as its root object.
By default, the ValueStack serves as the root object for
resolving all OGNL expressions.
OGNL expression can be written in following syntax:
#session['user']
The # operator tells OGNL to use the named object,
located in its context, as the initial object for resolving
the rest of the expression.](https://image.slidesharecdn.com/9struts2adv-130527015009-phpapp01/85/Apache-Struts-2-Advance-4-320.jpg)








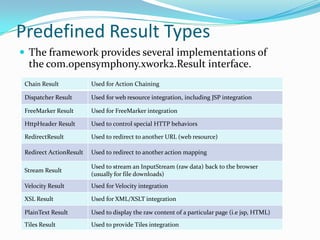















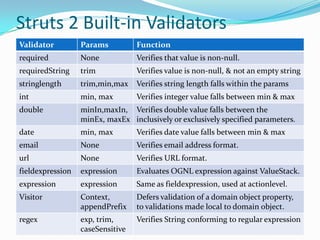


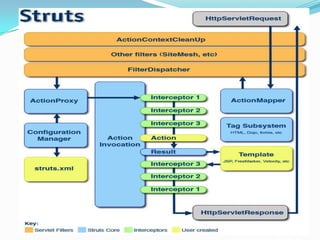



The document discusses the Struts 2 framework architecture. It explains that the ActionContext stores the ValueStack which contains request data. The ValueStack holds application domain data for an action invocation and serves as the default root object for resolving OGNL expressions. Various tags like Iterator, If, Url are used to work with and retrieve data from the ValueStack. Results like DispatcherResult handles view resolution by forwarding to JSPs. The validation framework uses validators, validation metadata and domain data to validate action properties.















![Rapid development tools for java ee 8 [tut2998]](https://cdn.slidesharecdn.com/ss_thumbnails/rapiddevelopmenttoolsforjavaee8tut2998-180216093949-thumbnail.jpg?width=640&height=640&fit=bounds)

















![Java Web Programming [8/9] : JSF and AJAX](https://cdn.slidesharecdn.com/ss_thumbnails/javaweb-module8-130106070914-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




















































