9.1 テキスト情報検索での適合フィードバック
• 最初のクエリ:New space satellite applications
1. 0.539, 08/13/91, NASA Hasn’t Scrapped Imaging Spectrometer
2. 0.533, 07/09/91, NASA Scratches Environment Gear From Satellite Plan
3. 0.528, 04/04/90, Science Panel Backs NASA Satellite Plan, But Urges Launches of Smaller Probes
4. 0.526, 09/09/91, A NASA Satellite Project Accomplishes Incredible Feat: Staying Within Budget
5. 0.525, 07/24/90, Scientist Who Exposed Global Warming Proposes Satellites for Climate Research
6. 0.524, 08/22/90, Report Provides Support for the Critics Of Using Big Satellites to Study Climate
7. 0.516, 04/13/87, Arianespace Receives Satellite Launch Pact From Telesat Canada
8. 0.509, 12/02/87, Telecommunications Tale of Two Companies
• ユーザは、関連ドキュメントに“+”をつける
+
+
+
Sec. 9.1.1
ユーザは人工衛星の新しい応用について知りたい
11.
9.1 テキスト情報検索での適合フィードバック
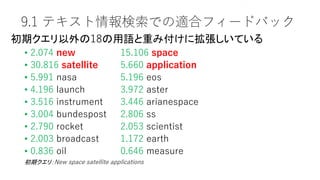
• 2.074new 15.106 space
• 30.816 satellite 5.660 application
• 5.991 nasa 5.196 eos
• 4.196 launch 3.972 aster
• 3.516 instrument 3.446 arianespace
• 3.004 bundespost 2.806 ss
• 2.790 rocket 2.053 scientist
• 2.003 broadcast 1.172 earth
• 0.836 oil 0.646 measure
Sec. 9.1.1
初期クエリ:New space satellite applications
初期クエリ以外の18の用語と重み付けに拡張しいている
12.
9.1 テキスト情報検索での適合フィードバック
1. 0.513,07/09/91, NASA Scratches Environment Gear From Satellite Plan
2. 0.500, 08/13/91, NASA Hasn’t Scrapped Imaging Spectrometer
3. 0.493, 08/07/89, When the Pentagon Launches a Secret Satellite, Space Sleuths Do Some Spy
Work of Their Own
4. 0.493, 07/31/89, NASA Uses ‘Warm’ Superconductors For Fast Circuit
5. 0.492, 12/02/87, Telecommunications Tale of Two Companies
6. 0.491, 07/09/91, Soviets May Adapt Parts of SS-20 Missile For Commercial Use
7. 0.490, 07/12/88, Gaping Gap: Pentagon Lags in Race To Match the Soviets In Rocket
Launchers
8. 0.490, 06/14/90, Rescue of Satellite By Space Agency To Cost $90 Million
2
1
8
Sec. 9.1.1
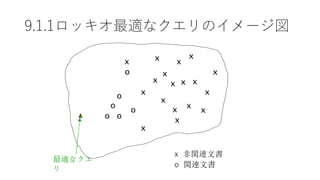
修正された検索結果
Relevance feedback oninitial query
x
x
x
x
o
o
o
Revised
query
x known non-relevant documents
o known relevant documents
o
o
o
x
x
x
x
x
x
x
x
xx
x
x
x
x
Initial
query
Sec. 9.1.1
9.2.3 自動シソーラスの生成
二つの主要なアプローチがある
手法 概要作り方
単語共起 定義1:2つの単語
が類似した単語と
共起する場合
term - term 類似度
同じ文章によく出てくる単語を共起とす
る
分法的解析 2つの単語が文法的
関係にある場合
And とか”や”と言った文法のルールを利用
You can harvest, peel, eat, prepare, etc.
apples and pears,











![9.1.1適合フィードバックのロッキオアルゴ
リズム
• 非関連文書との類似性を最小限かつ関連文書との類似性を最大限
となるクエリを見つけるアルゴリズム
𝑞 𝑜𝑝𝑡 = 𝑎𝑟𝑔𝑚𝑎𝑥 𝑠𝑖𝑚 𝑞, 𝐶𝑟 − 𝑠𝑖𝑚 𝑞, 𝐶 𝑛𝑟
𝑞 𝑜𝑝𝑡 =
1
𝐶𝑟
𝑑 𝑗∈𝐶 𝑟
𝑑𝑗 −
1
𝐶 𝑛𝑟
𝑑 𝑗∈𝐶 𝑛𝑟
𝑑𝑗
Sec. 9.1.1
𝑞 𝑜𝑝𝑡 :最適クエリのベクトル 𝑎𝑟𝑔𝑚𝑎𝑥:[]の値を最小化する 𝑞 を求める関数、𝑠𝑖𝑚:6.10式、 𝐶𝑟, 𝐶 𝑛𝑟 :全て
の関連文書、非関連文書の集合
この計算式には全ての関連文章𝐶𝑟がわからないという問題がある](https://image.slidesharecdn.com/iirno9-190604145232/85/9-13-320.jpg)






























![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180720-180723071258-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators](https://cdn.slidesharecdn.com/ss_thumbnails/stylegan-nada-210813013304-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)


























