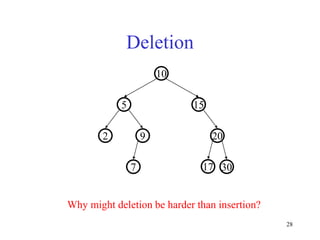
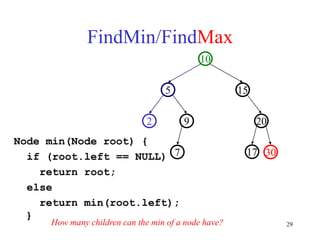
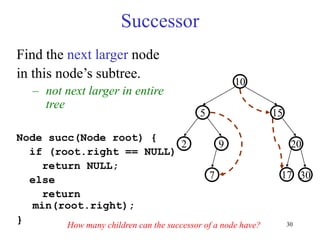
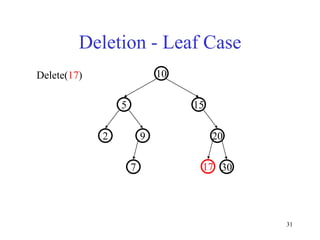
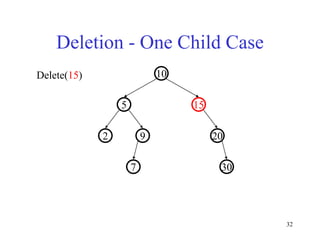
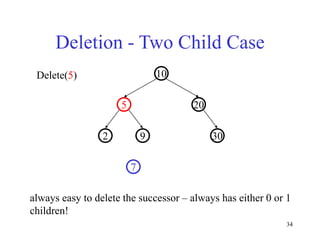
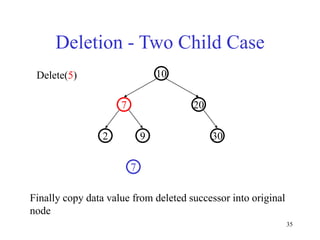
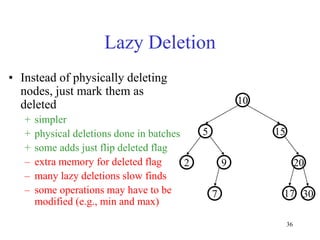
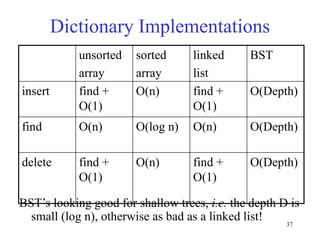
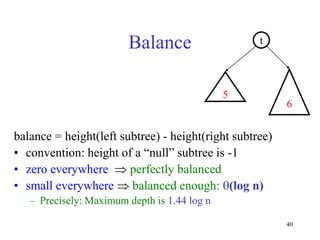
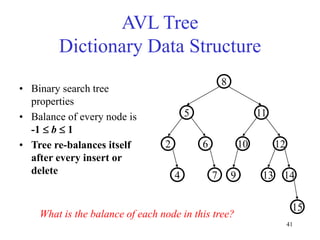
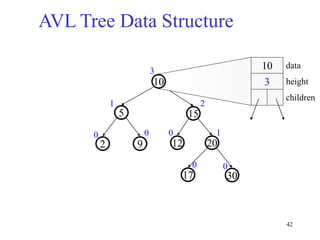
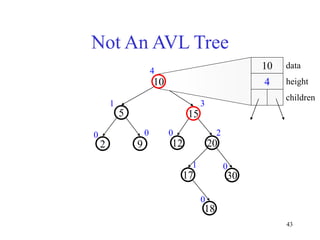
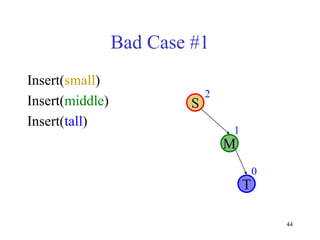
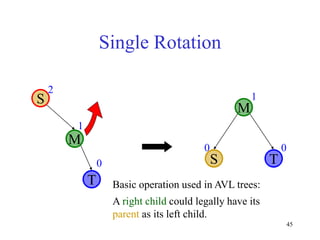
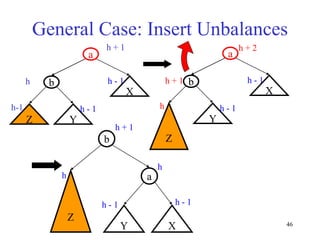
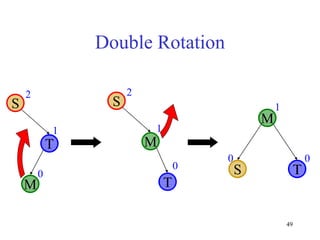
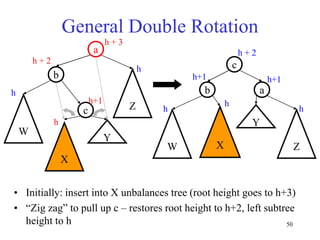
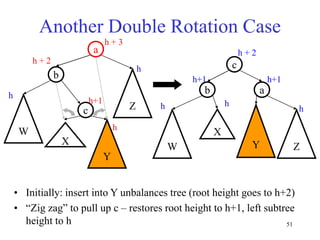
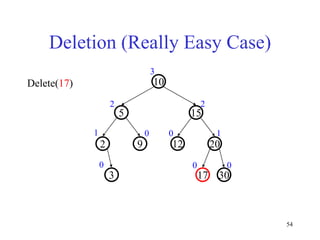
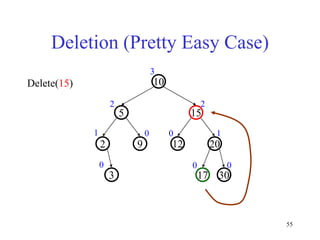
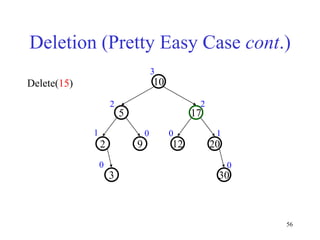
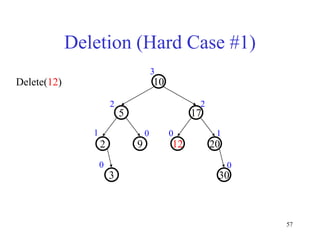
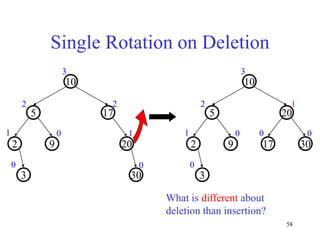
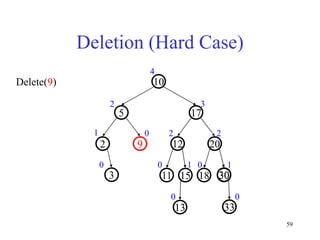
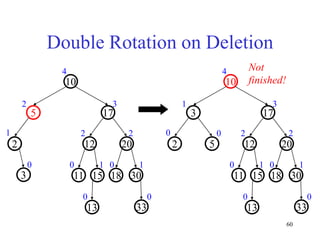
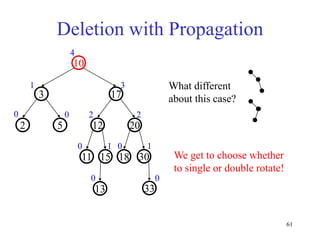
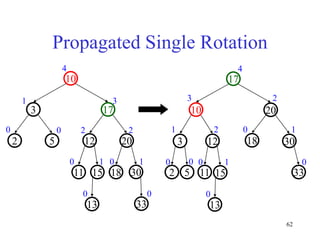
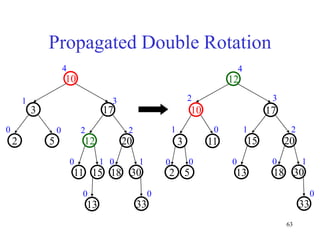
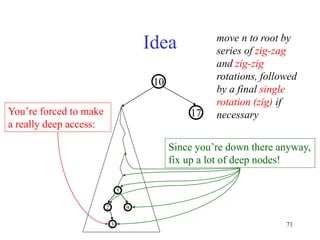
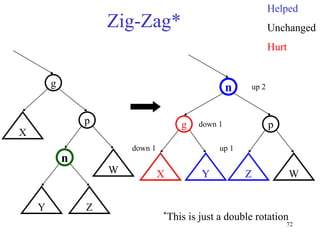
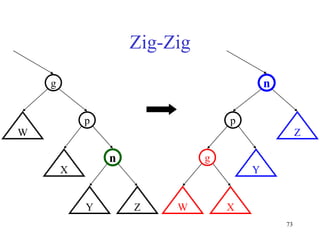
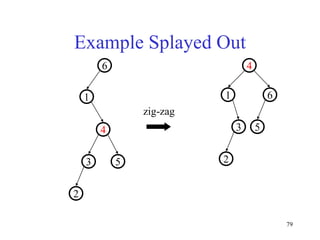
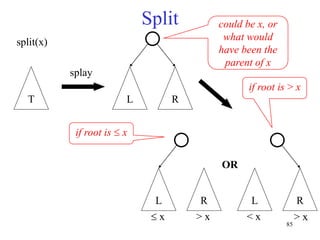
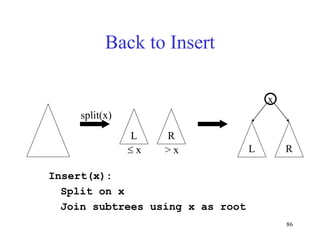
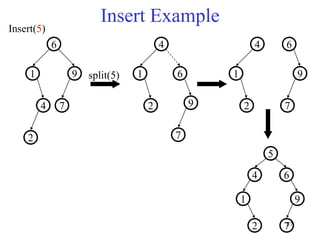
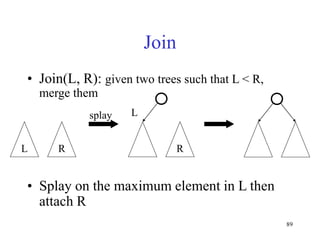
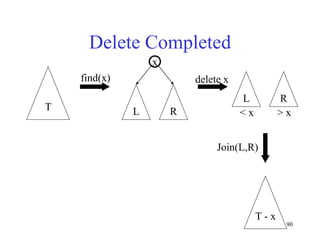
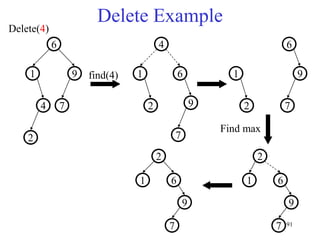
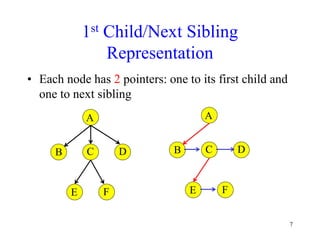
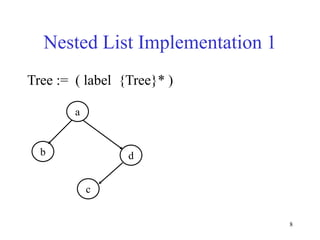
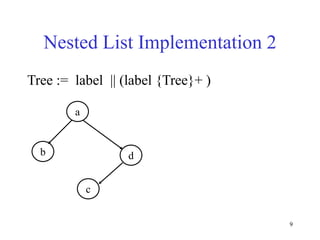
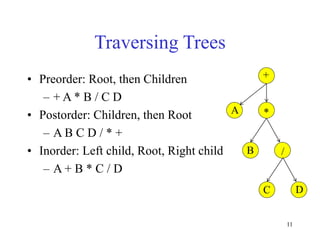
This document discusses binary search trees and balanced binary search trees like AVL trees. It begins with an overview of binary search trees and their properties. It then introduces the concept of balance factors and describes how AVL trees maintain a balance factor between -1 and 1 for every node through rotations. The document provides examples of single and double rotations performed during insertion to rebalance the tree. It concludes with an algorithm for inserting a node into an AVL tree that searches back up the tree to perform necessary rotations after an insertion causes imbalance.















![25
Random BST, cont.
• D(n) = D(L)+D(n-L-1)+(n-1)
• For random data, all subtree sizes equally likely
1
0
1
0
1
0
[ ( )] [ ( ) when left tree size is L]
[ ( )] [ ( )] [ ( 1)] ( 1)
2
[ ( )] [ ( )] ( 1)
[ (
Prob(left tree size is L)
1
[ ( ) / ] (lo
)] ( log
g )
)
n
L
n
L
n
L
E D n E D n
n
E D n n
E D n E D L E D n L n
E D n E D L n
n
E D n O n n
O n
this looks just like the
Quicksort average case
equation!](https://image.slidesharecdn.com/part4-trees-220817144908-bc75a526/85/part4-trees-ppt-25-320.jpg)