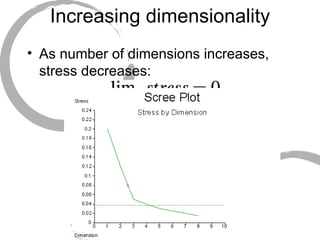
Hierarchical clustering is an algorithm that groups similar items into clusters. It begins by treating each item as its own cluster, then iteratively merges the closest pairs of clusters until all items are in one cluster. The distance between clusters can be computed in different ways, such as single-linkage (shortest distance), complete-linkage (longest distance), or average-linkage (mean distance). Multidimensional scaling (MDS) maps items to points in a multidimensional space such that similar items are closer together. It aims to minimize the stress between the input similarities and distances on the map. MDS is useful for visualizing patterns in similarity data and identifying clusters or underlying dimensions.