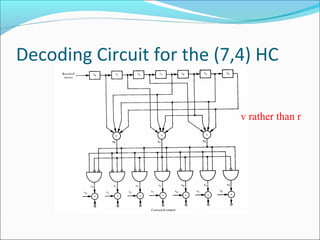
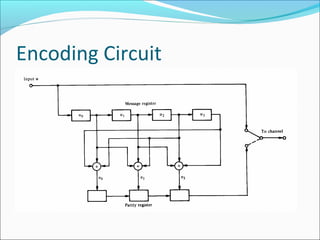
The document discusses linear block codes and their encoding and decoding. It begins by defining linearity and systematic codes. Encoding can be represented by a linear system using generator matrices G, where the codewords c are a linear combination of the message m and G. Decoding uses parity check matrices H, where the syndrome s is computed as the received word r multiplied by H. For Hamming codes, the syndrome corresponds to the location of a single error.









![Generator Matrix (cont’d)
Every codeword is a linear combination of these 4
codewords.
That is: c = m G, where
Storage requirement reduced from 2k
(n+k) to k(n-k).
[ ]G P | Ik
=
=
× − ×
1 1 0
0 1 1
1 1 1
1 0 1
1 0 0 0
0 1 0 0
0 0 1 0
0 0 0 1
k n k k k( )
](https://image.slidesharecdn.com/5linearblockcodes-151003035456-lva1-app6891/85/5-linear-block-codes-10-320.jpg)
![Parity-Check Matrix
For G = [ P | Ik], define the matrix H = [In-k | PT
]
(The size of H is (n-k)xn).
It follows that GHT
= 0.
Since c = mG, then cHT
= mGHT
= 0.
H =
1 0 0 1 0 1 1
0 1 0 1 1 1 0
0 0 1 0 1 1 1](https://image.slidesharecdn.com/5linearblockcodes-151003035456-lva1-app6891/85/5-linear-block-codes-11-320.jpg)
![Encoding Using H Matrix
[ ]c c c c c c c1 2 3 4 5 6 7
1 0 0
0 1 0
0 0 1
1 1 0
0 1 1
1 1 1
1 0 1
0
0
0
1 6 7
2 5 6
3 6 7
1 6 7
2 5 6
3 6 7
=
+ + =
+ + =
+ + =
⇒
+ +
+ +
+ +
0
c + c c c
c + c c c
c + c c c
c = c c c
c = c c c
c = c c c
4
4
5
4
4
5
information](https://image.slidesharecdn.com/5linearblockcodes-151003035456-lva1-app6891/85/5-linear-block-codes-12-320.jpg)






![Decoding of Hamming Codes
Consider a single-error pattern e(i)
, where i is a
number determining the position of the error.
s = e(i)
HT
= Hi
T
= the transpose of the ith
column of H.
Example:
[ ] [ ]0 1 0 0 0 0 0
1 0 0
0 1 0
0 0 1
1 1 0
0 1 1
1 1 1
1 0 1
0 1 0
=](https://image.slidesharecdn.com/5linearblockcodes-151003035456-lva1-app6891/85/5-linear-block-codes-20-320.jpg)