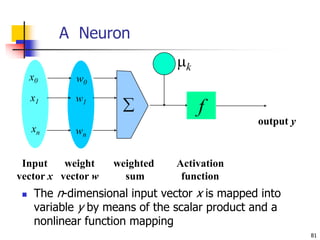
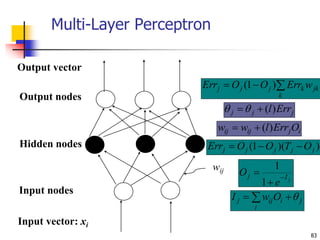
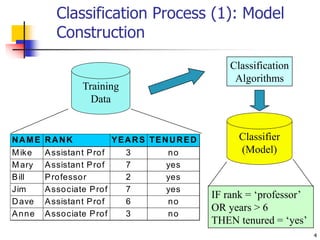
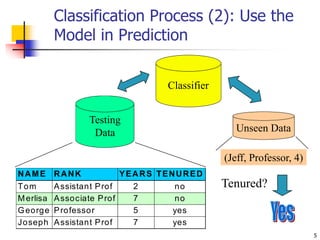
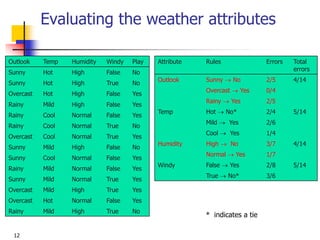
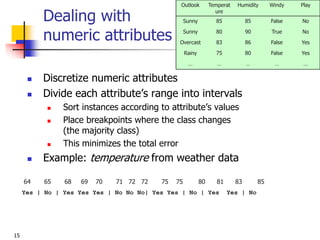
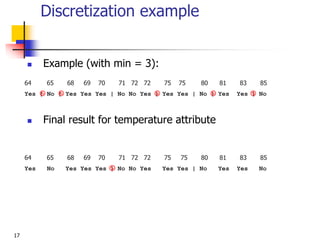
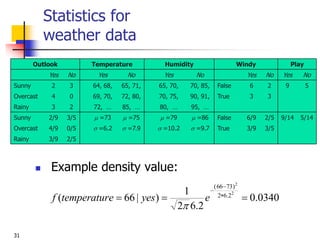
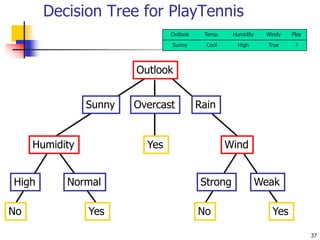
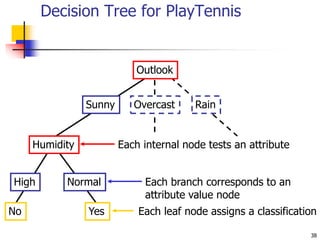
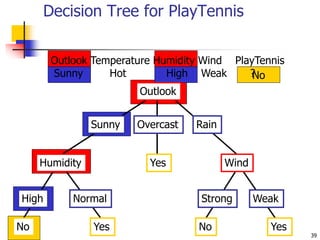
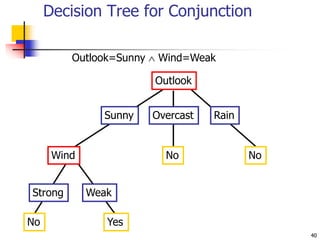
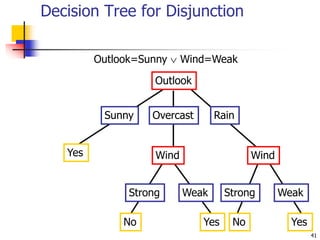
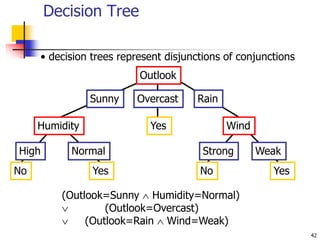
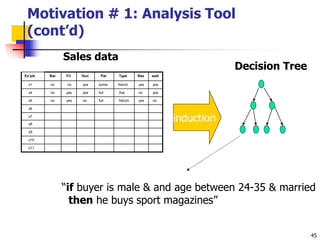
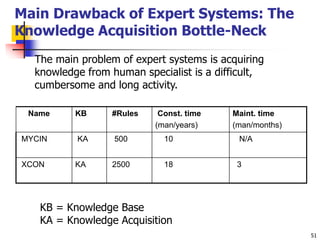
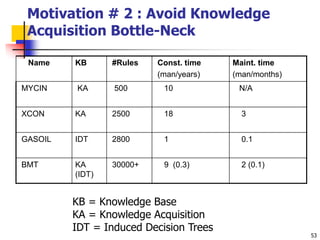
This document discusses classification, which is a type of supervised machine learning where algorithms are used to predict categorical class labels. There is a two-step process: 1) model construction using a training dataset to develop rules or formulas for classification, and 2) model usage to classify new data. Common applications include credit approval, target marketing, medical diagnosis, and treatment effectiveness analysis. The document also covers Bayesian classification, which uses probability distributions over class labels to classify new data instances based on attribute values and their probabilities.














![23
Bayes’s rule
Probability of event H given evidence E :
A priori probability of H :
Probability of event before evidence is seen
A posteriori probability of H :
Probability of event after evidence is seen
]
Pr[
]
Pr[
]
|
Pr[
]
|
Pr[
E
H
H
E
E
H
]
|
Pr[ E
H
]
Pr[H
Thomas Bayes
Born: 1702 in London, England
Died: 1761 in Tunbridge Wells, Kent, England
from Bayes “Essay towards solving a problem in the
doctrine of chances” (1763)](https://image.slidesharecdn.com/3-230415145714-3991ddb6/85/3-Classification-ppt-22-320.jpg)
![24
Naïve Bayes for classification
Classification learning: what’s the probability of the
class given an instance?
Evidence E = instance
Event H = class value for instance
Naïve assumption: evidence splits into parts (i.e.
attributes) that are independent
]
Pr[
]
Pr[
]
|
Pr[
]
|
Pr[
]
|
Pr[
]
|
Pr[ 2
1
E
H
H
E
H
E
H
E
E
H n
](https://image.slidesharecdn.com/3-230415145714-3991ddb6/85/3-Classification-ppt-23-320.jpg)
![25
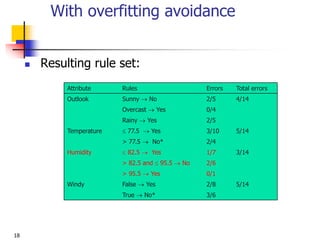
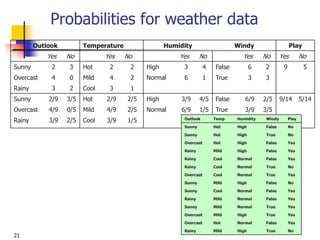
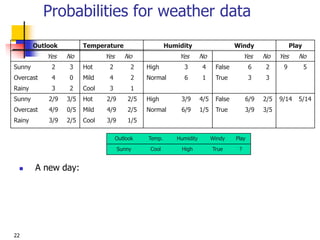
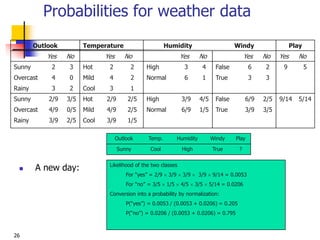
Weather data example
Outlook Temp. Humidity Windy Play
Sunny Cool High True ?
Evidence E
Probability of
class “yes”
]
|
Pr[
]
|
Pr[ yes
Sunny
Outlook
E
yes
]
|
Pr[ yes
Cool
e
Temperatur
]
|
Pr[ yes
High
Humidity
]
|
Pr[ yes
True
Windy
]
Pr[
]
Pr[
E
yes
]
Pr[
14
9
9
3
9
3
9
3
9
2
E
](https://image.slidesharecdn.com/3-230415145714-3991ddb6/85/3-Classification-ppt-24-320.jpg)
![27
The “zero-frequency problem”
What if an attribute value doesn’t occur with every class
value?
(e.g. “Humidity = high” for class “yes”)
Probability will be zero!
A posteriori probability will also be zero!
(No matter how likely the other values are!)
Remedy: add 1 to the count for every attribute value-class
combination (Laplace estimator)
Result: probabilities will never be zero!
(also: stabilizes probability estimates)
0
]
|
Pr[
E
yes
0
]
|
Pr[
yes
High
Humidity](https://image.slidesharecdn.com/3-230415145714-3991ddb6/85/3-Classification-ppt-26-320.jpg)

















![58
Which Attribute is ”best”?
A1=?
True False
[21+, 5-] [8+, 30-]
[29+,35-] A2=?
True False
[18+, 33-] [11+, 2-]
[29+,35-]](https://image.slidesharecdn.com/3-230415145714-3991ddb6/85/3-Classification-ppt-57-320.jpg)


![62
Information Gain
Gain(S,A): expected reduction in entropy due to sorting S on
attribute A
A1=?
True False
[21+, 5-] [8+, 30-]
[29+,35-] A2=?
True False
[18+, 33-] [11+, 2-]
[29+,35-]
Gain(S,A)=Entropy(S) - vvalues(A) |Sv|/|S| Entropy(Sv)
Entropy([29+,35-]) = -29/64 log2 29/64 – 35/64 log2 35/64
= 0.99](https://image.slidesharecdn.com/3-230415145714-3991ddb6/85/3-Classification-ppt-61-320.jpg)
![63
Information Gain
A1=?
True False
[21+, 5-] [8+, 30-]
[29+,35-]
Entropy([21+,5-]) = 0.71
Entropy([8+,30-]) = 0.74
Gain(S,A1)=Entropy(S)
-26/64*Entropy([21+,5-])
-38/64*Entropy([8+,30-])
=0.27
Entropy([18+,33-]) = 0.94
Entropy([8+,30-]) = 0.62
Gain(S,A2)=Entropy(S)
-51/64*Entropy([18+,33-])
-13/64*Entropy([11+,2-])
=0.12
A2=?
True False
[18+, 33-] [11+, 2-]
[29+,35-]](https://image.slidesharecdn.com/3-230415145714-3991ddb6/85/3-Classification-ppt-62-320.jpg)
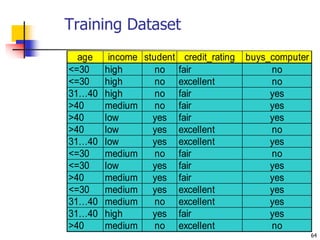

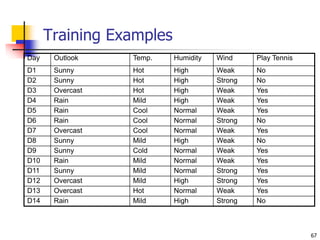
![68
Selecting the Next Attribute
Humidity
High Normal
[3+, 4-] [6+, 1-]
S=[9+,5-]
E=0.940
Gain(S,Humidity)
=0.940-(7/14)*0.985
– (7/14)*0.592
=0.151
E=0.985 E=0.592
Wind
Weak Strong
[6+, 2-] [3+, 3-]
S=[9+,5-]
E=0.940
E=0.811 E=1.0
Gain(S,Wind)
=0.940-(8/14)*0.811
– (6/14)*1.0
=0.048](https://image.slidesharecdn.com/3-230415145714-3991ddb6/85/3-Classification-ppt-67-320.jpg)
![69
Selecting the Next Attribute
Outlook
Sunny Rain
[2+, 3-] [3+, 2-]
S=[9+,5-]
E=0.940
Gain(S,Outlook)
=0.940-(5/14)*0.971
-(4/14)*0.0 – (5/14)*0.0971
=0.247
E=0.971 E=0.971
Over
cast
[4+, 0]
E=0.0
Temp ?](https://image.slidesharecdn.com/3-230415145714-3991ddb6/85/3-Classification-ppt-68-320.jpg)
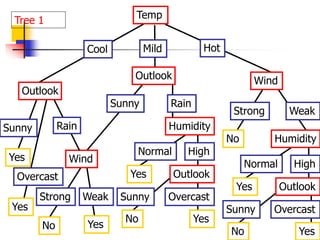
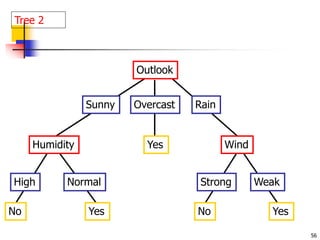
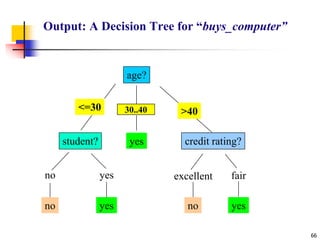
![70
ID3 Algorithm
Outlook
Sunny Overcast Rain
Yes
[D1,D2,…,D14]
[9+,5-]
Ssunny=[D1,D2,D8,D9,D11]
[2+,3-]
? ?
[D3,D7,D12,D13]
[4+,0-]
[D4,D5,D6,D10,D14]
[3+,2-]
Gain(Ssunny , Humidity)=0.970-(3/5)0.0 – 2/5(0.0) = 0.970
Gain(Ssunny , Temp.)=0.970-(2/5)0.0 –2/5(1.0)-(1/5)0.0 = 0.570
Gain(Ssunny , Wind)=0.970= -(2/5)1.0 – 3/5(0.918) = 0.019](https://image.slidesharecdn.com/3-230415145714-3991ddb6/85/3-Classification-ppt-69-320.jpg)
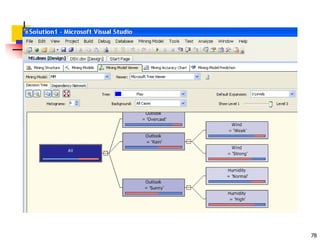
![71
ID3 Algorithm
Outlook
Sunny Overcast Rain
Humidity
High Normal
Wind
Strong Weak
No Yes
Yes
Yes
No
[D3,D7,D12,D13]
[D8,D9,D11] [D6,D14]
[D1,D2] [D4,D5,D10]](https://image.slidesharecdn.com/3-230415145714-3991ddb6/85/3-Classification-ppt-70-320.jpg)



![75
Attributes with Cost
Consider:
Medical diagnosis : blood test costs 1000 SEK
Robotics: width_from_one_feet has cost 23 secs.
How to learn a consistent tree with low expected
cost?
Replace Gain by :
Gain2(S,A)/Cost(A) [Tan, Schimmer 1990]
2Gain(S,A)-1/(Cost(A)+1)w w [0,1] [Nunez 1988]](https://image.slidesharecdn.com/3-230415145714-3991ddb6/85/3-Classification-ppt-74-320.jpg)