Download to read offline



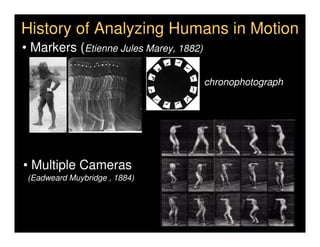



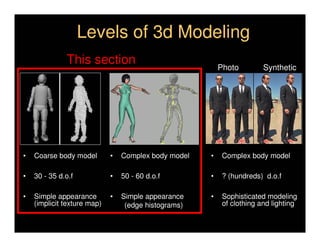

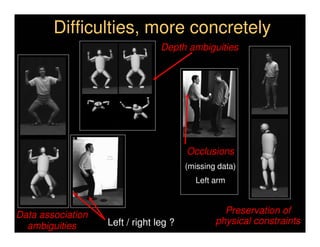

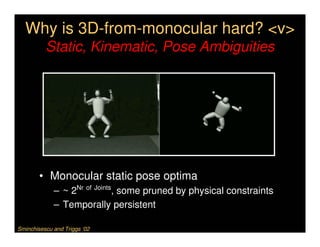
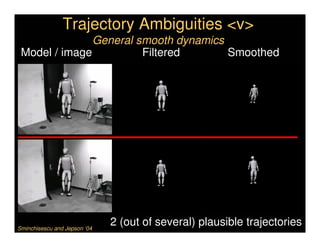
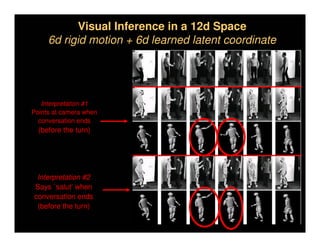
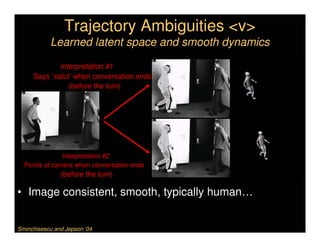
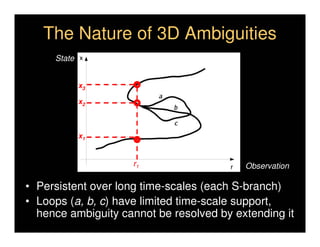
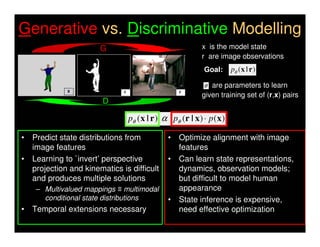
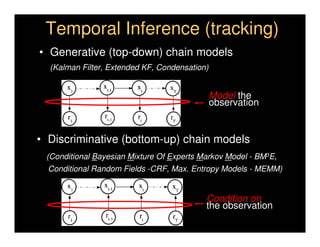
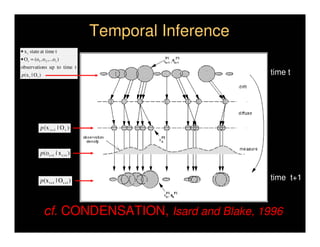

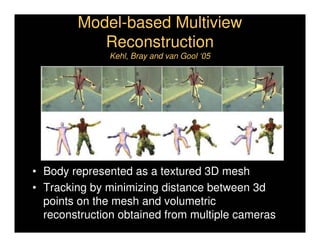
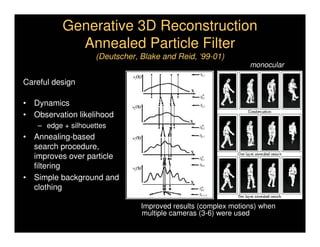

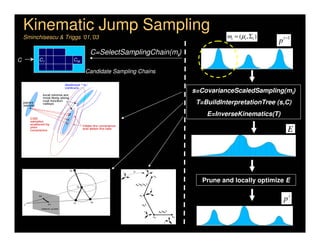




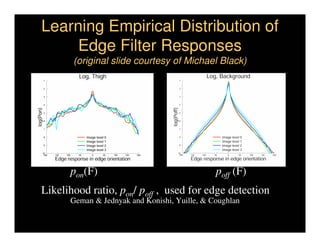
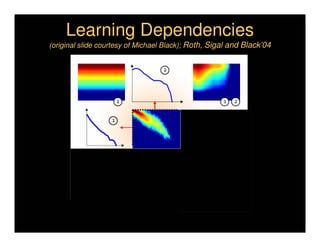
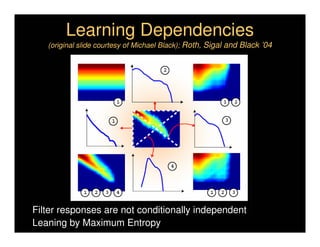
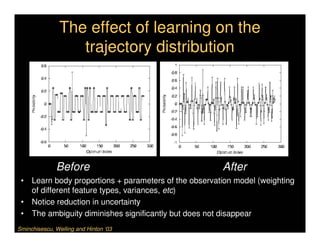


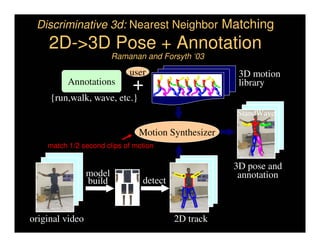

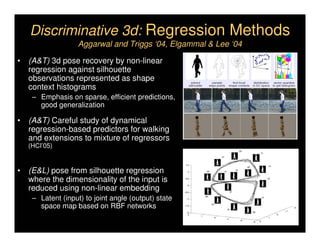
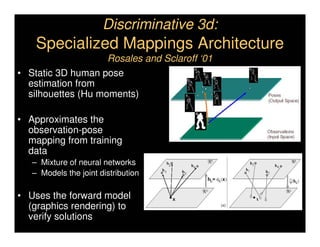
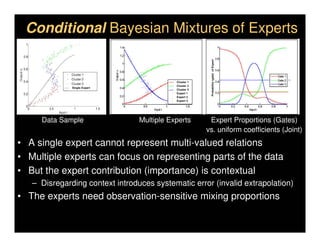



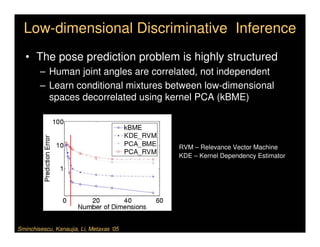

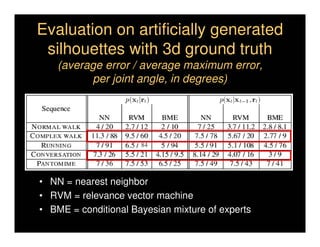








This document discusses analyzing 3D human motion from 2D images. It covers: 1) The difficulties in inferring 3D information from 2D images, including depth ambiguities, self-occlusions, and data association challenges. 2) Two main approaches to modeling 3D human motion - generative/alignment-based methods that predict state distributions from images, and discriminative/predictive methods that optimize alignment with image features. 3) Key techniques for temporal inference in tracking human motion over time, including generative methods like particle filtering and discriminative conditional models.




































































































