The document contains a link to a YouTube video and a reference to a deep learning book. Additional context appears to be scattered or incomplete. Overall, it suggests themes of online learning resources.






















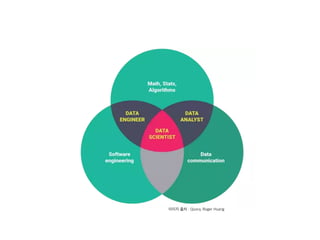
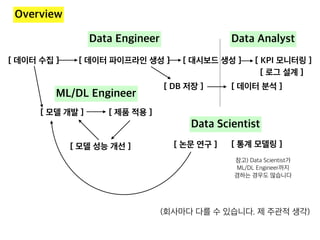
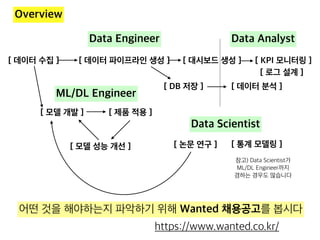




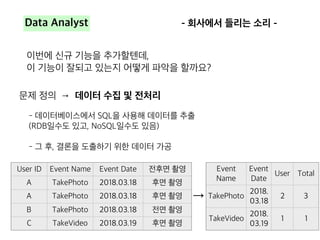









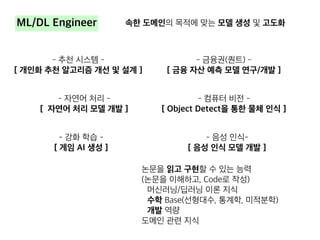


















































![[데이터야놀자2107] 강남 출근길에 판교/정자역에 내릴 사람 예측하기](https://cdn.slidesharecdn.com/ss_thumbnails/predict-get-off-station-171012210042-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DevGround] 린하게 구축하는 스타트업 데이터파이프라인](https://cdn.slidesharecdn.com/ss_thumbnails/devgroundkmongrevisedcraig190627finalscriptformatted-190828020444-thumbnail.jpg?width=640&height=640&fit=bounds)




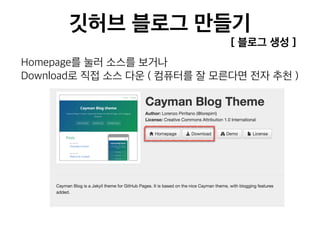
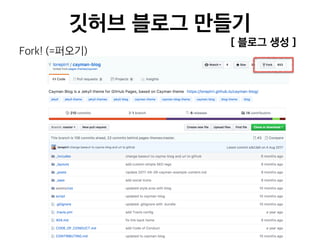
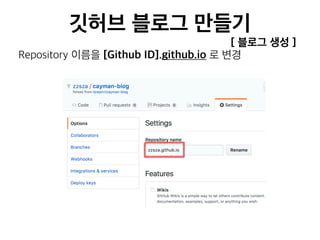
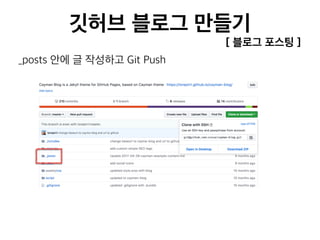
![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-1-180430181759-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NDC 2018] Spark, Flintrock, Airflow 로 구현하는 탄력적이고 유연한 데이터 분산처리 자동화 인프라 구축](https://cdn.slidesharecdn.com/ss_thumbnails/jparktemp-180424105624-thumbnail.jpg?width=640&height=640&fit=bounds)




![[261] 실시간 추천엔진 머신한대에 구겨넣기](https://cdn.slidesharecdn.com/ss_thumbnails/216-150915054828-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC 발표] 모바일 게임데이터분석 및 실전 활용](https://cdn.slidesharecdn.com/ss_thumbnails/20140529-140529031622-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




![[MLOps KR 행사] MLOps 춘추 전국 시대 정리(210605)](https://cdn.slidesharecdn.com/ss_thumbnails/mlops-basic-210605064957-thumbnail.jpg?width=640&height=640&fit=bounds)
























