Downloaded 23 times







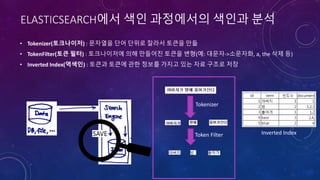
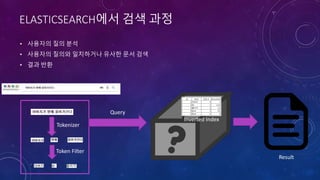

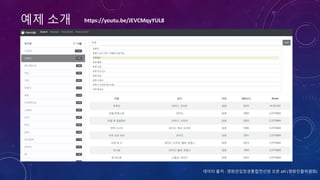
![ARCHITECTURE
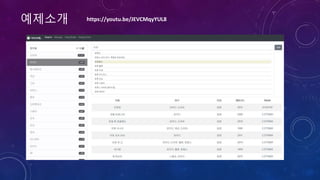
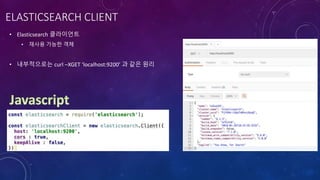
1. 읽기
영화정보 2. 색인
1. 검색요청
2. 검색
3. 결과반환
{ "movieCd": "20173732", "movieNm":
"살아남은 아이", "movieNmEn": "Last
Child", "prdtYear": "2017", "openDt": "",
"typeNm": "장편", "prdtStatNm": "기타",
"nationAlt": "한국", "genreAlt":
"드라마,가족", "repNationNm": "한국",
"repGenreNm": "드라마", "directors":
[ { "peopleNm": "신동석" } ],
"companys": []}](https://image.slidesharecdn.com/kcd2018javacafepubishver-180224153723/85/Elasticsearch-Node-js-19-320.jpg)
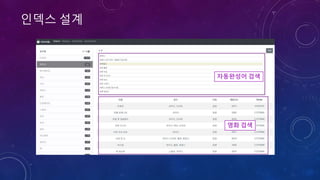
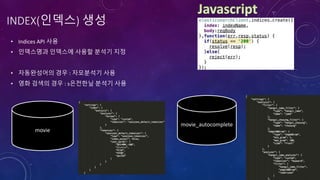
![인덱스 설계
movie_autocomplete
movie
{ "movieCd": "20173732", "movieNm":
"살아남은 아이", "movieNmEn": "Last
Child", "prdtYear": "2017", "openDt": "",
"typeNm": "장편", "prdtStatNm": "기타",
"nationAlt": "한국", "genreAlt":
"드라마,가족", "repNationNm": "한국",
"repGenreNm": "드라마", "directors":
[ { "peopleNm": "신동석" } ],
"companys": []}
{ "token": "ㅇ", "start_offset": 0, "end_offset": 11, "type": "word", "position": 0 }
{ "token": "ㅇㅏ", "start_offset": 0, "end_offset": 11, "type": "word", "position": 0 }
{ "token": "ㅇㅏㅂ", "start_offset": 0, "end_offset": 11, "type": "word", "position": 0 }
{ "token": "ㅇㅏㅂㅓ", "start_offset": 0, "end_offset": 11, "type": "word", "position": 0 }
{ "token": "ㅇㅏㅂㅓㅈ", "start_offset": 0, "end_offset": 11, "type": "word", "position": 0 }
{ "token": "ㅇㅏㅂㅓㅈㅣ", "start_offset": 0, "end_offset": 11, "type": "word", "position": 0 }
{ "token": "아버지/N", "start_offset": 0, "end_offset": 3, "type": "N", "position": 0 }
{ "token": "방/N", "start_offset": 4, "end_offset": 5, "type": "N", "position": 1 }
{ "token": "들어가/V", "start_offset": 6, "end_offset": 9, "type": "V", "position": 2 }
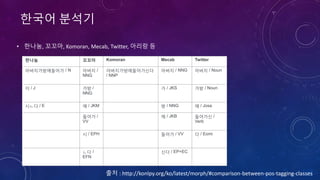
한글자모분석기
은전한닢s](https://image.slidesharecdn.com/kcd2018javacafepubishver-180224153723/85/Elasticsearch-Node-js-21-320.jpg)



오픈소스 검색엔진인 Elasticsearch 어떻게 저장하고 조회하는지 검색엔진의 개념에 대해서 간단히 살펴보고, Node.js 로 구현된 아주 간단한 예제를 소개합니다. - 검색엔진과 Elasticsearch 소개 - Elasticsearch에서의 색인 - Elasticsearch에서의 조회 - Node.js 로 구현된 예제 소개 * 자바카페 자바카페 페이스북 : https://www.facebook.com/groups/javacafe/ 자바카페 기술 블로그 : http://tech.javacafe.io/





![[2D1]Elasticsearch 성능 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/2d1elasticsearch-140929192211-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![Naver속도의, 속도에 의한, 속도를 위한 몽고DB (네이버 컨텐츠검색과 몽고DB) [Naver]](https://cdn.slidesharecdn.com/ss_thumbnails/naver-190916181334-thumbnail.jpg?width=640&height=640&fit=bounds)




![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)













![[215]네이버콘텐츠통계서비스소개 김기영](https://cdn.slidesharecdn.com/ss_thumbnails/215-161025030904-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Spring Camp 2018] 11번가 Spring Cloud 기반 MSA로의 전환 : 지난 1년간의 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/201804springcamp11stmsafinalpubslideshare-180527051608-thumbnail.jpg?width=640&height=640&fit=bounds)














![[4차]구글 알고리즘 분석(151106)](https://cdn.slidesharecdn.com/ss_thumbnails/4-151106-160217170051-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 17회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [중고책나라] : 실시간 데이터를 이용한 Elasticsearch 클러스터 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/random-230220154251-7145ba84-thumbnail.jpg?width=640&height=640&fit=bounds)



