Download to read offline









![ Process the text file one line at a time
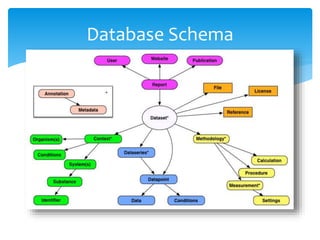
‘Generic’ rules to make decisions on a line
May be multiple rules for one line
Includes instructions to move down or stay on line
Sets of rules tailored to match the generic layout of the text
These were linked to datatype and publication
Rules and Rulesets
More sophiticated GetFormula regex (([A-Z][a-zA-Z0-9]{0,2}s)+)](https://image.slidesharecdn.com/acs251stchemextractor-160314162217/85/Rule-based-Capture-Storage-of-Scientific-Data-from-PDF-Files-and-Export-using-a-Generic-Scientific-Data-Model-9-320.jpg)













This document discusses a rule-based method for capturing and storing scientific data from PDF files, along with its export using a generic scientific data model. It details the process of text extraction, the creation of a structured yet flexible database using JSON-LD, and the functionality of a developed website for managing the extracted data. The initiative aims to improve data accessibility and interoperability while addressing challenges related to PDF as a format for data sharing.



















































































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)

