Download as PDF, PPTX



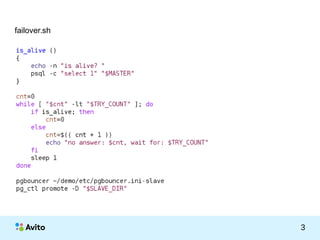





Документ представляет презентацию о настройке системы PostgreSQL с использованием архитектуры master-slave и механизма PITR (Point-in-Time Recovery). Включает обсуждение скрипта failover.sh, конфигураций для репликации и создание демонстрационной базы данных. Презентация сопровождается примерами команд и ссылками на ресурсы для дальнейшего изучения.



































































