Download as PDF, PPTX




























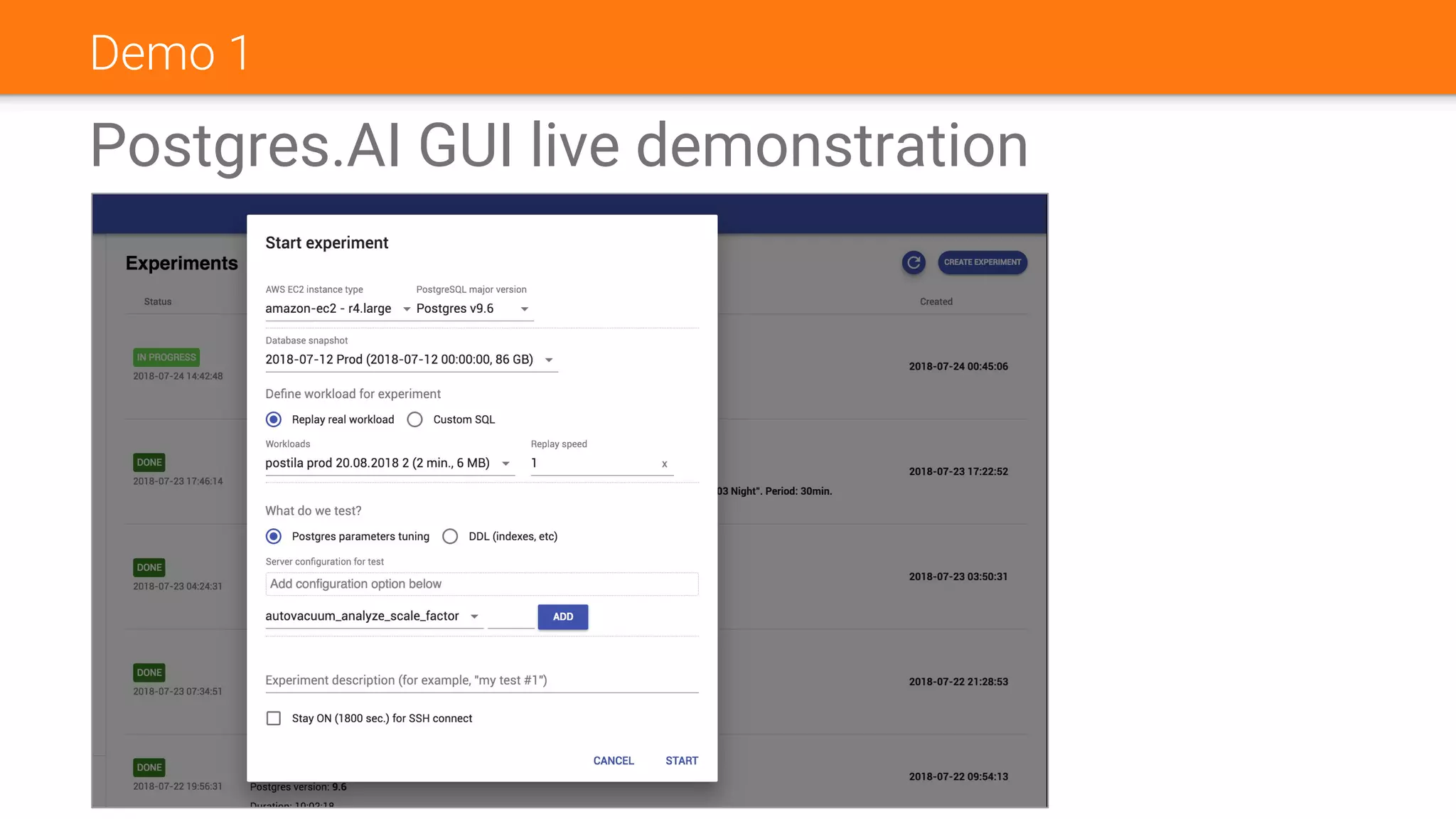
![What is the Database Experiment?
The input of a experimental run:
● Environment
○ Location (on-premise or GCP or AWS), hardware (CPU, RAM, disks)
○ System (OS, file system)
○ Postgres version
○ Postgres configuration
● Database snapshot. Can be:
○ A dump (regular or in directory format)
○ A physical archive (pg_basebackup or pgBackRest/WAL-E/WAL-G/…)
○ A replica promoted for experiments
○ Some synthetic one, a generated database (“create table as …”, pgbench -i, etc)
● Workload. Can be:
○ Synthetic (custom SQL), single-threaded
○ Synthetic (custom SQL), multi-threaded (with pgbench)
○ “Real workload” (based on logs)
● [Optional] Delta:
○ Configuration change(s) (e.g.: shared_buffers = 16GB)
○ Some DDL (e.g.: `create index …`). “Undo” DDL is required in this case `drop index …`) to enable
serialization of experiments](https://image.slidesharecdn.com/nancycli-180725050819/75/Nancy-CLI-Automated-Database-Experiments-39-2048.jpg)

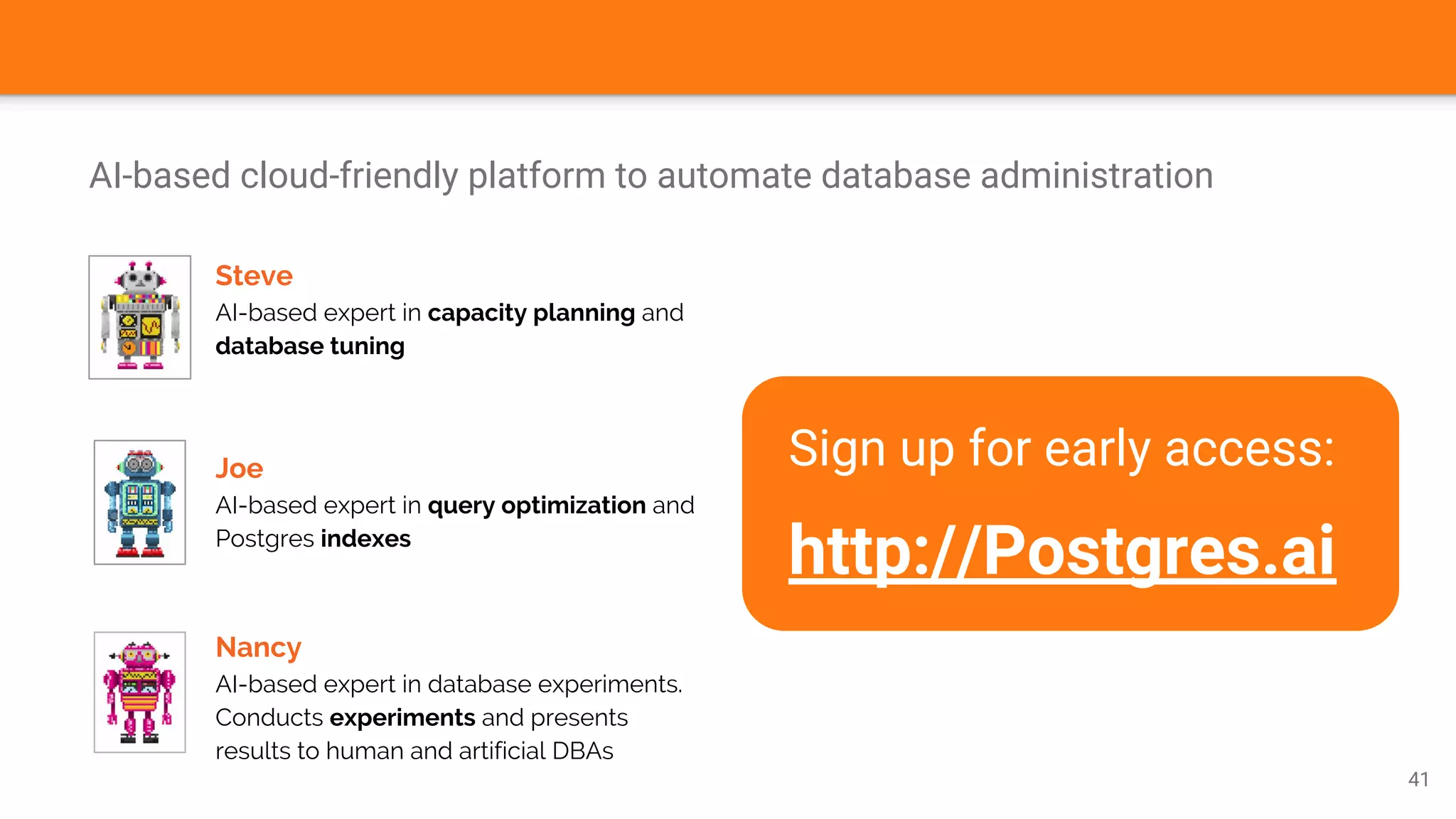
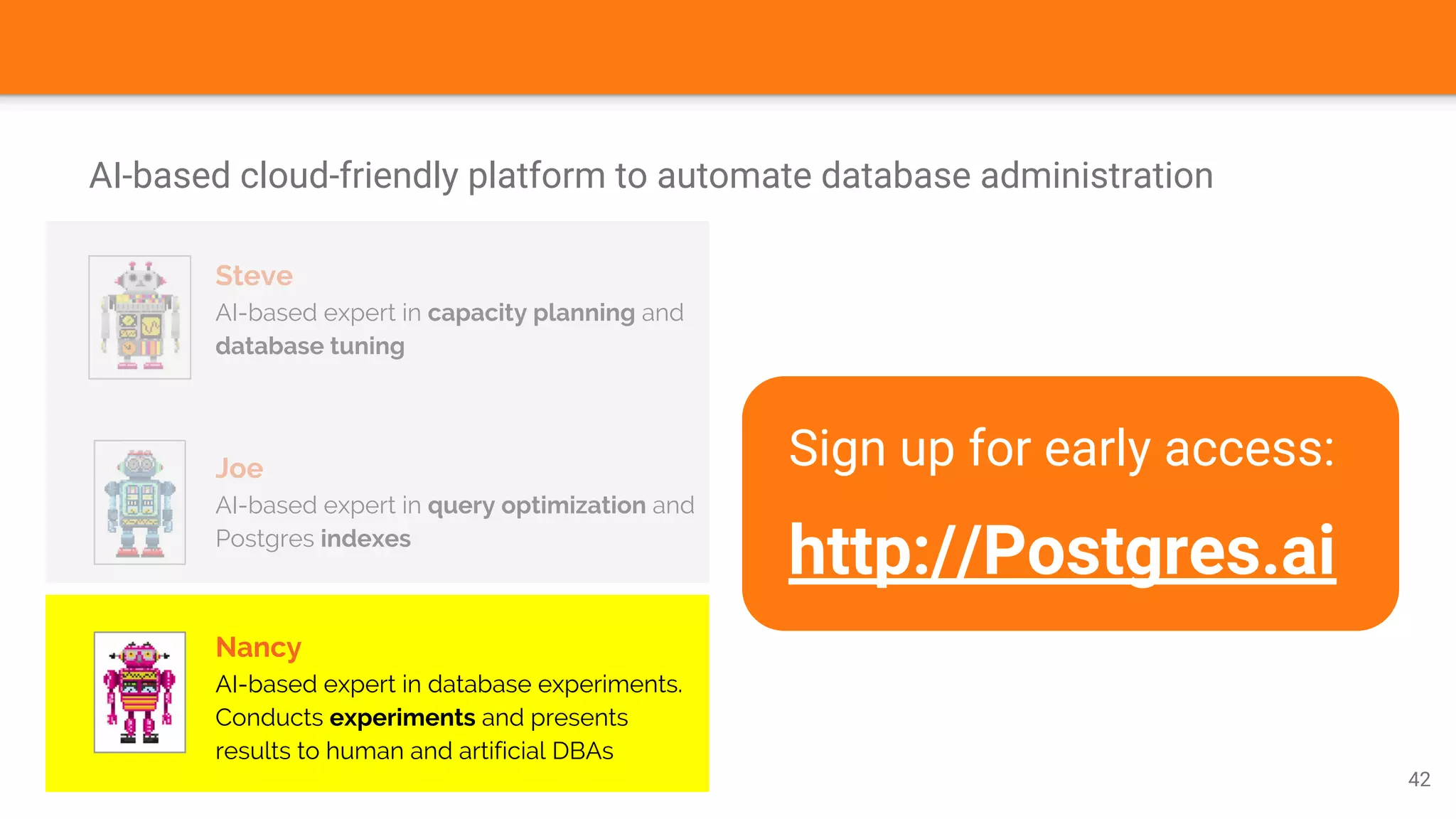
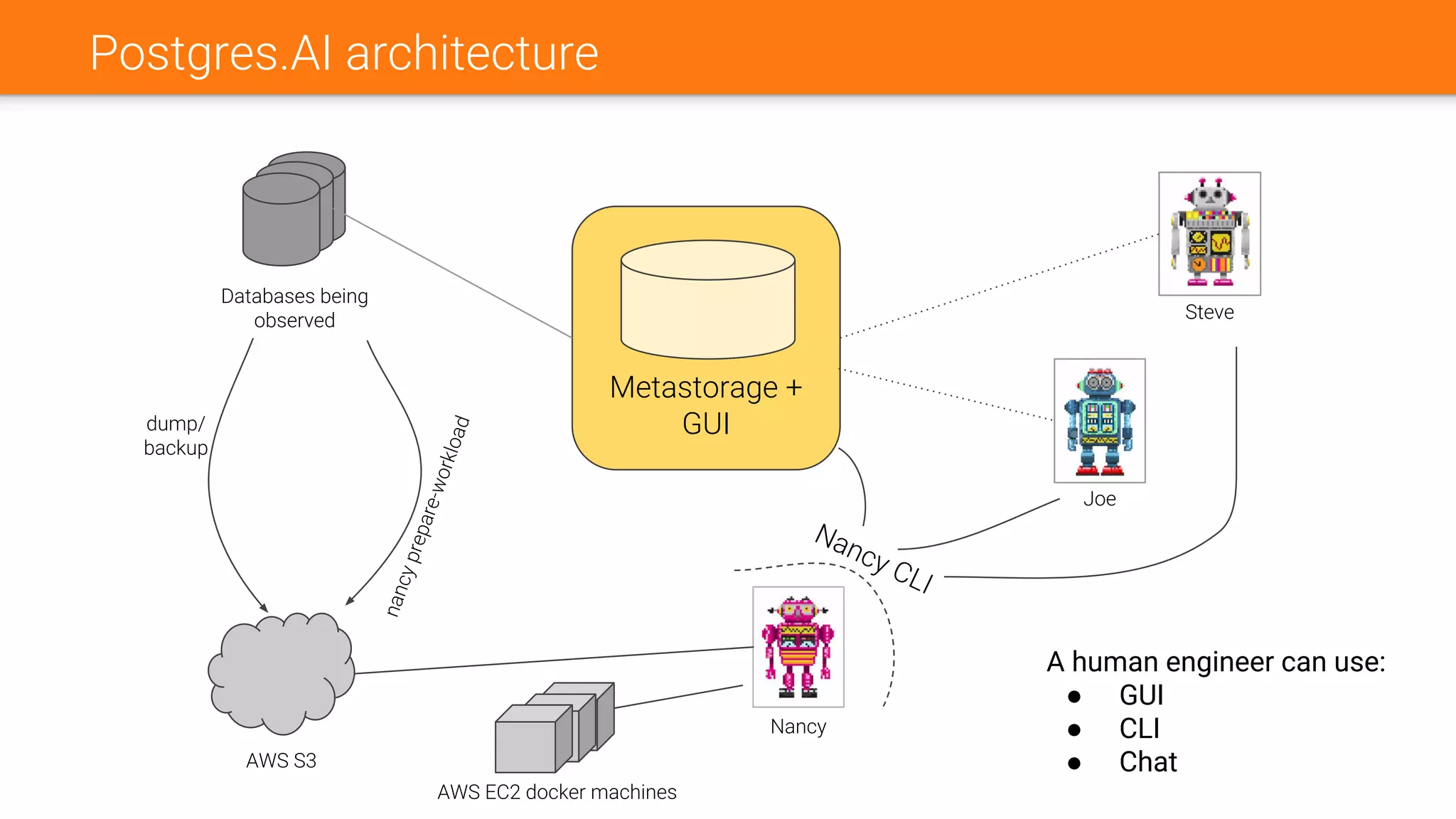

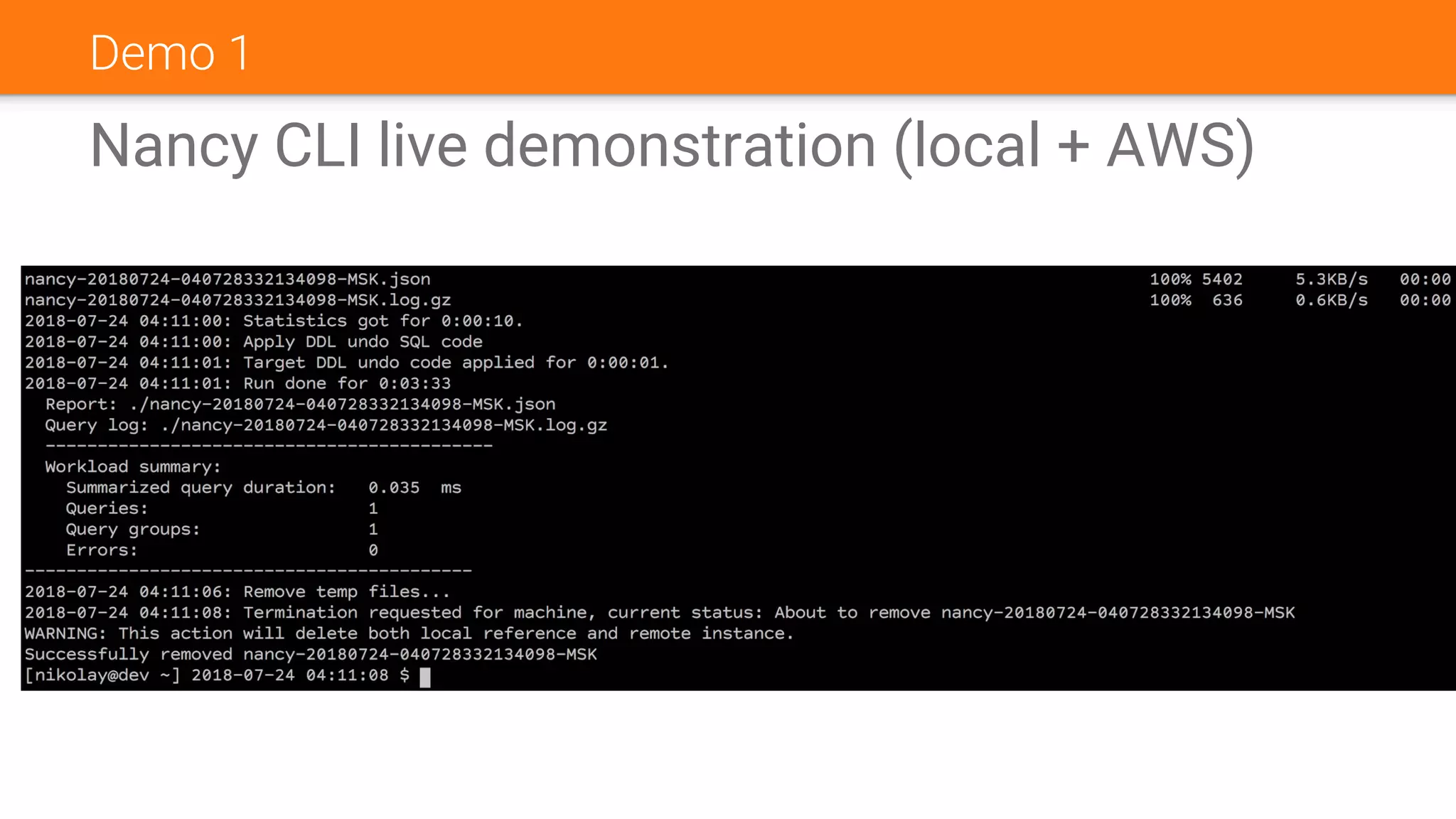









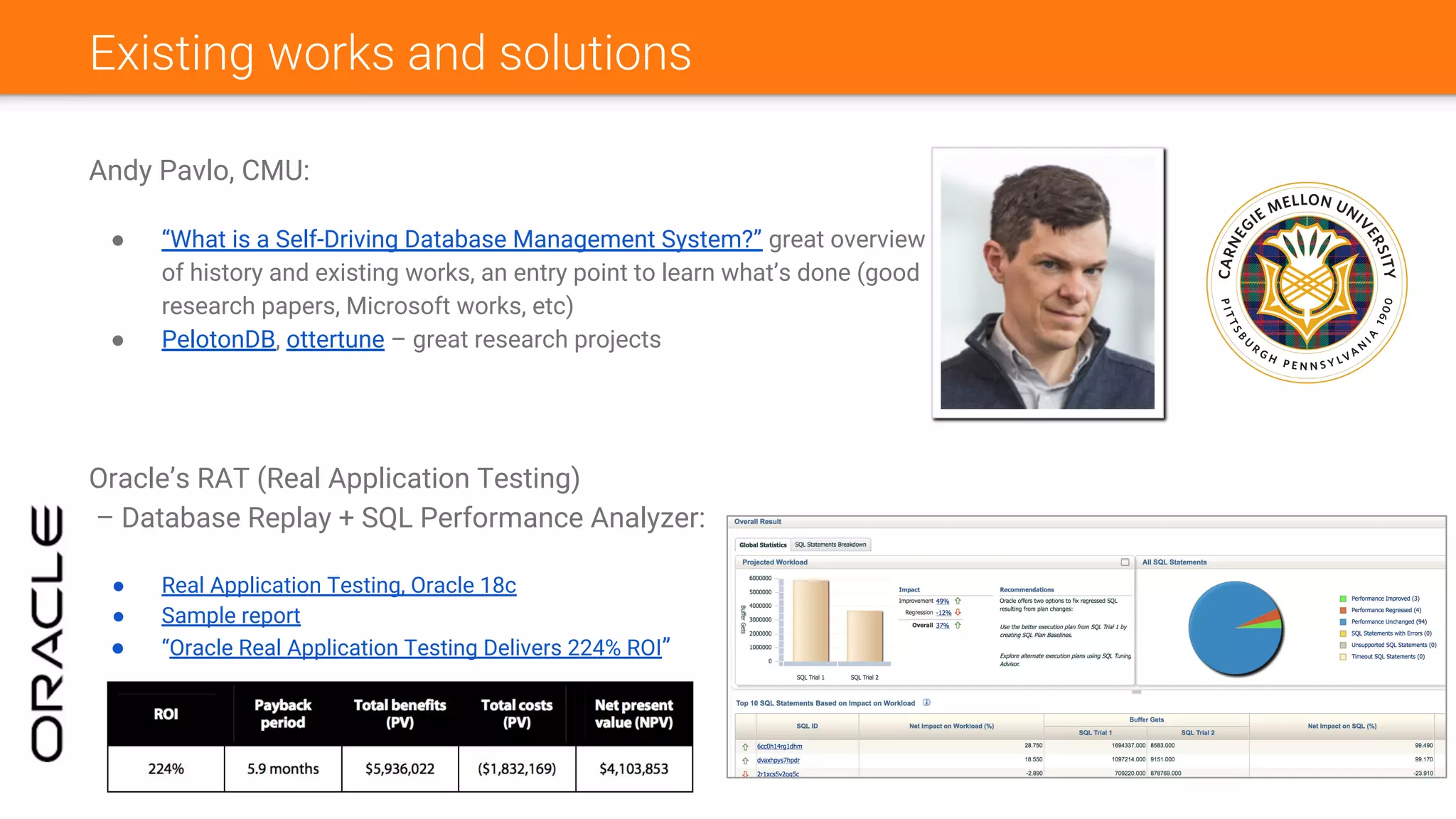
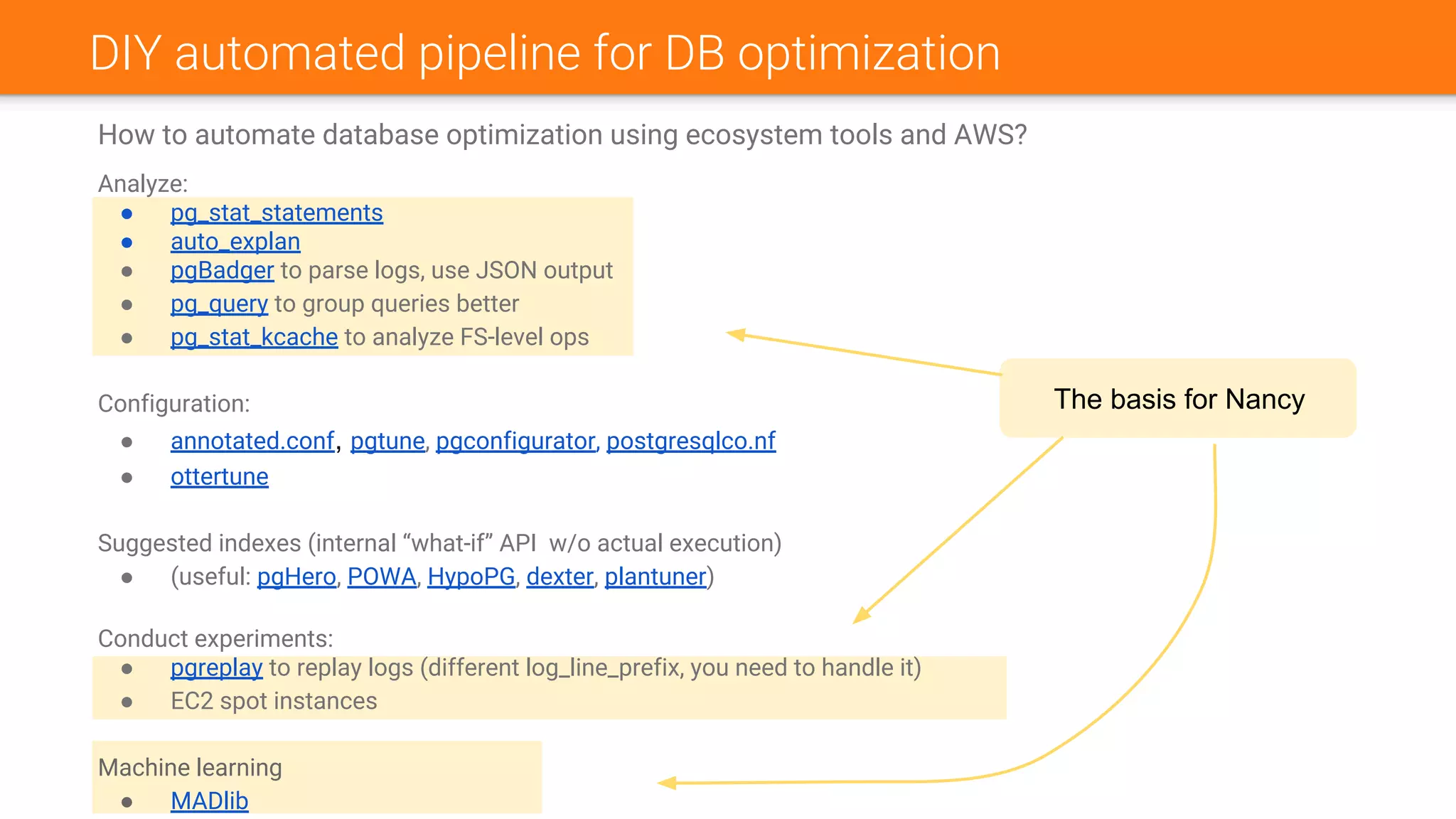
The document discusses Nancy CLI, an automated system for managing database experiments within PostgreSQL environments, highlighting its features including query performance analysis and workload management. It outlines the need for automation in database administration to improve performance and optimize configurations based on experimental data. Existing tools, the development pipeline, and future enhancements for Nancy CLI are also reviewed, emphasizing its potential in continuous database optimization and administration.





![[2B1]검색엔진의 패러다임 전환](https://cdn.slidesharecdn.com/ss_thumbnails/2b1-140929192121-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2D1]Elasticsearch 성능 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/2d1elasticsearch-140929192211-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





![[262] netflix 빅데이터 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/226netflix-150915054913-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

























































![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)
![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)

