Download to read offline



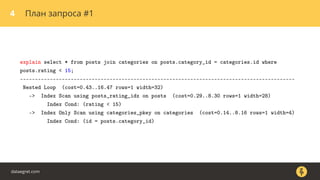
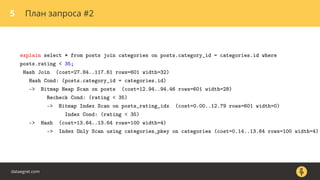
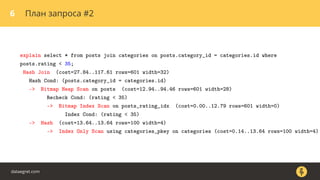

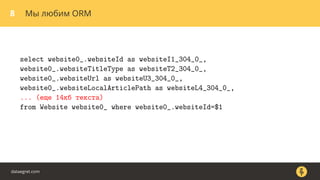






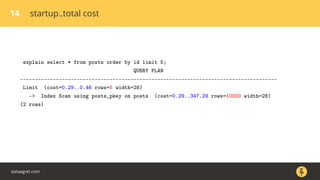
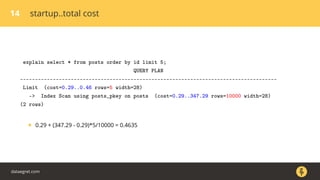

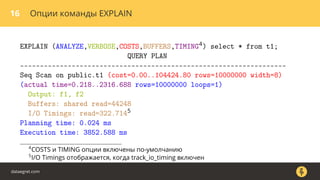
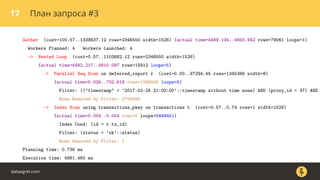
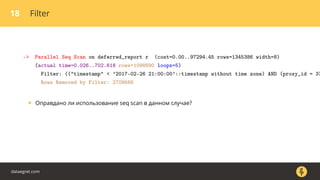
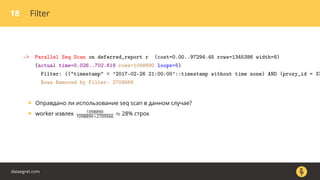
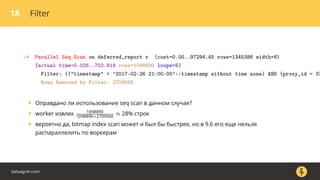






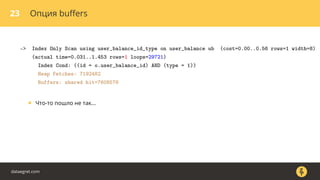




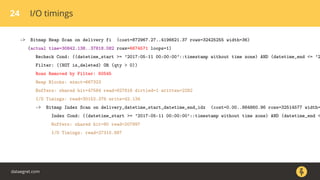
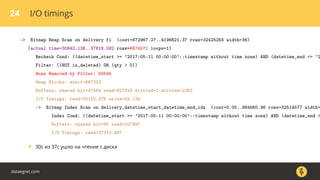
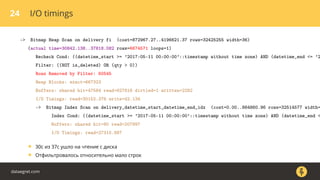


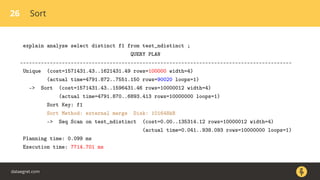
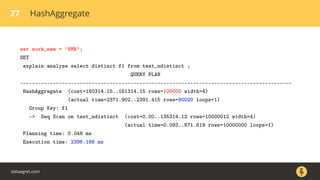
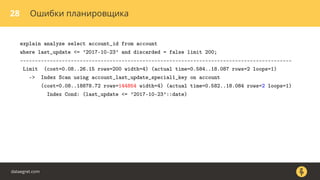

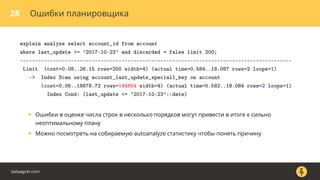





Документ описывает, как использовать команду EXPLAIN для анализа запросов в базе данных, включая различные планы запросов и их оптимизацию. Приводятся примеры различных операций, методов извлечения и соединения данных, а также недочеты, которые могут возникнуть при выполнении запросов. Основное внимание уделяется тому, как правильно интерпретировать результаты EXPLAIN и улучшать производительность запросов.



































































