Download as PDF, PPTX








![URL Hash как решение:
upstream = servers[hash(url) % len(servers)]](https://image.slidesharecdn.com/random-151020102926-lva1-app6892/85/slide-14-320.jpg)

![URL Hash как плохое решение:
upstream = servers[hash(url) % len(servers)]
Если один сервер умирает -- вся система
требует перебалансировки.](https://image.slidesharecdn.com/random-151020102926-lva1-app6892/85/slide-16-320.jpg)

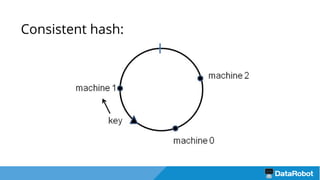
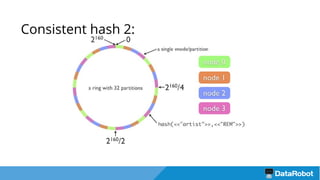



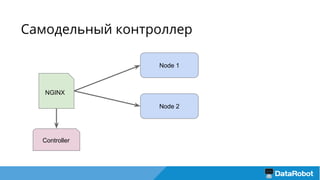








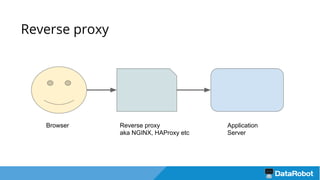
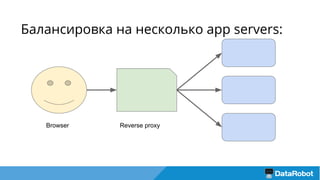
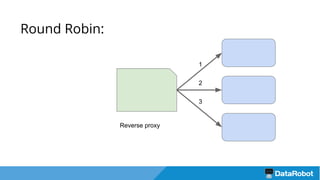
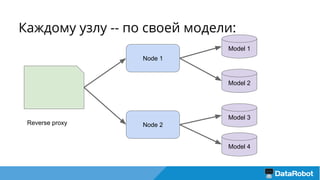
Документ описывает подход к балансировке нагрузки и оптимизации загрузки кластера с использованием Nginx для развертывания приложений, включая решения для обработки статических файлов и безопасности. Также рассматривается проблема загрузки тяжелых моделей и использование хэширования URL для маршрутизации запросов к серверам с уже загруженными моделями. В результате предложенные решения повышают емкость кластера в 4 раза и утилизацию серверов до 75%.










































































