Download as PDF, PPTX


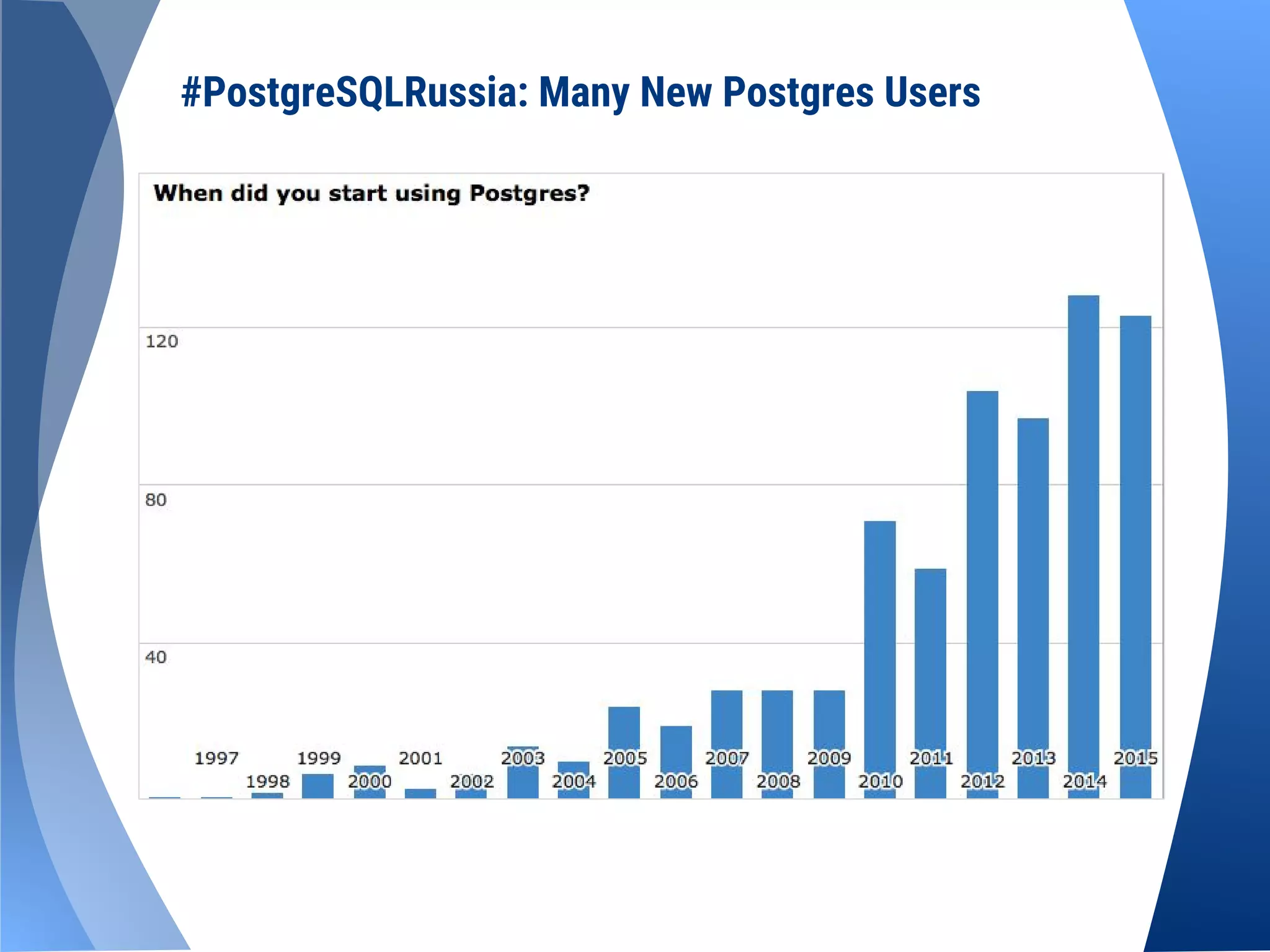
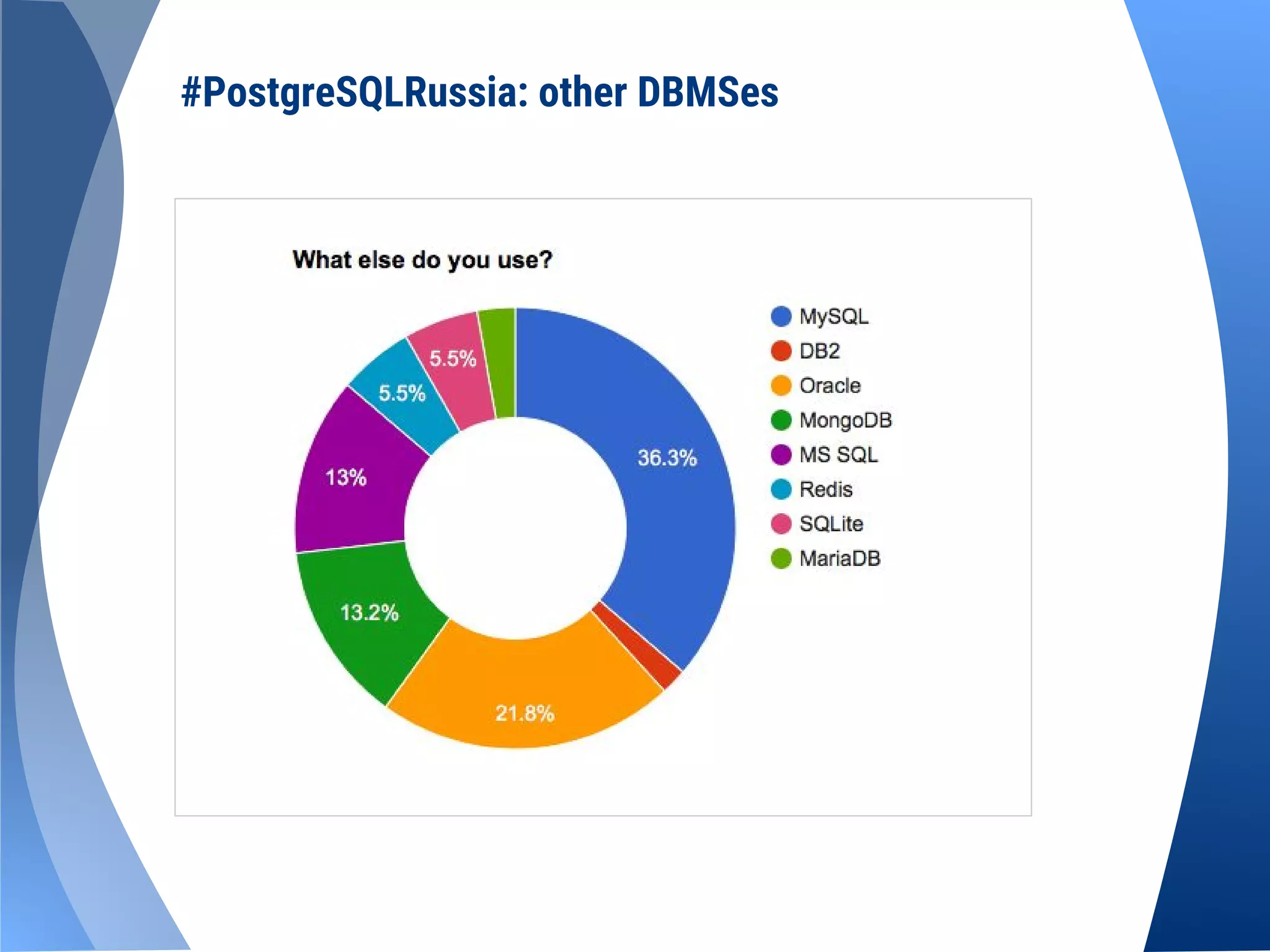



The document provides an overview of the PostgreSQL Russian community, which was founded in 2007 and relaunched in September 2014. It details membership growth, organized meetups, and upcoming conferences in Moscow and Saint Petersburg. It also includes links to the community's website and social media for further engagement.


























































