Download as PDF, PPTX






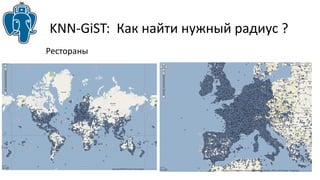








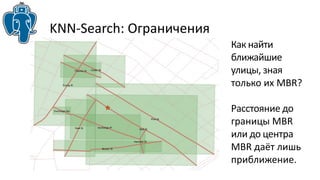

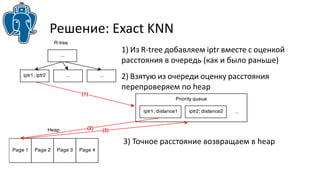












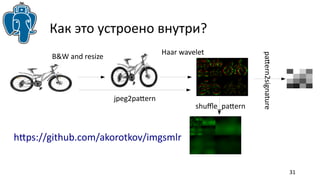

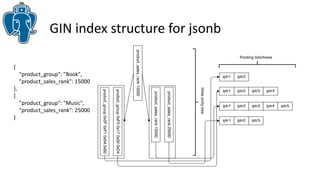

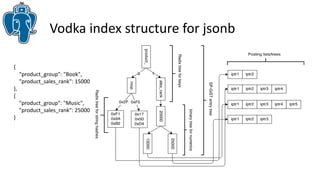


Документ описывает эффективные методы поиска ближайших соседей (k-NN) в PostgreSQL, включая стратегию использования индексов GIST и GIN для улучшения производительности. Приводятся примеры реализации и сравнения результатов использования различных индексов, а также обсуждаются ограничения и архитектурные проблемы, с которыми сталкиваются разработчики. В частности, рассматривается история разработки knn-gist и его применение для поиска по различным типам данных.
























































