Download as PDF, PPTX












![Hashes
A hashes primary job is to represent an object.
Hashes are effectively an associative array. a key contains sets
of key/value pairs.
Due to the way they are stored, hashes are HIGHLY memory efficient.
A few key pairs are less memory efficient than a hash with a few values!
Next time you’re about to json_encode an array, think again!
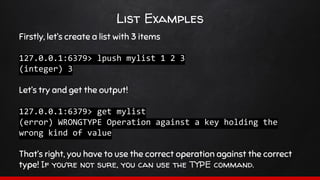
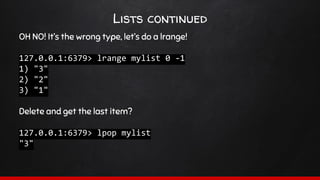
hset <keyname> <hash_key> <value>
A hash therefore could look like this:
user:1000 => [‘name’ => ‘Test User’, ‘address’ => ‘1 test St’]](https://image.slidesharecdn.com/sydphp-magicofredis-151030032726-lva1-app6892/85/SydPHP-The-Magic-of-Redis-16-320.jpg)






















The document discusses Redis, an open-source in-memory data structure store that functions as a database, cache, and message broker, highlighting its speed and data types. It covers key concepts such as persistence, data safety, various data structures like strings, lists, hashes, and sets, and how to optimize performance using techniques like pipelining. Finally, it emphasizes Redis's limitations and its use cases within the context of application development.













































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)

