Download to read offline



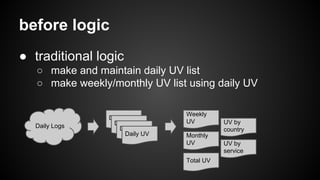


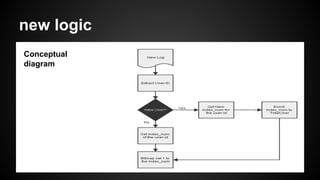
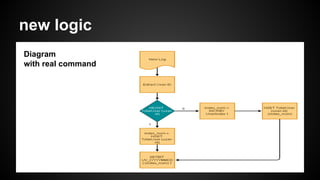






The document outlines a new logic for tracking user visits (UV) using Redis bitmap, which improves upon traditional methods that require large data storage and cannot support real-time analytics. This new approach allows for efficient maintenance of daily UV lists and aggregation using bit operations, resulting in lower memory usage and the ability to retrieve UV data for various periods instantly. Future improvements may include sharding to accommodate increased user counts beyond the current limit of 4 billion.







































