Download to read offline
















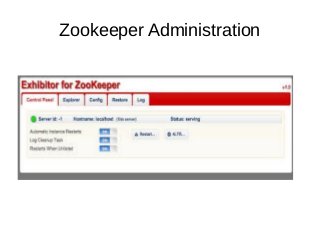


This document outlines a proposed working group structure focused on developing basic Hadoop and Big Data skills. Key areas of focus include: - Managing AWS EC2 instances and automating cluster setup and administration tasks using scripts. - Learning core Hadoop features like HDFS, YARN, and MapReduce by manually running examples and demos in a pseudo-distributed mode and clustered environment. - Setting up and administering Zookeeper, HBase, and other Bigtop components on AWS. - Developing Hadoop data pipelines as proposed by Roman and integrating demo code into testing frameworks. - Choosing career focus areas like DevOps, application development, or internals and efficiently practicing skills through dem





















































