Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
長岡技術科学大学 自然言語処理研究室
PDF, PPTX
560 views
大規模常識知識ベース構築のための常識表現の自動獲得
真嘉比 愛, 山本 和英. 大規模常識知識ベース構築のための常識表現の自動獲得. 言語処理学会第20回年次大会, pp.682-685 (2014.3)
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 44
2
/ 44
3
/ 44
4
/ 44
5
/ 44
6
/ 44
7
/ 44
8
/ 44
9
/ 44
10
/ 44
11
/ 44
12
/ 44
13
/ 44
14
/ 44
15
/ 44
16
/ 44
17
/ 44
18
/ 44
19
/ 44
20
/ 44
21
/ 44
22
/ 44
23
/ 44
24
/ 44
25
/ 44
26
/ 44
27
/ 44
28
/ 44
29
/ 44
30
/ 44
31
/ 44
32
/ 44
33
/ 44
34
/ 44
35
/ 44
36
/ 44
37
/ 44
38
/ 44
39
/ 44
40
/ 44
41
/ 44
42
/ 44
43
/ 44
44
/ 44
More Related Content
PDF
ツライと評判のAndroid BLEを頑張って使い続けた話
by
Kenta Harada
PPTX
Polyphony: Python ではじめる FPGA
by
ryos36
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
自然言語処理による企業の気候変動対策分析
by
Takahiro Kubo
PPTX
オレ流のOpenJDKの開発環境(JJUG CCC 2019 Fall講演資料)
by
NTT DATA Technology & Innovation
PDF
続・PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜 #2
by
Preferred Networks
PPTX
NLPにおけるAttention~Seq2Seq から BERTまで~
by
Takuya Ono
PPTX
Apache Hadoopに見るJavaミドルウェアのcompatibility(Open Developers Conference 2020 Onli...
by
NTT DATA Technology & Innovation
ツライと評判のAndroid BLEを頑張って使い続けた話
by
Kenta Harada
Polyphony: Python ではじめる FPGA
by
ryos36
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
自然言語処理による企業の気候変動対策分析
by
Takahiro Kubo
オレ流のOpenJDKの開発環境(JJUG CCC 2019 Fall講演資料)
by
NTT DATA Technology & Innovation
続・PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜 #2
by
Preferred Networks
NLPにおけるAttention~Seq2Seq から BERTまで~
by
Takuya Ono
Apache Hadoopに見るJavaミドルウェアのcompatibility(Open Developers Conference 2020 Onli...
by
NTT DATA Technology & Innovation
What's hot
PDF
OSS+AWSでここまでできるDevSecOps (Security-JAWS第24回)
by
Masaya Tahara
PPTX
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
PDF
iostatの見方
by
Yohei Azekatsu
PDF
20180729 Preferred Networksの機械学習クラスタを支える技術
by
Preferred Networks
PDF
分散ストレージソフトウェアCeph・アーキテクチャー概要
by
Etsuji Nakai
PDF
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
PDF
CDNの仕組み(JANOG36)
by
J-Stream Inc.
PDF
分解のススメ 第14回 ローエンド中BT Audio SoC華BT Audio SoCLowEndChineseBTAudioSoC.pdf
by
Masawo Yamazaki
PDF
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
PPTX
Neko kin
by
Shota Okubo
PDF
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
PPTX
大規模微服務導入 - #1, 從零開始的系統架構設計概觀
by
Andrew Wu
PDF
GOの機械学習システムを支えるMLOps事例紹介
by
Takashi Suzuki
PDF
katagaitai CTF勉強会 #5 Crypto
by
trmr
PPTX
Hive on Spark の設計指針を読んでみた
by
Recruit Technologies
PDF
東大大学院 戦略ソフトウェア特論2021「ロボットで世界を計算可能にする」海野裕也
by
Preferred Networks
PDF
脆弱性スキャナVuls(応用編)
by
Takayuki Ushida
PPTX
root権限無しでKubernetesを動かす
by
Akihiro Suda
PPTX
katagaitai CTF勉強会 #3 crypto
by
trmr
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
OSS+AWSでここまでできるDevSecOps (Security-JAWS第24回)
by
Masaya Tahara
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
iostatの見方
by
Yohei Azekatsu
20180729 Preferred Networksの機械学習クラスタを支える技術
by
Preferred Networks
分散ストレージソフトウェアCeph・アーキテクチャー概要
by
Etsuji Nakai
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
CDNの仕組み(JANOG36)
by
J-Stream Inc.
分解のススメ 第14回 ローエンド中BT Audio SoC華BT Audio SoCLowEndChineseBTAudioSoC.pdf
by
Masawo Yamazaki
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
Neko kin
by
Shota Okubo
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
大規模微服務導入 - #1, 從零開始的系統架構設計概觀
by
Andrew Wu
GOの機械学習システムを支えるMLOps事例紹介
by
Takashi Suzuki
katagaitai CTF勉強会 #5 Crypto
by
trmr
Hive on Spark の設計指針を読んでみた
by
Recruit Technologies
東大大学院 戦略ソフトウェア特論2021「ロボットで世界を計算可能にする」海野裕也
by
Preferred Networks
脆弱性スキャナVuls(応用編)
by
Takayuki Ushida
root権限無しでKubernetesを動かす
by
Akihiro Suda
katagaitai CTF勉強会 #3 crypto
by
trmr
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
Viewers also liked
PPTX
GPUによる多倍長整数乗算の高速化手法の提案とその評価
by
Koji Kitano
PDF
Visualizing and understanding neural models in NLP
by
Naoaki Okazaki
PDF
研究室における研究・実装ノウハウの共有
by
Naoaki Okazaki
PDF
第1回 「めまい」
by
清水 真人
PDF
Evernote, feedlyで簡単知識整理術!
by
清水 真人
PDF
深層ニューラルネットワーク による知識の自動獲得・推論
by
Naoaki Okazaki
PPTX
汎用人工知能の研究動向
by
Naoya Arakawa
PDF
企業における自然言語処理技術利用の最先端
by
Yuya Unno
PDF
企業における自然言語処理技術の活用の現場(情報処理学会東海支部主催講演会@名古屋大学)
by
Yuya Unno
PDF
言語と知識の深層学習@認知科学会サマースクール
by
Yuya Unno
PDF
機械学習チュートリアル@Jubatus Casual Talks
by
Yuya Unno
PDF
機械学習によるデータ分析まわりのお話
by
Ryota Kamoshida
PDF
深層学習時代の自然言語処理
by
Yuya Unno
GPUによる多倍長整数乗算の高速化手法の提案とその評価
by
Koji Kitano
Visualizing and understanding neural models in NLP
by
Naoaki Okazaki
研究室における研究・実装ノウハウの共有
by
Naoaki Okazaki
第1回 「めまい」
by
清水 真人
Evernote, feedlyで簡単知識整理術!
by
清水 真人
深層ニューラルネットワーク による知識の自動獲得・推論
by
Naoaki Okazaki
汎用人工知能の研究動向
by
Naoya Arakawa
企業における自然言語処理技術利用の最先端
by
Yuya Unno
企業における自然言語処理技術の活用の現場(情報処理学会東海支部主催講演会@名古屋大学)
by
Yuya Unno
言語と知識の深層学習@認知科学会サマースクール
by
Yuya Unno
機械学習チュートリアル@Jubatus Casual Talks
by
Yuya Unno
機械学習によるデータ分析まわりのお話
by
Ryota Kamoshida
深層学習時代の自然言語処理
by
Yuya Unno
Similar to 大規模常識知識ベース構築のための常識表現の自動獲得
PDF
大規模常識知識ベース構築のための常識表現の自動獲得
by
長岡技術科学大学 自然言語処理研究室
PDF
大規模常識知識ベース構築のための常識表現の自動獲得
by
長岡技術科学大学 自然言語処理研究室
PDF
常識表現となり得る用言の自動選定の検討
by
長岡技術科学大学 自然言語処理研究室
PDF
Jsai2021 winter ppt_ota_20211127
by
博三 太田
PDF
論文紹介:WWWからの大規模動詞含意知識の獲得
by
swenbe
PPTX
Nl237 presentation
by
Roy Ray
PDF
NLP2012
by
Yuki Nakayama
PDF
CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multipl...
by
禎晃 山崎
PPTX
2012 09-25-sig-ifat
by
Asahara Masayuki
PDF
OWLで何が書けるか
by
Kazuro Fukuhara
PPTX
dont_count_predict_in_acl2014
by
Sho Takase
PDF
専門用語を対象とした語彙数推定テストの開発とその信頼性の評価:図書館情報学分野を事例として
by
ssuser9a82681
PDF
テキストデータの理論的サンプリング
by
Naohiro Matsumura
PDF
Tutorial2015 tomida
by
Eiji Tomida
PDF
Rm20150715 12key
by
youwatari
PPTX
Mtg121024
by
Kosuke Kagawa
PDF
文法性判断課題における反応時間と主観的測度は正答率を予測するか:文法項目の違いに焦点をあてて
by
Yu Tamura
PDF
Computer-based Method for Association Response in Autonomous Conversation
by
E-musu
PPTX
Graduation thesis
by
Roy Ray
PDF
サブカルのためのWord2vec
by
DeNA
大規模常識知識ベース構築のための常識表現の自動獲得
by
長岡技術科学大学 自然言語処理研究室
大規模常識知識ベース構築のための常識表現の自動獲得
by
長岡技術科学大学 自然言語処理研究室
常識表現となり得る用言の自動選定の検討
by
長岡技術科学大学 自然言語処理研究室
Jsai2021 winter ppt_ota_20211127
by
博三 太田
論文紹介:WWWからの大規模動詞含意知識の獲得
by
swenbe
Nl237 presentation
by
Roy Ray
NLP2012
by
Yuki Nakayama
CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multipl...
by
禎晃 山崎
2012 09-25-sig-ifat
by
Asahara Masayuki
OWLで何が書けるか
by
Kazuro Fukuhara
dont_count_predict_in_acl2014
by
Sho Takase
専門用語を対象とした語彙数推定テストの開発とその信頼性の評価:図書館情報学分野を事例として
by
ssuser9a82681
テキストデータの理論的サンプリング
by
Naohiro Matsumura
Tutorial2015 tomida
by
Eiji Tomida
Rm20150715 12key
by
youwatari
Mtg121024
by
Kosuke Kagawa
文法性判断課題における反応時間と主観的測度は正答率を予測するか:文法項目の違いに焦点をあてて
by
Yu Tamura
Computer-based Method for Association Response in Autonomous Conversation
by
E-musu
Graduation thesis
by
Roy Ray
サブカルのためのWord2vec
by
DeNA
More from 長岡技術科学大学 自然言語処理研究室
PDF
小学生の読解支援に向けた複数の換言知識を併用した語彙平易化と評価
by
長岡技術科学大学 自然言語処理研究室
PDF
小学生の読解支援に向けた語釈文から語彙的換言を選択する手法
by
長岡技術科学大学 自然言語処理研究室
PDF
Selecting Proper Lexical Paraphrase for Children
by
長岡技術科学大学 自然言語処理研究室
PDF
Automatic Selection of Predicates for Common Sense Knowledge Expression
by
長岡技術科学大学 自然言語処理研究室
PDF
用言等換言辞書を用いた換言結果の考察
by
長岡技術科学大学 自然言語処理研究室
PDF
用言等換言辞書の構築
by
長岡技術科学大学 自然言語処理研究室
PDF
質問意図によるQAサイト質問文の自動分類
by
長岡技術科学大学 自然言語処理研究室
PDF
役所からの公的文書に対する「やさしい日本語」への変換システムの構築
by
長岡技術科学大学 自然言語処理研究室
PDF
対訳コーパスから生成したワードグラフによる部分的機械翻訳
by
長岡技術科学大学 自然言語処理研究室
PDF
用言等換言辞書を人手で作りました
by
長岡技術科学大学 自然言語処理研究室
PDF
文字列の出現頻度情報を用いた分かち書き単位の自動取得
by
長岡技術科学大学 自然言語処理研究室
PDF
「やさしい日本語」変換システムの試作
by
長岡技術科学大学 自然言語処理研究室
PDF
常識表現となり得る用言の自動選定の検討
by
長岡技術科学大学 自然言語処理研究室
PDF
動詞意味類型の曖昧性解消に向けた格フレーム情報との関連調査
by
長岡技術科学大学 自然言語処理研究室
PDF
二格深層格の定量的分析
by
長岡技術科学大学 自然言語処理研究室
PDF
文脈の多様性に基づく名詞換言の提案
by
長岡技術科学大学 自然言語処理研究室
PDF
保険関連文書を対象とした文章校正支援のための変換誤り検出
by
長岡技術科学大学 自然言語処理研究室
PDF
Developing User-friendly and Customizable Text Analyzer
by
長岡技術科学大学 自然言語処理研究室
PDF
普通名詞換言辞書の構築
by
長岡技術科学大学 自然言語処理研究室
PDF
普通名詞換言辞書の構築
by
長岡技術科学大学 自然言語処理研究室
小学生の読解支援に向けた複数の換言知識を併用した語彙平易化と評価
by
長岡技術科学大学 自然言語処理研究室
小学生の読解支援に向けた語釈文から語彙的換言を選択する手法
by
長岡技術科学大学 自然言語処理研究室
Selecting Proper Lexical Paraphrase for Children
by
長岡技術科学大学 自然言語処理研究室
Automatic Selection of Predicates for Common Sense Knowledge Expression
by
長岡技術科学大学 自然言語処理研究室
用言等換言辞書を用いた換言結果の考察
by
長岡技術科学大学 自然言語処理研究室
用言等換言辞書の構築
by
長岡技術科学大学 自然言語処理研究室
質問意図によるQAサイト質問文の自動分類
by
長岡技術科学大学 自然言語処理研究室
役所からの公的文書に対する「やさしい日本語」への変換システムの構築
by
長岡技術科学大学 自然言語処理研究室
対訳コーパスから生成したワードグラフによる部分的機械翻訳
by
長岡技術科学大学 自然言語処理研究室
用言等換言辞書を人手で作りました
by
長岡技術科学大学 自然言語処理研究室
文字列の出現頻度情報を用いた分かち書き単位の自動取得
by
長岡技術科学大学 自然言語処理研究室
「やさしい日本語」変換システムの試作
by
長岡技術科学大学 自然言語処理研究室
常識表現となり得る用言の自動選定の検討
by
長岡技術科学大学 自然言語処理研究室
動詞意味類型の曖昧性解消に向けた格フレーム情報との関連調査
by
長岡技術科学大学 自然言語処理研究室
二格深層格の定量的分析
by
長岡技術科学大学 自然言語処理研究室
文脈の多様性に基づく名詞換言の提案
by
長岡技術科学大学 自然言語処理研究室
保険関連文書を対象とした文章校正支援のための変換誤り検出
by
長岡技術科学大学 自然言語処理研究室
Developing User-friendly and Customizable Text Analyzer
by
長岡技術科学大学 自然言語処理研究室
普通名詞換言辞書の構築
by
長岡技術科学大学 自然言語処理研究室
普通名詞換言辞書の構築
by
長岡技術科学大学 自然言語処理研究室
大規模常識知識ベース構築のための常識表現の自動獲得
1.
大規模常識知識ベース構築の ための常識表現の自動獲得 長岡技術科学大学
電気系 真嘉比 愛,山本 和英
2.
研究の背景 1/2 言葉の意味を理解するコンピュータの実現
– 言語の文法的知識 – 大量の常識 e.g. 会話応答システム 愛犬と遊んでいました 犬を飼っているの ですか? 可愛いですか? → 愛犬とは 1 飼い犬のことである → 愛犬は 可愛がられている
3.
研究の背景 1/2 言葉の意味を理解するコンピュータの実現
– 言語の文法的知識 – 大量の常識 e.g. 会話応答システム 愛犬と遊んでいました 犬を飼っているの ですか? 可愛いですか? → 愛犬とは 1 飼い犬のことである → 愛犬は 可愛がられている 多くの研究者が注目: -‐ 大量の常識を収集した常識知識ベースを 構築する研究 -‐ 常識知識ベースを自然言語処理のタスクで 利用しやすい形で提供する研究
4.
関連研究 • 既存の上位オントロジー(e.g.
CYC, SUMO) – 多くの一般的な概念を含むオントロジー – 厳密に定義された常識を利用できるが,知識表 現が実際の言語表現に対応出来ない • ConceptNet(常識知識ベース) – 単語や短い文で常識を定義しており,自然言語 処理タスクでの利用が容易 – 常識の大半が人手で集められており,網羅性が 低い(日本語版:14,546) 2
5.
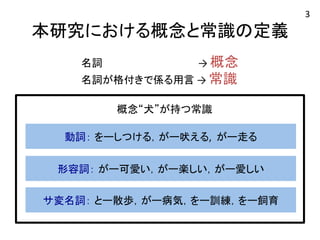
本研究における概念と常識の定義 名詞 →
概念 名詞が格付きで係る用言 → 常識 概念“犬”が持つ常識 動詞: をーしつける,がー吠える, がー走る 形容詞: がー可愛い,がー楽しい,がー愛しい サ変名詞: とー散歩,がー病気,をー訓練,をー飼育 3
6.
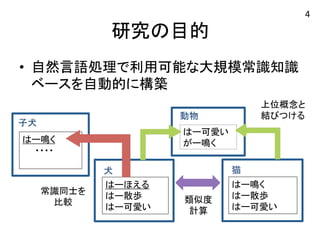
研究の目的 • 自然言語処理で利用可能な大規模常識知識
ベースを自動的に構築 猫 はー鳴く はー散歩 はー可愛い 動物 はー可愛い がー鳴く 類似度 計算 子犬 はー鳴く ・・・・ 犬 はーほえる はー散歩 はー可愛い 常識同士を 比較 4 上位概念と 結びつける
7.
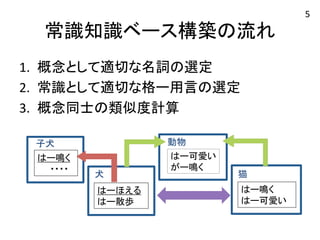
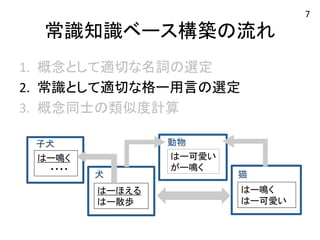
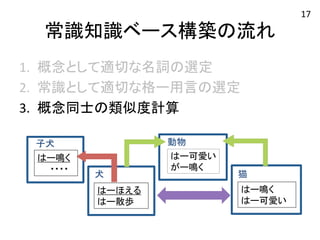
常識知識ベース構築の流れ 1. 概念として適切な名詞の選定
2. 常識として適切な格ー用言の選定 3. 概念同士の類似度計算 猫 はー鳴く はー可愛い 子犬 動物 はー鳴く はー可愛い がー鳴く ・・・・ 犬 はーほえる はー散歩 5
8.
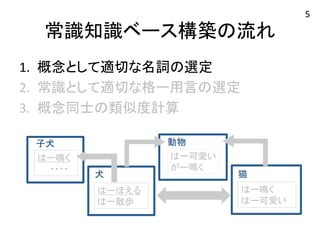
常識知識ベース構築の流れ 1. 概念として適切な名詞の選定
2. 常識として適切な格ー用言の選定 3. 概念同士の類似度計算 猫 はー鳴く はー可愛い 子犬 動物 はー鳴く はー可愛い がー鳴く ・・・・ 犬 はーほえる はー散歩 5
9.
概念として適切な名詞の選定 • 日本語語彙大系中で“名詞-‐具体”に分類され
る名詞12,042語 – 名詞-‐具体 • 道路,犬,団扇,シリンダー 等 6 格-‐用言の組で特徴付けが 難しい“名詞-‐抽象”を除外
10.
常識知識ベース構築の流れ 1. 概念として適切な名詞の選定
2. 常識として適切な格ー用言の選定 3. 概念同士の類似度計算 猫 はー鳴く はー可愛い 子犬 動物 はー鳴く はー可愛い がー鳴く ・・・・ 犬 はーほえる はー散歩 7
11.
常識のもつ性質についての仮説 • 特定の概念が高頻度で係る用言は,その概
念の常識として適切である – E.g. 「道路を横断する」が高い頻度で出現 → 「をー横断」は「道路」の常識 • 多くの概念が係る用言(=汎用的に利用され る用言)は常識として不適切である – E.g. 「道路」に対する「をー使う」 • 用言が概念の常識として適切か否かは,概 念が係る用言数に依存する 8
12.
常識のもつ性質についての仮説 • 特定の概念が高頻度で係る用言は,その概
念の常識として適切である – E.g. 「道路を横断する」が高い頻度で出現 → 「をー横断」は「道路」の常識 • 多くの概念が係る用言(=汎用的に利用され る用言)は常識として不適切である – E.g. 「道路」に対する「をー使う」 • 用言が概念の常識として適切か否かは,概 念が係る用言数に依存する 8
13.
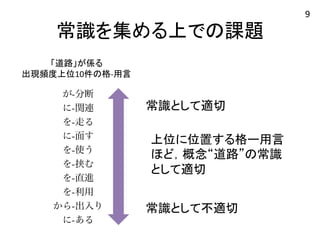
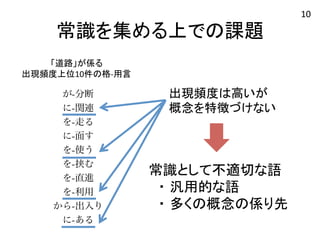
常識を集める上での課題 与される用言の違い(スコア順上位10 件)
名詞:道路 案手法ベースライン1 ベースライン2 提案手法 生き抜くが-分断が-分断が-分断 -起こるに-関連に-関連を-走る に-存在を-走るを-走るに-面す -広めるに-面すに-面すを-挟む に-必要を-使うを-使うを-直進 送り出すを-挟むを-挟むから-出入り 役に立つを-直進を-直進に-接す -役立つを-利用を-利用を-横断 に-貢献から-出入りから-出入りを-渡る -動かすに-あるに-接すが-整備 上位に位置する格ー用言 ほど,概念“道路”の常識 として適切 名詞:議員 「道路」が係る 出現頻度上位10件の格-‐用言 常識として適切 常識として不適切 9
14.
常識を集める上での課題 与される用言の違い(スコア順上位10 件)
名詞:道路 案手法ベースライン1 ベースライン2 提案手法 生き抜くが-分断が-分断が-分断 -起こるに-関連に-関連を-走る に-存在を-走るを-走るに-面す -広めるに-面すに-面すを-挟む に-必要を-使うを-使うを-直進 送り出すを-挟むを-挟むから-出入り 役に立つを-直進を-直進に-接す -役立つを-利用を-利用を-横断 に-貢献から-出入りから-出入りを-渡る -動かすに-あるに-接すが-整備 名詞:議員 「道路」が係る 出現頻度上位10件の格-‐用言 出現頻度は高いが 概念を特徴づけない 常識として不適切な語 ・ 汎用的な語 ・ 多くの概念の係り先 10
15.
常識のもつ性質についての仮説 • 特定の概念が高頻度で係る用言は,その概
念の常識として適切である – E.g. 「道路を横断する」が高い頻度で出現 → 「をー横断」は「道路」の常識 • 多くの概念が係る用言(=汎用的に利用され る用言)は常識として不適切である – E.g. 「道路」に対する「をー使う」 • 用言が概念の常識として適切か否かは,概 念が係る用言数に依存する 11
16.
常識のもつ性質についての仮説 • 特定の概念が高頻度で係る用言は,その概
念の常識として適切である – E.g. 「道路を横断する」が高い頻度で出現 → 「をー横断」は「道路」の常識 • 多くの概念が係る用言(=汎用的に利用され る用言)は常識として不適切である – E.g. 「道路」に対する「をー使う」 • 用言が概念の常識として適切か否かは,概 念が係る用言数に依存する 集めた常識集合の中から除外 11
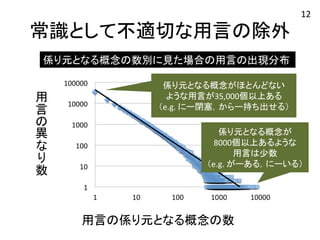
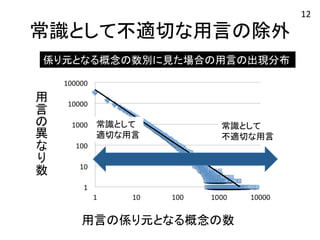
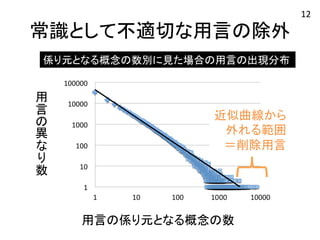
17.
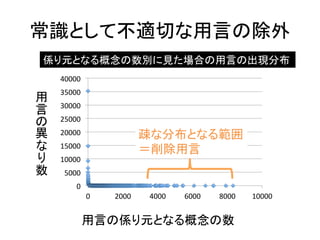
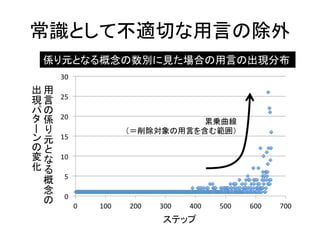
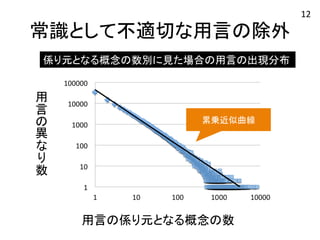
常識として不適切な用言の除外 係り元となる概念の数別に見た場合の用言の出現分布 用
言 叏異 友 叫数 用言の係り元となる概念の数 12 累乗近似曲線
18.
常識として不適切な用言の除外 係り元となる概念の数別に見た場合の用言の出現分布 用
言 叏異 友 叫数 係り元となる概念がほとんどない ような用言が35,000個以上ある (e.g. にー閉塞,からー持ち出せる) 係り元となる概念が 8000個以上あるような 用言は少数 (e.g. がーある,にーいる) 用言の係り元となる概念の数 12
19.
常識として不適切な用言の除外 係り元となる概念の数別に見た場合の用言の出現分布 用
言 叏異 友 叫数 常識として 適切な用言 常識として 不適切な用言 用言の係り元となる概念の数 12
20.
常識として不適切な用言の除外 係り元となる概念の数別に見た場合の用言の出現分布 近似曲線から
外れる範囲 =削除用言 用 言 叏異 友 叫数 用言の係り元となる概念の数 12
21.
常識のもつ性質についての仮説 • 特定の概念が高頻度で係る用言は,その概
念の常識として適切である – E.g. 「道路を横断する」が高い頻度で出現 → 「をー横断」は「道路」の常識 • 多くの概念が係る用言(=汎用的に利用され る用言)は常識として不適切である – E.g. 「道路」に対する「をー使う」 • 用言が概念の常識として適切か否かは,概 念が係る用言数に依存する 13
22.
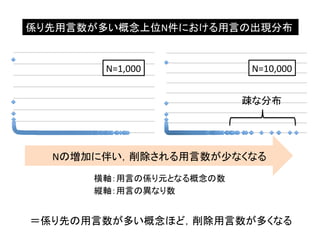
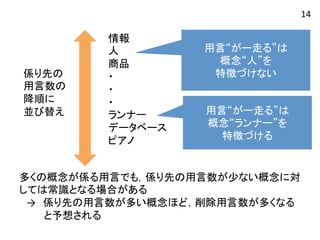
係り先の 用言数の 降順に
並び替え 情報 人 商品 ・ ・ ・ ランナー データベース ピアノ 用言“がー走る”は 概念“人”を 特徴づけない 用言“がー走る”は 概念“ランナー”を 特徴づける 14 多くの概念が係る用言でも,係り先の用言数が少ない概念に対 しては常識となる場合がある → 係り先の用言数が多い概念ほど,削除用言数が多くなる と予想される
23.
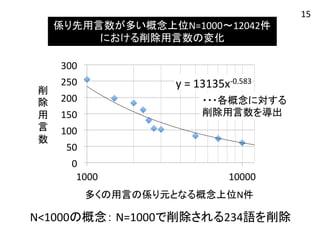
係り先用言数が多い概念上位N=1000〜12042件 における削除用言数の変化 y
= 13135x-‐0.583 300 250 200 150 100 50 0 ・・・各概念に対する 削除用言数を導出 1000 10000 削 除 用 言 数 多くの用言の係り元となる概念上位N件 N<1000の概念: N=1000で削除される234語を削除 15
24.
用言の選定結果 「道路」に付与される 上位10件の常識
言の違い(スコア順上位10 件) 付与される用言の違い(スコア順上位10 件) ベースライン: 頻度情報のみを用いる手法 提案手法: 統計的情報を用いて常識として 不適切な用言を削除する手法 名詞:道路 名詞:道路 ースライン1 2 提案手法 が-分断が-分断 に関連を-走る を-走るに-面す 提案手法ベースライン1 ベースライン2 提案手法 を-生き抜くが-分断が-分断が-分断 で-起こるに-関連に-関連を-走る に-存在を-走るを-走るに-面す に-広めるに-面すに-面すを-挟む に-必要を-使うを-使うを-直進 に-送り出すを-挟むを-挟むから-出入り の-役に立つを-直進を-直進に-接す に-役立つを-利用を-利用を-横断 に-貢献から-出入りから-出入りを-渡る を-動かすに-あるに-接すが-整備 面すを-挟む を-使うを-直進 を-挟むから-出入り を-直進に-接す を利用を-横断 から-出入りを-渡る にある接すが-整備 名詞:議員 名詞:議員 ースライン1 2 提案手法 に-なるに-当選 が-いるに-立候補 に当選から反対 に-立候補が提出 となるが著作 提案手• 法ベースライン1 ベースライン2 提案手法 を-飼うに-なるに-なるに-当選 が-死ぬが-いるが-いるに-立候補 と-暮らすに-当選に-当選から-反対 を-連れるに-立候補に-立候補が-提出 が大好きとなるとなるが著作 “にー関連”,“をー使う”といった汎用的な用言を削除 • “をー横断”,“をー渡る”といった頻度が高くてかつ常識とな る用言が上位に位置 16
25.
常識知識ベース構築の流れ 1. 概念として適切な名詞の選定
2. 常識として適切な格ー用言の選定 3. 概念同士の類似度計算 猫 はー鳴く はー可愛い 子犬 動物 はー鳴く はー可愛い がー鳴く ・・・・ 犬 はーほえる はー散歩 17
26.
概念間に現れる性質についての仮説 • 概念対が類似している場合,両者に付与され
る常識集合同士も類似している • 概念c1と概念c2が類似しており,かつ概念c2 と概念c3も類似している場合は,概念c1と概 念c3もまた類似している(推移律) 18
27.
概念間に現れる性質についての仮説 • 概念対が類似している場合,両者に付与され
る常識集合同士も類似している • 概念c1と概念c2が類似しており,かつ概念c2 と概念c3も類似している場合は,概念c1と概 念c3もまた類似している(推移律) 18
28.
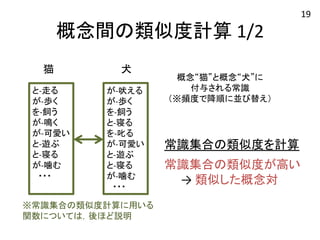
概念間の類似度計算 1/2 猫
犬 と-‐走る が-‐歩く を-‐飼う が-‐鳴く が-‐可愛い と-‐遊ぶ と-‐寝る が-‐噛む ・・・ が-‐吠える が-‐歩く を-‐飼う と-‐寝る を-‐叱る が-‐可愛い と-‐遊ぶ と-‐寝る が-‐噛む ・・・ 概念“猫”と概念“犬”に 付与される常識 (※頻度で降順に並び替え) 常識集合の類似度を計算 常識集合の類似度が高い → 類似した概念対 ※常識集合の類似度計算に用いる 関数については,後ほど説明 19
29.
概念間に現れる性質についての仮説 • 概念対が類似している場合,両者に付与され
る常識集合同士も類似している • 概念c1と概念c2が類似しており,かつ概念c2 と概念c3も類似している場合は,概念c1と概 念c3もまた類似している(推移律) 20
30.
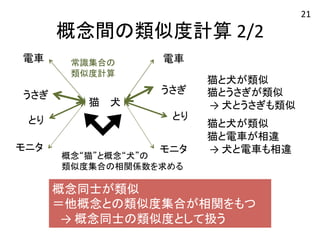
概念間の類似度計算 2/2 常識集合の
類似度計算 猫 犬 電車 概念“猫”と概念“犬”の 類似度集合の相関係数を求める 猫と犬が類似 猫とうさぎが類似 → 犬とうさぎも類似 猫と犬が類似 猫と電車が相違 → 犬と電車も相違 電車 うさぎ とり モニタ うさぎ とり モニタ 概念同士が類似 =他概念との類似度集合が相関をもつ → 概念同士の類似度として扱う 21
31.
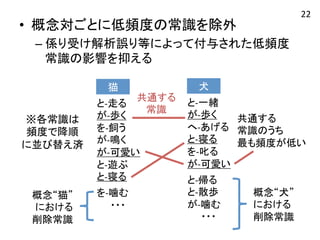
• 概念対ごとに低頻度の常識を除外 –
係り受け解析誤り等によって付与された低頻度 常識の影響を抑える と-‐走る が-‐歩く を-‐飼う が-‐鳴く が-‐可愛い と-‐遊ぶ と-‐寝る を-‐噛む ・・・ と-‐一緒 が-‐歩く へ-‐あげる と-‐寝る を-‐叱る が-‐可愛い と-‐帰る と-‐散歩 が-‐噛む ・・・ 共通する 常識 概念“猫” における 削除常識 共通する 常識のうち 最も頻度が低い 概念“犬” における 削除常識 猫 犬 ※各常識は 頻度で降順 に並び替え済 22
32.
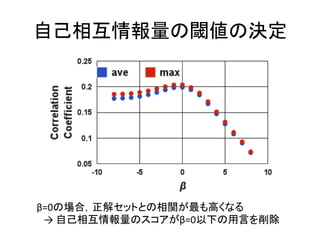
類似度計算の評価 • 出現頻度の高い上位1,617個の名詞について,
各手法と正解セットの類似度集合の相関を計 算 – 比較手法 • 用言の削除は行わず,出現頻度で重み付けした用言 を用いる手法(ベースライン1) • 自己相互情報量のスコアが閾値以下の用言を削除す る手法(ベースライン2)(相澤法) – 提案手法 23
33.
になる.正解セットとして,日本語語彙大系中における名詞ほど類似度が高く,距離が離れているほど類似度が低いとが類似度の指標として有用であるということは,Resnik et al.る.
大系中においては,1 つの名詞に対し複数の概念が定義され類似度を計算するということは,その名詞が持つ概念集合になる.概念x ∈ X を持つ名詞と,概念y ∈ Y を持つ名計算される. ーラス中において複数概念を持つ名詞同士の類似度計算の式は,Jiang et al.たものを用いた.ここでd(wi) とは,根からwi までの深さ,d(wi, wj) とは,になる.正解セットとして大系中における名詞間いほど類似度が高く,距離ほど類似度が低いとしが類似度の指標として有用ことは,Resnik et al.る. 大系中においては,1 つの数の概念が定義されての類似度を計算するという名詞が持つ概念集合同になる.概念x ∈ X を持wi 概念y ∈ Y を持つ名詞計算される. 度集合の相関係数を求める.両者の相関が高いほど正しく名詞同士の類似度をいることになる.正解セットとして,日本語語彙大系中における名詞間の距離距離が近いほど類似度が高く,距離が離れているほど類似度が低いとした.シでの距離が類似度の指標として有用であるということは,Resnik et al.40)におられている. 本語語彙大系中においては,1 つの名詞に対し複数の概念が定義されている.名詞同士の類似度を計算するということは,その名詞つ概念集合同士の類することになる.概念x ∈ X を持つ名詞wi と,概念y ∈ Y を持つ名詞wj の下の式で計算される. おいて複数概念を持つ名詞同士の類似度計算の式は,おなる.正解セットとして,日本語語彙大系中における名詞間のほど類似度が高正く解,距セ離がッ離トれのてい作る成ほど方類似法 度が低いとした類似度の指標として有用であるということは,Resnik et al.40). • 日本語語彙大系中における名詞間の距離を 系中に類お似いて度はと,し1 てつ用のい名る 詞に(Resnik 対し複数et のal. 概1995) 念が定義されてい類似度を– 計距算離すがる近といいほうどこ類と似は度,がそ高のく名な詞る が持つ概念集合同士なる.概– 概念念 x ∈ X を持をつ持名つ詞名詞wi と ,と概概念念 y ∈ Y をを持持つつ 名詞される名. 詞 の類似度計算式 ave sim(wi, wj) = 1 |XY | ! x∈X,y∈Y 2d(wi,x, wj,y) d(wi,x)d(wj,y) max sim(wi, wj) = max " 2d(wi,x, wj,y) d(wi,x)d(wj,y) # ave sim(wi, wj) = 1 XY ! x∈X,y∈Y 2d(wi,x, wj,y) d(wi,x)d(wj,y) max sim(wi, wj) = max " 2d(wi,x, wj,y) d(wi,x)d(wj,y) # ave sim(wi, wj) = 1 |XY | ! x∈X,y∈Y 2d(wi,x, wj,y) d(wi,x)d(wj,y) max sim(wi, wj) = max " 2d(wi,x, wj,y) d(wi,x)d(wj,y) # ave sim(wi, wj) = 1 |XY | ! x∈X,y∈Y 2d(wi,x, wj,y) d(wi,x)d(wj,y) max sim(wi, wj) = max " 2d(wi,x, wj,y) d(wi,x)d(wj,y) # ける名詞間の距離を計算 度が低いとした.シソーラ Resnik et al.40)においても が定義されている.そのた つ概念集合同士の類似度を Y を持つ名詞wj の類似度 wj,y) wj,y) (7.1) # (7.2) 24
34.
et al.においても が共有する上位概念までの深さを表している.名詞wi
と名Resnik る. 系中においては,1 つの名詞に対し複数の概念が定義され類似度を計算するということは,その名詞が持つ概念集合になる.概念x ∈ X を持つ名詞wi と,概念y ∈ Y を持つ名計算される. 複数概念を持つ名詞同士の類似度計算の式は,Jiang et ここでd(wi) とは,根からwi までの深さ,d(wi, wj) と有する上位概念までの深さを表している.名詞wi と名. 大系中においては,1 つの名詞に対し複数の概念が定義されていの類似度を計算するということは,その名詞が持つ概念集合同士になる.X を持つ名詞wi と,概念y ∈ Y を持つ名詞計算さる25 おい概ては念,1 つの名詞に対し複数の概が定義されている同.そ士のた の類似度計算念が式 定義されていを計算するということは,その名詞が持つ概念集合同士つ概• 念概集概合念 念同士の類似度を 第7 章概念同士の類似x ∈ X をを持持つつ名名詞詞wi と と,概概念念 y ∈ Y をを持持 つ名詞Y を持つるつ名. 名詞 詞のの類類似似度 度計算式 位wj 1 ! ! ! ave ave 1 sim(sim(wi, wi, wi, wj) wj) wj) 図= 7.3 = = β 値1 を2d(2d(wi,wi,x, wj,x, wj,y) y) 値を-8 から8 2d(までwi,変x, 化wj,させy) た場合の正解7.3 |XY |XY |XY β | | | -8 から8 x∈X,y∈Y d(まd(wi,でd(wi,変wi,x)x)化d(d(さx)wj,せwj,d(たy) wj,y) 場合y) の正解セッ(7.1) x∈x∈X,y∈X,Y y∈Y 7.2.2 評価結果 " " " # # # max sim(wi, 7.2.2 2d(wi,x, wj,y) max max sim(sim(wi, wi, wj) wj) wj) = = = max max 2d(2d(wi,wi,x, wj,x, y) wj,y) max d(d(wi,d(wi,wi,x)x)d(d(x)wj,wj,d(y) wj,y) y) ースラインと提案手法に付与される用言のトップ10 の例を,表7.1 に示す. 案手法では,すべての用言がそれぞれの名詞に対する常識となっている.ベー士をが比共較す有るすとる,ど上ち位ら概も上念位まにでラのンク深付さけをされ表るし名て詞にいほると.んど名違詞いがなwi とwj,y) d(wj,y) y) y) # 以下に示す式を用いて,概念x ∈ X を持つ名詞wi 似度を計算する(Jac: Jaccard 係数,Simp: Simpson 数,freq(wi, p): 名詞wi に係る用言p の出現頻度.仮場合,freq(wi, p) 0 となる). において複数概念を持つ(7.2) 名詞同士の類似度計算の式は,Jiang 用いた.ここでd(wi) とは,根からwi までの深さ,d(wi, wj) とwj において複数概念を持つ名詞同士の類似度計算の式は,Jiang 用いた.ここでd(wi) とは,根からwi までの深さ,d(wi, wj) wj の式は,Jiang et al.24)の定 さ,d(wi, wj) とは,根から : 名詞 に係る用言 の出現頻度 図評価結果 以下に示す式を用いて,概念x ∈ X を持つ名詞wi と,似度を計算する(Jac: Jaccard 係数,Simp: Simpson 係数数,freq(wi, p): に係る用言p の出現頻度.仮に用場合,freq(wi, p) の値は0 となる). 32 90 %を占める1,617 個の名詞を用いて,評価セットと正解セットにおける各名類似度集合の相関係数を求める.両者の相関が高いほど正しく名詞同士の類似度きていることになる.正解セットとして,日本語語彙大系中における名詞間の距し,距離が近いほど類似度が高く,距離が離れているほど類似度が低いとした.ス中での距離が類似度の指標として有用であるということは,Resnik et al.40)に述べられている. 日本語語彙大系中においては,1 つの名詞に対し複数の概念が定義されているめ,名詞同士の類似度を計算するということは,その名詞が持つ概念集合同士の計算することになる.概念x ∈ X を持つと,概念y ∈ Y を持つ名詞wj のは以下の式で計算される. 1 ! 2d(wi,x, wj,y) 7.2.2 評価結果 下に示す式を用いて,概念x ∈ X を持つ名詞wi と,概念y ∈ Y を持つ名詞を計算する(Jac: Jaccard 係数,Simp: Simpson 係数,WJac: 重み付きJaccard freq(wi, p): 名詞wi に係る用言p の出現頻度.仮に用言p が名詞wi に係らな,freq(wi, p) の値は0 となる). Jac(wi, wj) = |X ∪ Y | |X ∩ Y | Simp(wi, wj) = |X ∪ Y | min(|X|, |Y |) WJac(wi, wj) = ! p min(freq(wi, p), freq(wj, p)) ! p max(freq(wi, p), freq(wj, p))
35.
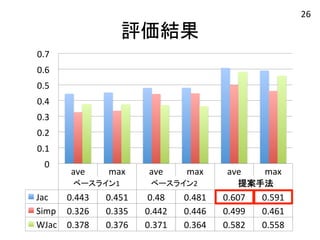
評価結果 ave .
max . ave . max . ave . max . 0.7 0.6 0.5 0.4 0.3 0.2 0.1 Jac 0.443 0.451 0.48 0.481 0.607 0.591 Simp 0.326 0.335 0.442 0.446 0.499 0.461 WJac 0.378 0.376 0.371 0.364 0.582 0.558 0 ベースライン1 ベースライン2 提案手法 26
36.
常識知識ベースの評価 1/2 27
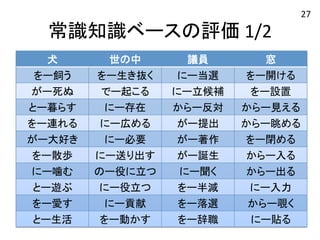
犬 世の中 議員 窓 をー飼う をー生き抜く にー当選 をー開ける がー死ぬ でー起こる にー立候補 をー設置 とー暮らす にー存在 からー反対 からー見える をー連れる にー広める がー提出 からー眺める がー大好き にー必要 がー著作 をー閉める をー散歩 にー送り出す がー誕生 からー入る にー噛む のー役に立つ にー聞く からー出る とー遊ぶ にー役立つ をー半減 にー入力 をー愛す にー貢献 をー落選 からー覗く とー生活 をー動かす をー辞職 にー貼る
37.
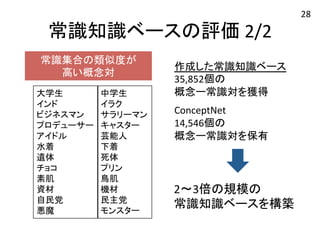
常識知識ベースの評価 2/2 常識集合の類似度が
高い概念対 大学生 中学生 インド イラク ビジネスマン サラリーマン プロデューサー キャスター アイドル 芸能人 水着 下着 遺体 死体 チョコ プリン 素肌 鳥肌 資材 機材 自民党 民主党 悪魔 モンスター 作成した常識知識ベース 35,852個の 概念ー常識対を獲得 ConceptNet 14,546個の 概念ー常識対を保有 2〜3倍の規模の 常識知識ベースを構築 28
38.
結論 • 言語処理で利用可能な大規模常識知識ベー
スを自動的に構築 – 35,852個の概念ー常識対を自動的に獲得 – 統計情報を利用し常識として適切な用言を選定 → 多くの概念の係り先となる用言は常識として 不適切であり,またある用言が常識として適切か 否かは常識付与の対象である概念に依存 – 常識集合の類似度に基づき概念の類似度計算 → ベースラインと比較して類似度計算の精度が高く, 一般的な名詞の類似度計算タスクにも有用 29
39.
名詞と名詞が格付きで係る用言の組を抽出 1/2 •
概念と常識を抽出するデータ源 – Web日本語Nグラム (7グラム) • 200億文から,出現頻度20回以上のNグラムを抽出 – 7グラム総数: 570,204,252個 Nグラム 私は猫が好きです → 私 は 猫 が 好き です 2グラム: [私は] [は猫] [猫が] [が好き] [好きです] 3グラム: [私は猫] [は猫が] [猫が好き] [が好きです]
40.
名詞と名詞が格付きで係る用言の組を抽出 2/2 •
7グラムデータを係り受け解析し,名詞と名詞 が格付きで係る用言の組を抽出 抽出した名詞と格ー用言の組 – 14,240,242,840対 • 名詞の異なり数:298,976語 • 格ー用言の異なり数:30,434語 概念となる名詞 常識となる格ー用言 を選定
41.
常識として不適切な用言の除外 係り元となる概念の数別に見た場合の用言の出現分布 40000
35000 30000 25000 20000 15000 10000 5000 0 疎な分布となる範囲 =削除用言 0 2000 4000 6000 8000 10000 用 言 叏異 友 叫数 用言の係り元となる概念の数
42.
常識として不適切な用言の除外 係り元となる概念の数別に見た場合の用言の出現分布
43.
係り先用言数が多い概念上位N件における用言の出現分布 N=1,000 N=10,000
疎な分布 Nの増加に伴い,削除される用言数が少なくなる 横軸:用言の係り元となる概念の数 縦軸:用言の異なり数 =係り先の用言数が多い概念ほど,削除用言数が多くなる
44.
自己相互情報量の閾値の決定 β=0の場合,正解セットとの相関が最も高くなる →
自己相互情報量のスコアがβ=0以下の用言を削除
Download



















![名詞と名詞が格付きで係る用言の組を抽出
1/2
• 概念と常識を抽出するデータ源
– Web日本語Nグラム
(7グラム)
• 200億文から,出現頻度20回以上のNグラムを抽出
– 7グラム総数:
570,204,252個
Nグラム
私は猫が好きです
→
私 は 猫 が 好き です
2グラム: [私は]
[は猫]
[猫が]
[が好き]
[好きです]
3グラム: [私は猫]
[は猫が]
[猫が好き]
[が好きです]](https://image.slidesharecdn.com/14nlp-makabi-140919181740-phpapp01/85/slide-39-320.jpg)