2/14/2017 第18回 #カステラ本31
10.13.2 部分依存図 [3/E]
部分依存関数:Kクラス分類の場合
各クラスに一つずつ合計K個のモデルが存在
各モデルとそれぞれの確率 の関係は下記
従って、fk(X)はそれぞれの確率に対数を適用した単調増加関数
最も関連性が高い予測変数 に対する各fk(X)の部分依存図を
見ると、各クラスの対数オッズがどのように各入力変数の依存しているかを
理解しやすい。
KkxTxf
M
m kmk ,,2,1,1
K
k lkl Ι
K
Ι 1
22 1
K
t
xf
xf
k
t
k
e
e
xp
1
K
l lkk Xp
K
XpXf 1
log
1
log









![2/14/2017 第18回 #カステラ本 9
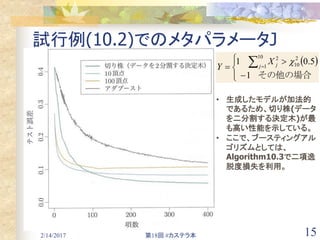
10.10.2 勾配ブースティング [1/2]
前向き段階的ブースティング(Algorithm10.2)との類似性
段階的解法の各ステップで解となる木は、式(10.29)を最大限減少させる木
従って、木の予測T(xi,Θm)は、負の勾配gi,m(10.35)に概念的に対応
段階的解法(10.30)の解は、最急降下法での直線探索(10.36)と類似
最急降下法では何故ダメか?
最急降下法では、木の要素への決定木としての制約を無視しているため、負
の勾配は制約を受けない最大降下方向であり正しい最小解に到達し難い。
勾配(10.35)は訓練データxiでのみ定義されており、fM(x)を訓練データに現れ
ていない新たなデータに汎化させる事が困難。
対処策
m回目の繰返しにおいて予測tmが出来る限り勾配に近づくような木T(x,Θm)
を導出する事で対処
例えば、この近さの基準として二乗誤差を用いると最小二乗ブースティング。
N
i miim xTg m
m
1
2
;minargˆ](https://image.slidesharecdn.com/10-170213140459/85/10-9-320.jpg)
![2/14/2017 第18回 #カステラ本 10
10.10.2 勾配ブースティング [2/E]](https://image.slidesharecdn.com/10-170213140459/85/10-10-320.jpg)









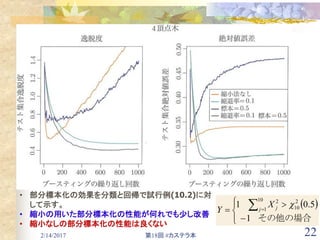






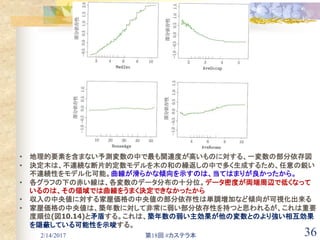
![2/14/2017 第18回 #カステラ本 29
10.13.2 部分依存図 [1/3]
部分依存関数:決定木の場合
X^T=(X1,X2,…,Xp):入力予測変数
XS:l<pなる S⊂{1,2,…,p} をIndexとするXの部分ベクトル
C:XSのIndexの補集合であり、S∪C= {1,2,…,p}を満たす
このとき、f(X)=f(XS,XC)
平均もしくはf(X)のXSへの部分的な依存性の定義
fのXCでの周辺化による平均
f(X)上のXCの影響(平均)を計算したのちのf(X)上のXSの影響を示す
XSがXCと強い相互作用を持たないとき、f(X)上で選択した部分集合の効果を記述
するのに有効
部分依存関数(推定):
決定木を用いると、上記式はデータ参照なく木自体から高速に算出可能
CSXSS XXfEXf C
,
の値訓練データに現れる CNCCC
N
i iCSSS
Xxxx
xXf
N
Xf
:,,
,
1
21
1
N
i Sj XiCjSS
Sj XiCjiCS
j
j
RxI
N
Xf
RxIxXf
1
1
,
より
(10.47)
(10.48)](https://image.slidesharecdn.com/10-170213140459/85/10-29-320.jpg)
![2/14/2017 第18回 #カステラ本 30
10.13.2 部分依存図 [2/3]
変数部分集合の条件付き期待値は部分依存関数としては不
適切である事
部分依存関数は、「f(X)上のXCの影響(平均)を計算したのちのf(X)上のXS
の影響を示すもの」であって、「f(X)上のXCの影響を無視したXSの影響を示
すものではない」事を以下に示す。
XS単体の影響は条件付き期待値:
XS単体の関数によるf(X)に対する最小二乗近似(??)
(10.49)[の標本平均での推定]と(10.48) は、XSとXCが独立である場合にのみ等しい
選択された変数の部分集合の効果が完全に加法的な場合
f(X)=h1(XS)+h2(XC) より
fS(XS)=h1(XS) [可視化しやすい]
選択された変数の部分集合の効果が完全に乗法的な場合
f(X)=h1(XS)・h2(XC) より
∃K:定数 s.t. fS(XS)=K・h1(XS) [可視化しやすい]
一方(10.49)は、上記何れの場合においても、 h1(XS)とはならない
f(X)が全く依存性を持たない変数集合でも、式(10.49)は強い影響を示す
SCSSS XXXfEXf ,
~
(10.49)](https://image.slidesharecdn.com/10-170213140459/85/10-30-320.jpg)
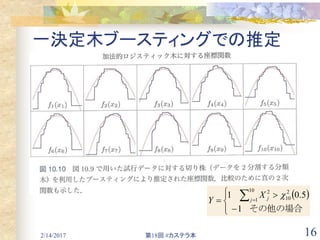
![2/14/2017 第18回 #カステラ本 31
10.13.2 部分依存図 [3/E]
部分依存関数:Kクラス分類の場合
各クラスに一つずつ合計K個のモデルが存在
各モデルとそれぞれの確率 の関係は下記
従って、fk(X)はそれぞれの確率に対数を適用した単調増加関数
最も関連性が高い予測変数 に対する各fk(X)の部分依存図を
見ると、各クラスの対数オッズがどのように各入力変数の依存しているかを
理解しやすい。
KkxTxf
M
m kmk ,,2,1,1
K
k lkl Ι
K
Ι 1
22 1
K
t
xf
xf
k
t
k
e
e
xp
1
K
l lkk Xp
K
XpXf 1
log
1
log](https://image.slidesharecdn.com/10-170213140459/85/10-31-320.jpg)





![2/14/2017 第18回 #カステラ本 39
10.14.2 ニュージーランドの魚 [1/2]
データ諸元:2,553箇所のクロマトウダイ地引網からのデータ
変数名 変数の意味
応答変数 Y (非負の)漁獲高[漁獲確率]
予測変数 TempResid 水温
AvgDepth 漁網の平均深度
SusPartMatter 海水内の浮遊粒子状物質の指標(人工衛星で計測)
SalResid 塩分濃度
SSTGrad 海表面の温度勾配の指標
ChlaCase2 生態系の産出系の指標(人工衛星で計測)
…… ……](https://image.slidesharecdn.com/10-170213140459/85/10-39-320.jpg)

![2/14/2017 第18回 #カステラ本 41
10.14.2 ニュージーランドの魚 [2/E]
クロマトウダイの漁獲確率や漁獲高の推定
前処理
水温と塩分濃度は深度と相関が強いため、深度からその2つの計測値を(それぞれ別のノンパ
ラメトリック回帰を用いて)算出したときの残差を代替利用
モデル式:E(Y|X)=E(Y|Y>0,X)・Pr(Y>0|X), Y:非負の漁獲高
第2項目をロジスティクス回帰、第1項目は漁獲があった2,353回の漁のみを用いて推定
GBMロジスティクス回帰:Pr(Y>0|X)
終端頂点:J=10, 学習率:ν=0.025, 二項逸脱度損失関数でGBM
項数および縮小率の決定のために、10分割の交差確認実施
正の漁獲高の回帰:log(Y)をモデリングし、予測のときに対数除去
終端頂点:J=10, 学習率:ν=0.01, 二乗誤差損失関数でGBM
項数および縮小率の決定のために、10分割の交差確認実施](https://image.slidesharecdn.com/10-170213140459/85/10-41-320.jpg)



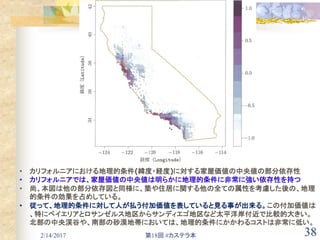
![2/14/2017 第18回 #カステラ本 45
10.14.3 個人属性情報データ [1/2]
データ諸元:ショッピングモール顧客の9,243のアンケート結果
変数 変数の意味
応答変数 Student 学生
Retired 退職者
Prof/Man 専門職/管理職
Homemaker 主婦
Labor 労働者
Clerical 聖職者
Military 軍人
Unemployed 無職
Sales 営業職
変数 変数の意味
予測変数 yrs-BA ??
children 子供
num-hsld ??
lang 言語
type-home ??
mar-stat ??
ethnic 民族
sex 性別
mar-dlinc ??
hsld-stat ??
edu 教育
income 収入
age 年齢](https://image.slidesharecdn.com/10-170213140459/85/10-45-320.jpg)
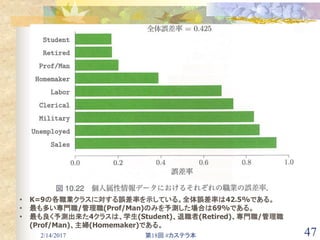
![2/14/2017 第18回 #カステラ本 46
10.14.3 個人属性情報データ [2/E]
多重加法的回帰木(MART)を用いた勾配ブースティング
終端頂点:J=6, 学習率:ν=0.1, MARTで数値的応答予測
データ集合を無作為に訓練集合(80%)とテストデータ(20%)に分割
この例の目的は、職業以外の13変数を予測変数として職業を予測し、さらに、
職業の違いもたらしている変数を特定する事。](https://image.slidesharecdn.com/10-170213140459/85/10-46-320.jpg)
























![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)
















