Download as PDF, PPTX






![Simple word matching
(4)
• perl will always match at the earliest possible
point in the string
my $string ='Stringify this stringy world!';
my $word = 'string';
print "found '$word' in any casen"
if $string =~ m{$word}i;
• Some characters, called metacharacters, are
reserved for use in regex notation. The
metacharacters are (14):
{ } [ ] ( ) ^ $ . | * + ?
• A metacharacter can be matched by putting a
backslash before it
print "The string n'$string'n contains a DOTn"
if $string =~ m|.|;](https://image.slidesharecdn.com/09regex-120927143043-phpapp01/85/Working-with-text-Regular-expressions-6-320.jpg)


![Character classes
• A character class allows a set of possible
characters, to match
• Character classes are denoted by brackets [ ]
with the set of characters to be possibly matched
inside
• The special characters for a character class are
- ] ^ $ and are matched using an escape
• The special character '-' acts as a range operator
within character classes so you can write [0-9]
and [a-z]](https://image.slidesharecdn.com/09regex-120927143043-phpapp01/85/Working-with-text-Regular-expressions-9-320.jpg)
![Character classes
• Example
use strict; use warnings;$=$/;
my $string ='A probably long chunk of text containing
strings';
my $thing = 'ong ung ang enanything';
my $every = 'iiiiii';
my $nums = 'I have 4325 Euro';
my $class = 'dog';
print 'matched any of a, b or c'
if $string =~ /[abc]/;
for($thing, $every, $string){
print 'ingy brrrings nothing using: '.$_
if /[$class]/
}
print $nums if $nums =~/[0-9]/;](https://image.slidesharecdn.com/09regex-120927143043-phpapp01/85/Working-with-text-Regular-expressions-10-320.jpg)
![Character classes
• Perl has several abbreviations for common character
classes
• d is a digit – [0-9]
• s is a whitespace character – [ trnf]
• w is a word character
(alphanumeric or _) – [0-9a-zA-Z_]
• D is a negated d – any character but a digit [^0-9]
• S is a negated s; it represents any non-whitespace
character [^s]
• W is a negated w – any non-word character
• The period '.' matches any character but "n"
• The dswDSW inside and outside of character classes
• The word anchor b matches a boundary between a word
character and a non-word character wW or Ww](https://image.slidesharecdn.com/09regex-120927143043-phpapp01/85/Working-with-text-Regular-expressions-11-320.jpg)
![Character classes
• Example
my $digits ="here are some digits3434 and then ";
print 'found digit' if $digits =~/d/;
print 'found alphanumeric' if $digits =~/w/;
print 'found space' if $digits =~/s/;
print 'digit followed by space, followed by letter'
if $digits =~/ds[A-z]/;](https://image.slidesharecdn.com/09regex-120927143043-phpapp01/85/Working-with-text-Regular-expressions-12-320.jpg)


/;
print 'found a letter followed by digits":'.$1
if $digits =~/([a-z](d+))/;
# $1 $2
print 'found letters followed by digits":'.$1
if $digits =~/([a-z]+)(d+)/;
# $1 $2](https://image.slidesharecdn.com/09regex-120927143043-phpapp01/85/Working-with-text-Regular-expressions-15-320.jpg)

![Matching repetitions
use strict; use warnings;$=$/;
my $digits ="here are some digits3434 and then678 ";
print 'found some letters followed by leters or
digits":'.$1 .$2
if $digits =~/([a-z]{2,})(w+)/;
print 'found three letter followed by digits":'.$1 .$2
if $digits =~/([a-z]{3}(d+))/;
print 'found up to four letters followed by digits":'.
$1 .$2
if $digits =~/([a-z]{1,4})(d+)/;](https://image.slidesharecdn.com/09regex-120927143043-phpapp01/85/Working-with-text-Regular-expressions-17-320.jpg)
![Matching repetitions
• Greeeedy
use strict; use warnings;$=$/;
my $digits ="here are some digits3434 and then678 ";
print 'found as much as possible letters
followed by digits":'.$1 .$2
if $digits =~/([a-z]*)(d+)/;](https://image.slidesharecdn.com/09regex-120927143043-phpapp01/85/Working-with-text-Regular-expressions-18-320.jpg)


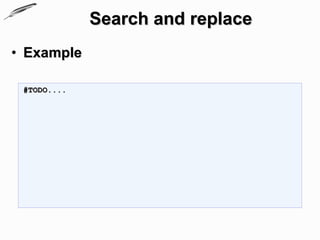




This document provides an extensive overview of Perl programming focused on text processing and regular expressions. It covers various fundamental concepts including simple word matching, character classes, matching repetitions, search and replace functionality, and the split operator, with practical examples throughout. Additionally, it references resources for further exploration of regular expressions in Perl.




























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
















