


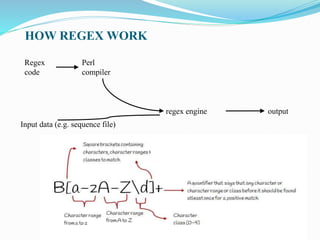

![STAGES
1. The characters
| ( ) [ { ^ $ * + ? .
are meta characters with special meanings in regular expression. To
use metacharacters in regular expression without a special meaning being
attached, it must be escaped with a backslash. ] and } are also
metacharacters in some circumstances.
2. Apart from meta characters any single character in a regular expression
/cat/ matches the string cat.
3. The meta characters ^ and $ act as anchors:
^ -- matches the start of the line
$ -- matches the end of the line.
so regex /^cat/ matches the string cat only if it appears at the start of
the line.
/cat$/ matches only at the end of the line.
/^cat$/ matches the line which contains the string cat and /^$/
matches an empty line.
4. The meta character dot (.) matches any single character except
newline, so/c.t/ matches cat,cot,cut, etc.](https://image.slidesharecdn.com/unit-1-stringspatternsandregularexpressions-170313141650/85/Unit-1-strings-patterns-and-regular-expressions-5-320.jpg)
![STAGES
5. A character class is set of characters enclosed in square brackets. Matches any
single character from those listed.
So /[aeiou]/- matches any vowel
/[0123456789]/-matches any digit
Or /[0-9]/
6. A character class of the form /[^....]/ matches any characters except those listed,
so /[^0-9]/ matches any non digit.
7. To remove the special meaning of minus to specify regular expression to match
arithmetic operators.
/[+-*/]/
8. Repetition of characters in regular expression can be specified by the
quantifiers
* -- zero or more occurrences
+ -- one or more occurrences
? – zero or more occurrences
9. Thus /[0-9]+/ matches an unsigned decimal number and /a.*b/ matches a substring
starting with ‘a’ and ending with ‘b’, with an indefinite number of other characters
in between.](https://image.slidesharecdn.com/unit-1-stringspatternsandregularexpressions-170313141650/85/Unit-1-strings-patterns-and-regular-expressions-6-320.jpg)
![FACILITIES
1. Alternations |
If RE1,RE2,RE3 are regular expressions, RE1|RE2|RE3 will match any one of the
components.
2. Grouping- ( )
Round Brackets can be used to group items.
/pitt the (elder|younger)/
3. Repetition counts
Explicit repetition counts can be added to a component of regular expression
/(wet[]){2}wet/ matches ‘ wet wet wet’
Full list of possible count modifiers are
{n} – must occur exactly n times
{n,} –must occur at least n times
{n,m}- must occur at least n times but no more than m times.
4. Regular expression
Simple regex to check for an IP address:
^(?:[0-9]{1,3}.){3}[0-9]{1,3}$](https://image.slidesharecdn.com/unit-1-stringspatternsandregularexpressions-170313141650/85/Unit-1-strings-patterns-and-regular-expressions-7-320.jpg)







![SPLIT
Syntax of split
split REGEX, STRING will split the STRING at every match of the REGEX.
split REGEX, STRING, LIMIT where LIMIT is a positive number. This will
split the STRING at every match of the REGEX, but will stop after it found LIMIT-
1 matches. So the number of elements it returns will be LIMIT or less.
split REGEX - If STRING is not given, splitting the content of $_, the default
variable of Perl at every match of the REGEX.
split without any parameter will split the content of $_ using /s+/ as REGEX.
Simple cases
split returns a list of strings:
use Data::Dumper qw(Dumper); # used to dump out the contents of any
variable during the running of a program
my $str = "ab cd ef gh ij";
my @words = split / /, $str;
print Dumper @words;
The output is:
$VAR1 = [ 'ab', 'cd', 'ef', 'gh', 'ij' ];](https://image.slidesharecdn.com/unit-1-stringspatternsandregularexpressions-170313141650/85/Unit-1-strings-patterns-and-regular-expressions-15-320.jpg)

The document provides an introduction to regular expressions (regex). It discusses that regex allow for defining patterns to match strings. It then covers simple regex patterns and operators like character classes, quantifiers, alternations, grouping and anchors. The document also discusses more advanced regex topics such as back references, match operators, substitution operators, and the split operator.





























































































![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)
