This document discusses support vector machines (SVM), focusing on the concepts of feature space, optimal hyperplanes, and margin maximization for linear classification. It explains the optimization problems associated with SVM, including the use of Lagrange multipliers and methods for handling non-separable data with soft margins. The document also covers multiclass SVM classifications and offers insights into kernel functions, emphasizing the global solution and analytical properties of SVM.



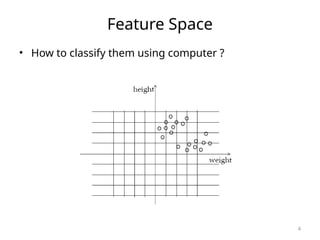
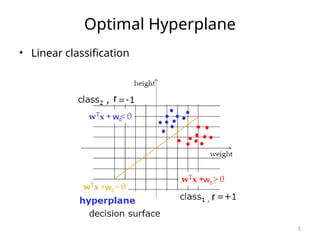
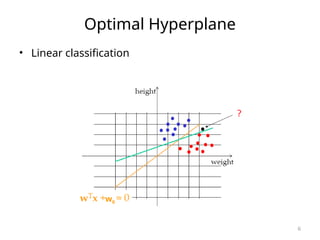
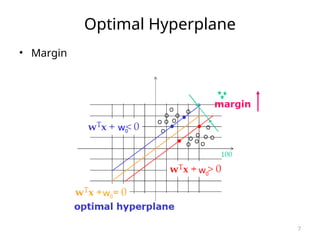
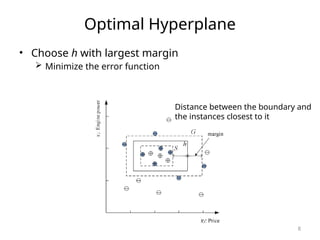
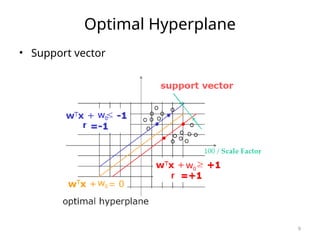

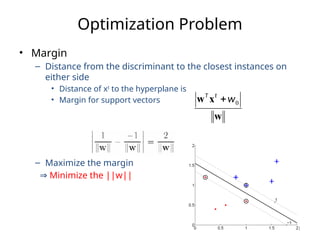










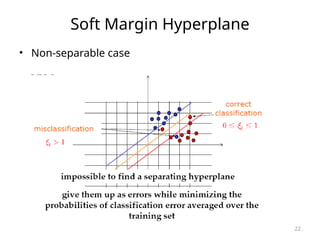


































![SVM[Support vector Machine] Machine learning](https://cdn.slidesharecdn.com/ss_thumbnails/svm-250403184638-1cd9afdb-thumbnail.jpg?width=640&height=640&fit=bounds)










































