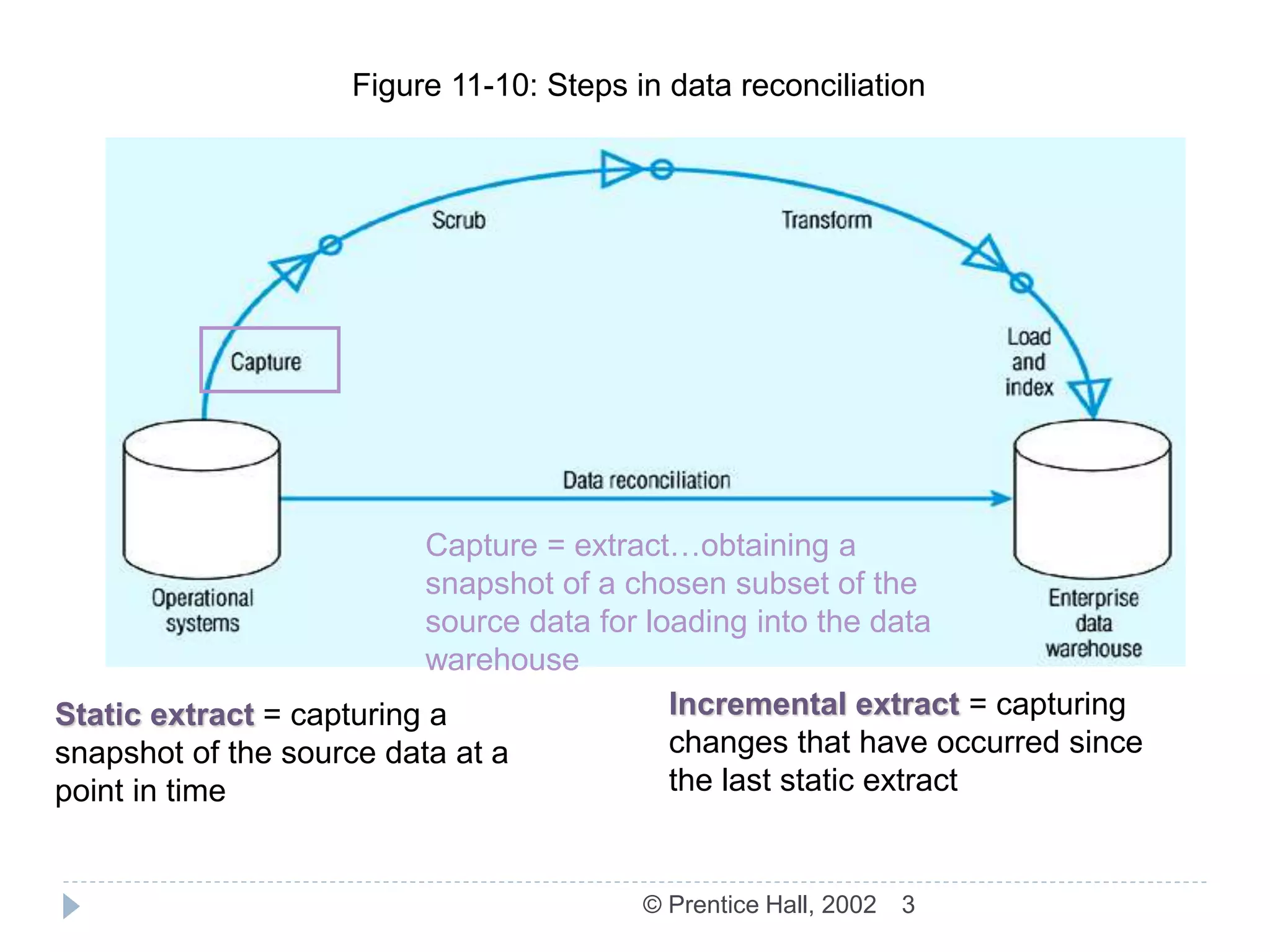
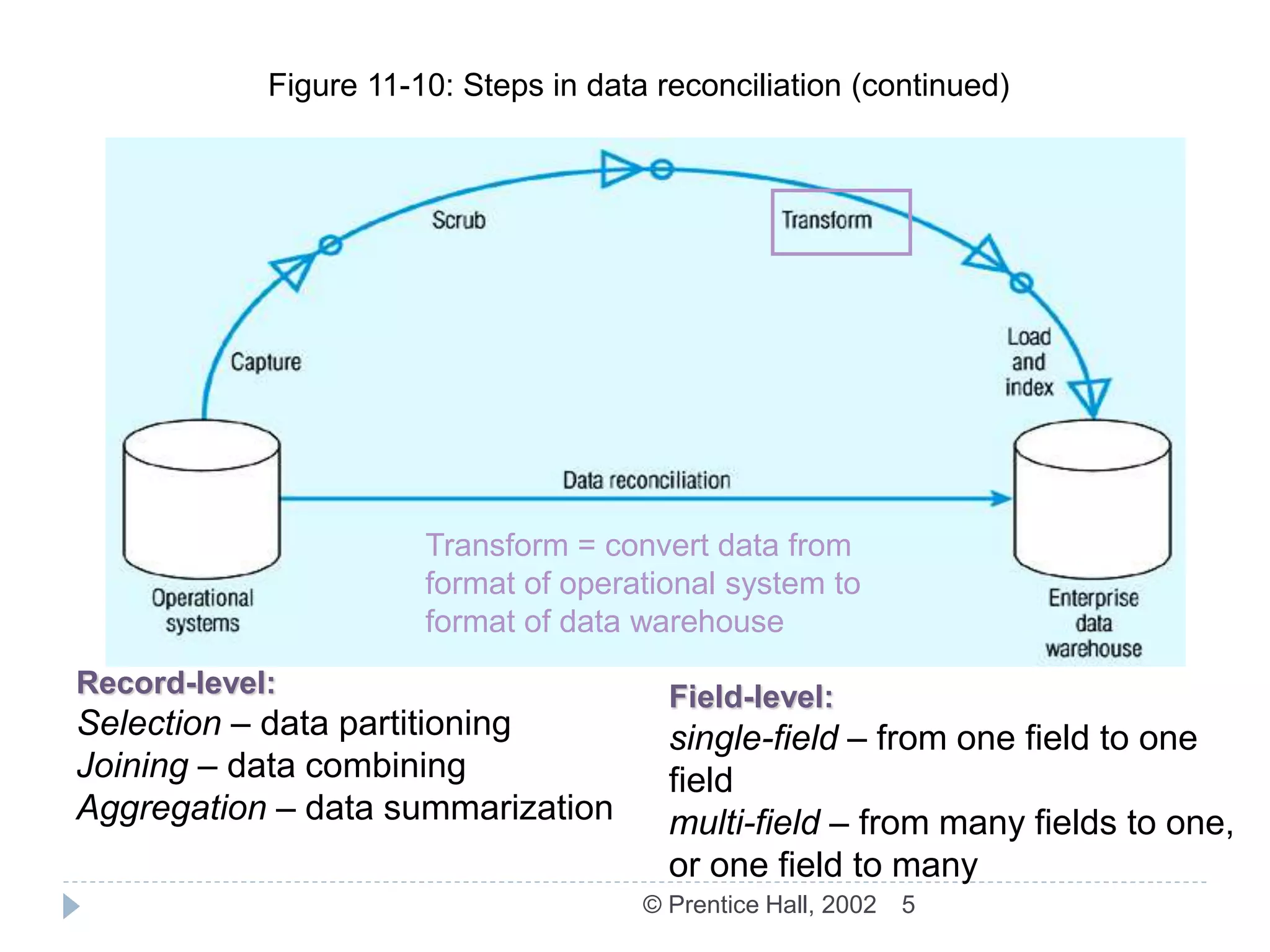
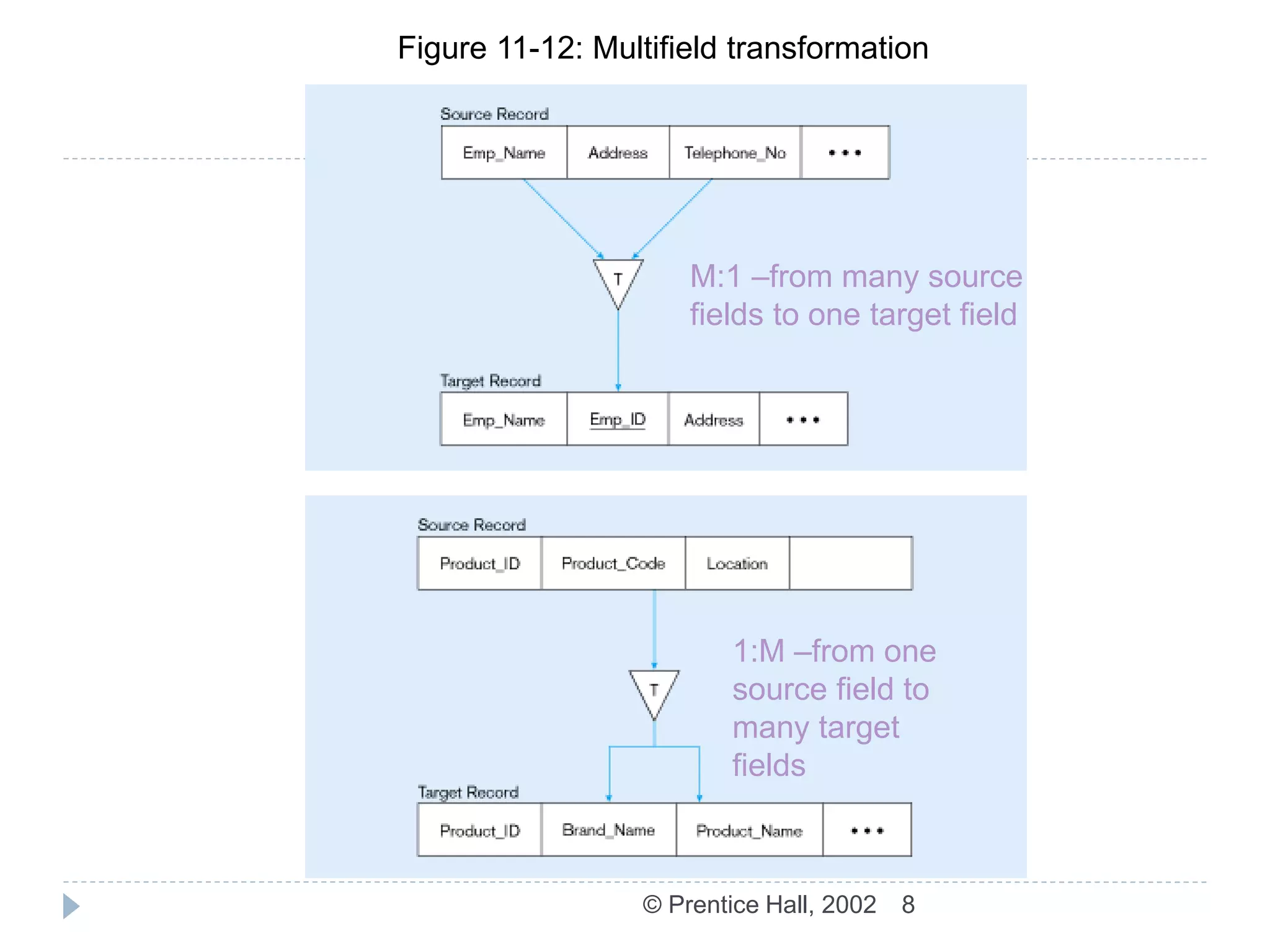
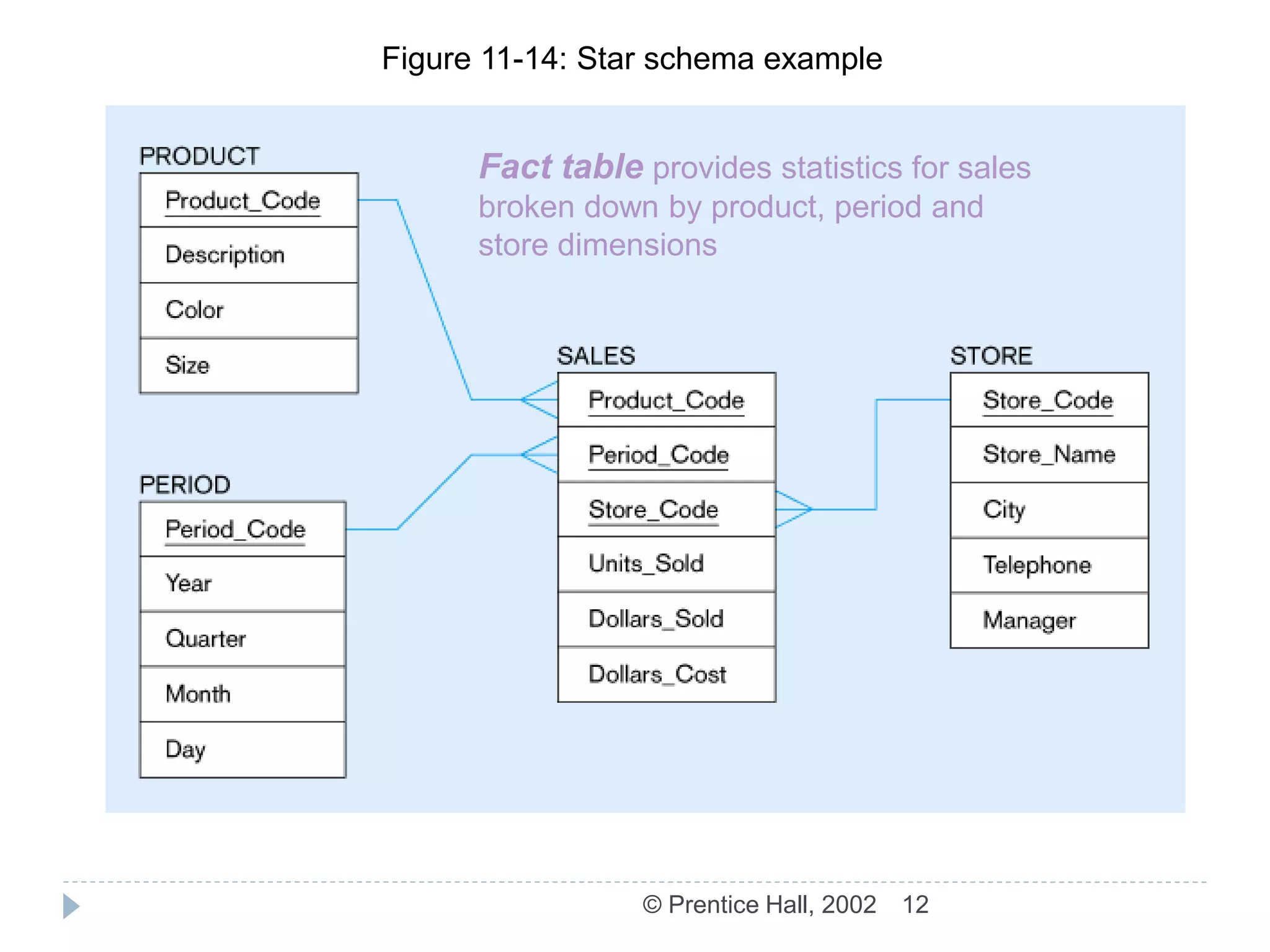
The document discusses the ETL (Extract-Transform-Load) process used in data warehousing. The key steps of ETL are: 1) Capture/Extract which obtains data from source systems, 2) Scrub/Cleanse which cleans and formats the data, 3) Transform which converts the data to the structure of the data warehouse, and 4) Load/Index which loads the transformed data into the warehouse where it can be indexed. The ETL process results in data in the warehouse that is detailed, historical, normalized, comprehensive, timely, and quality controlled.