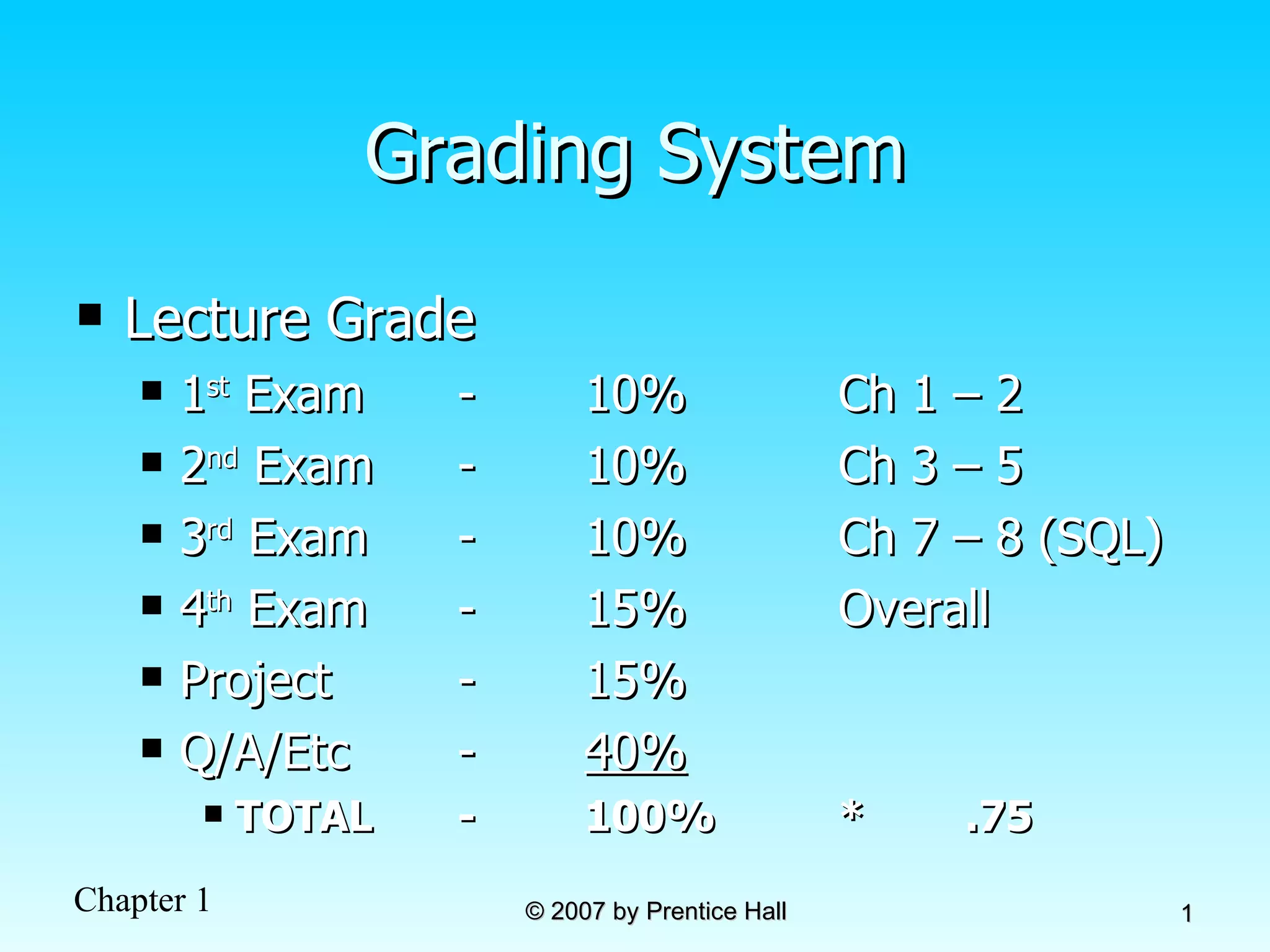
The document summarizes a grading system for a course with the following key points:
- The course grade is made up of exams (40%), a project (15%), and lab exercises (25%)
- Exams include 4 chapter exams worth 10-15% each and a SQL exam worth 10%
- The project is worth 15% and lab exercises are worth 25% of the final grade











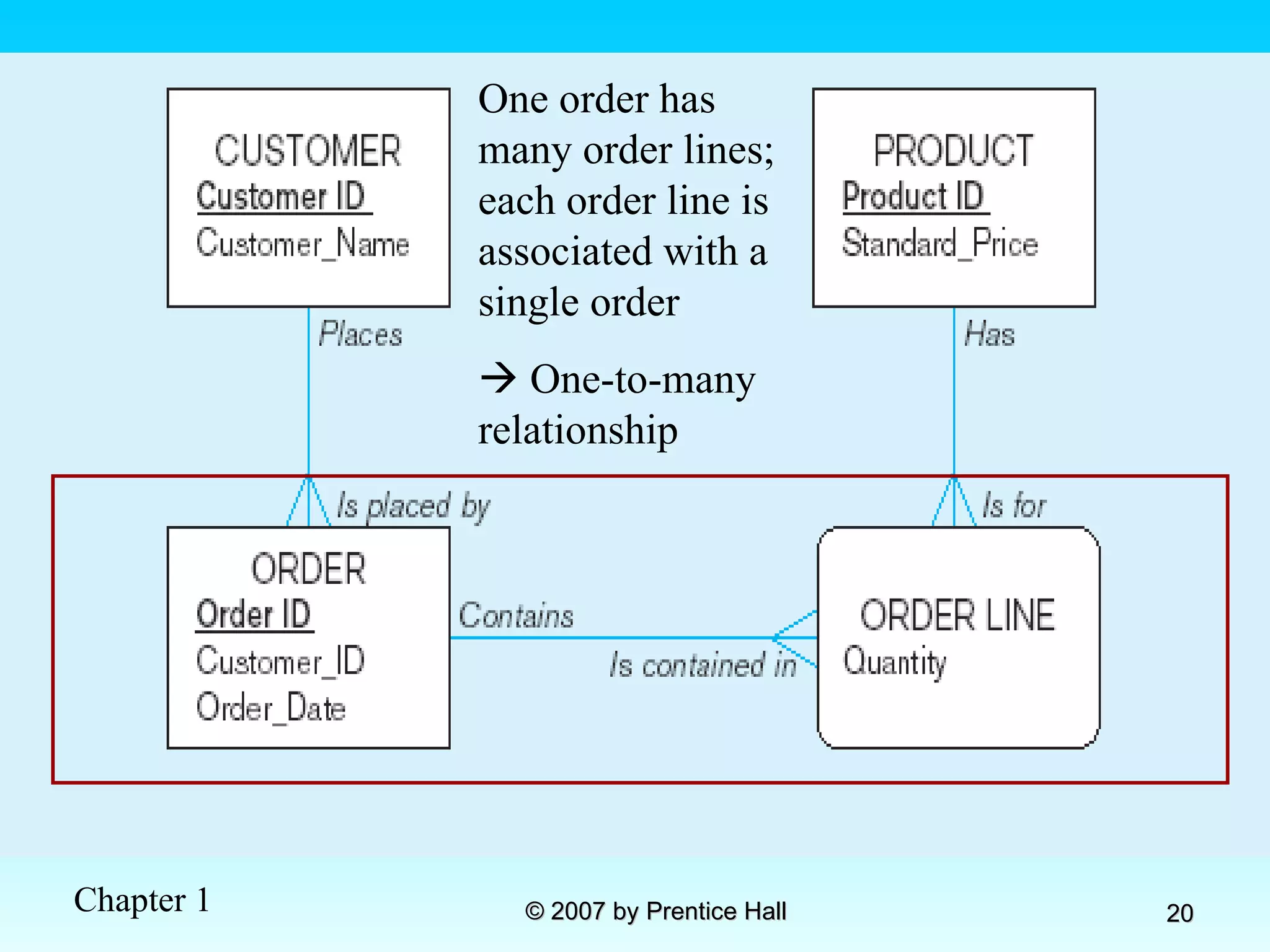
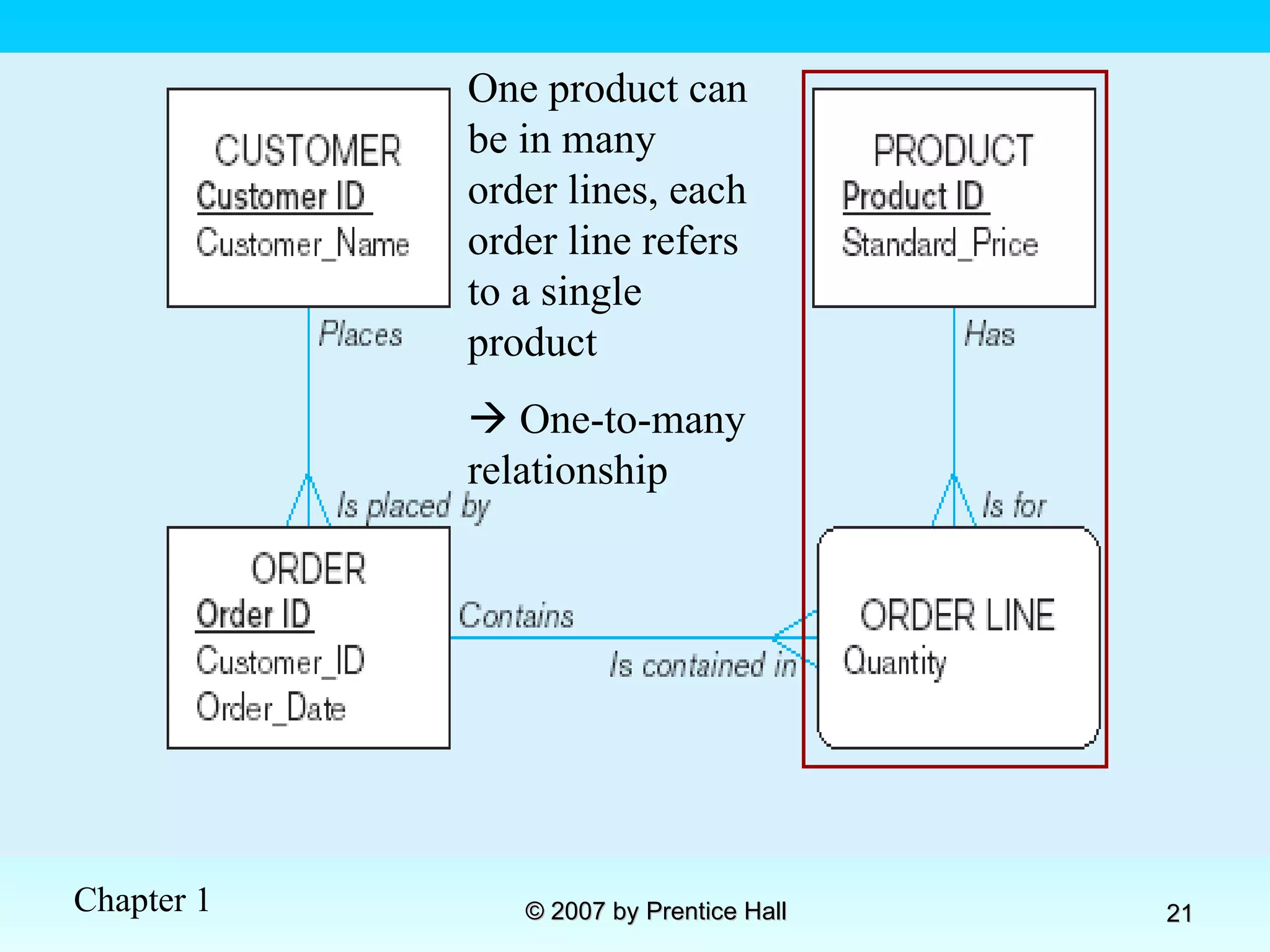
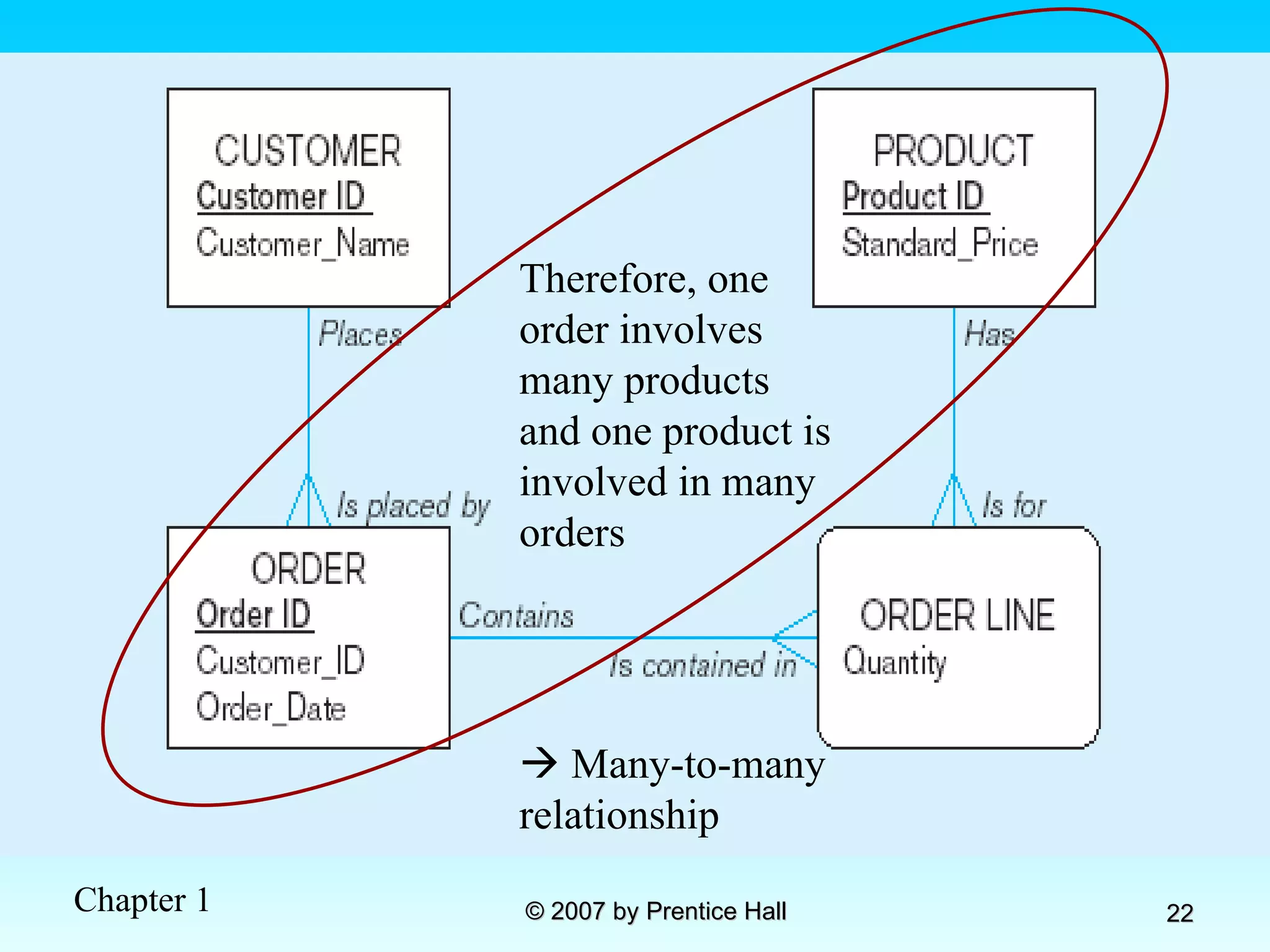
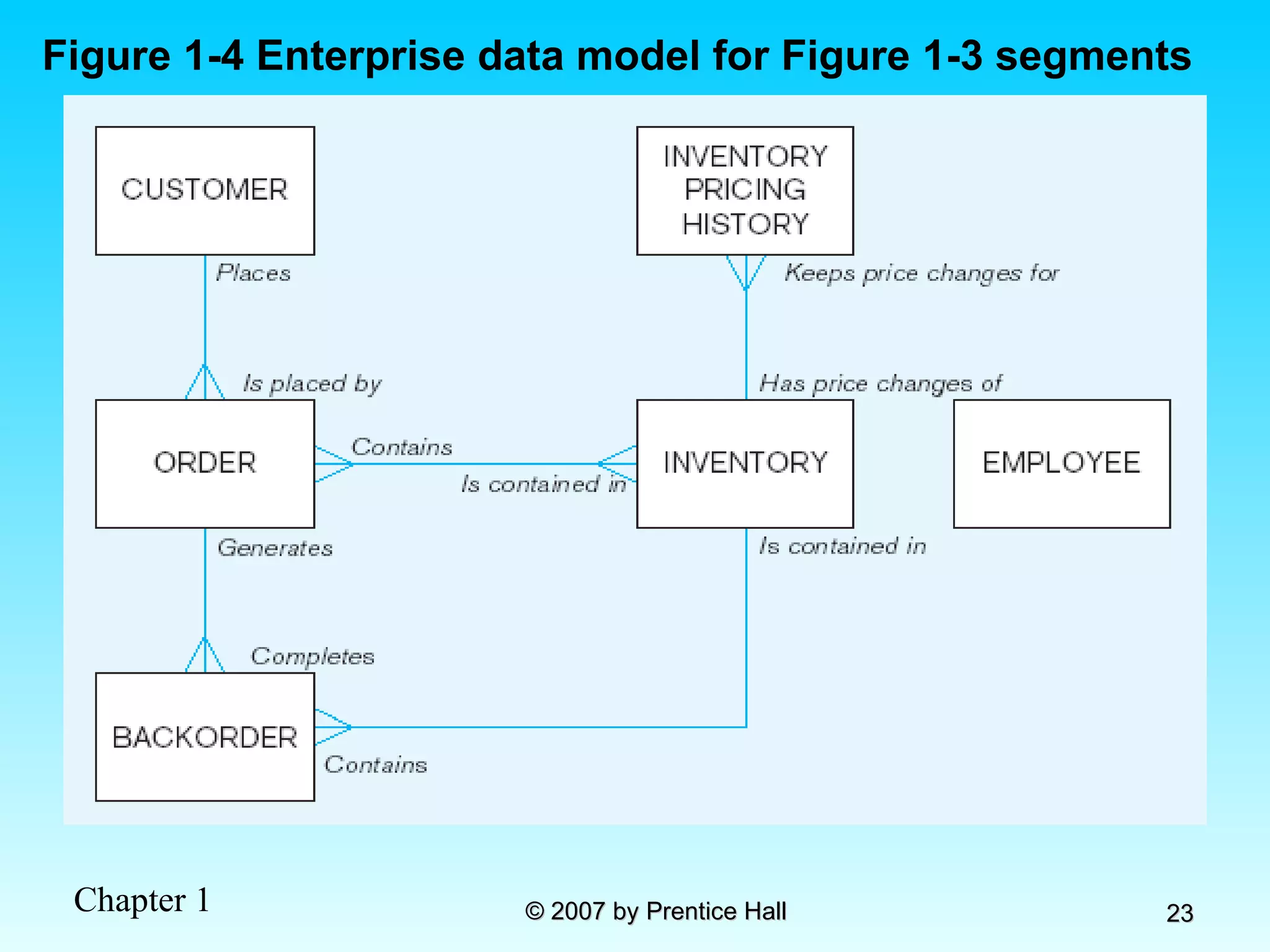















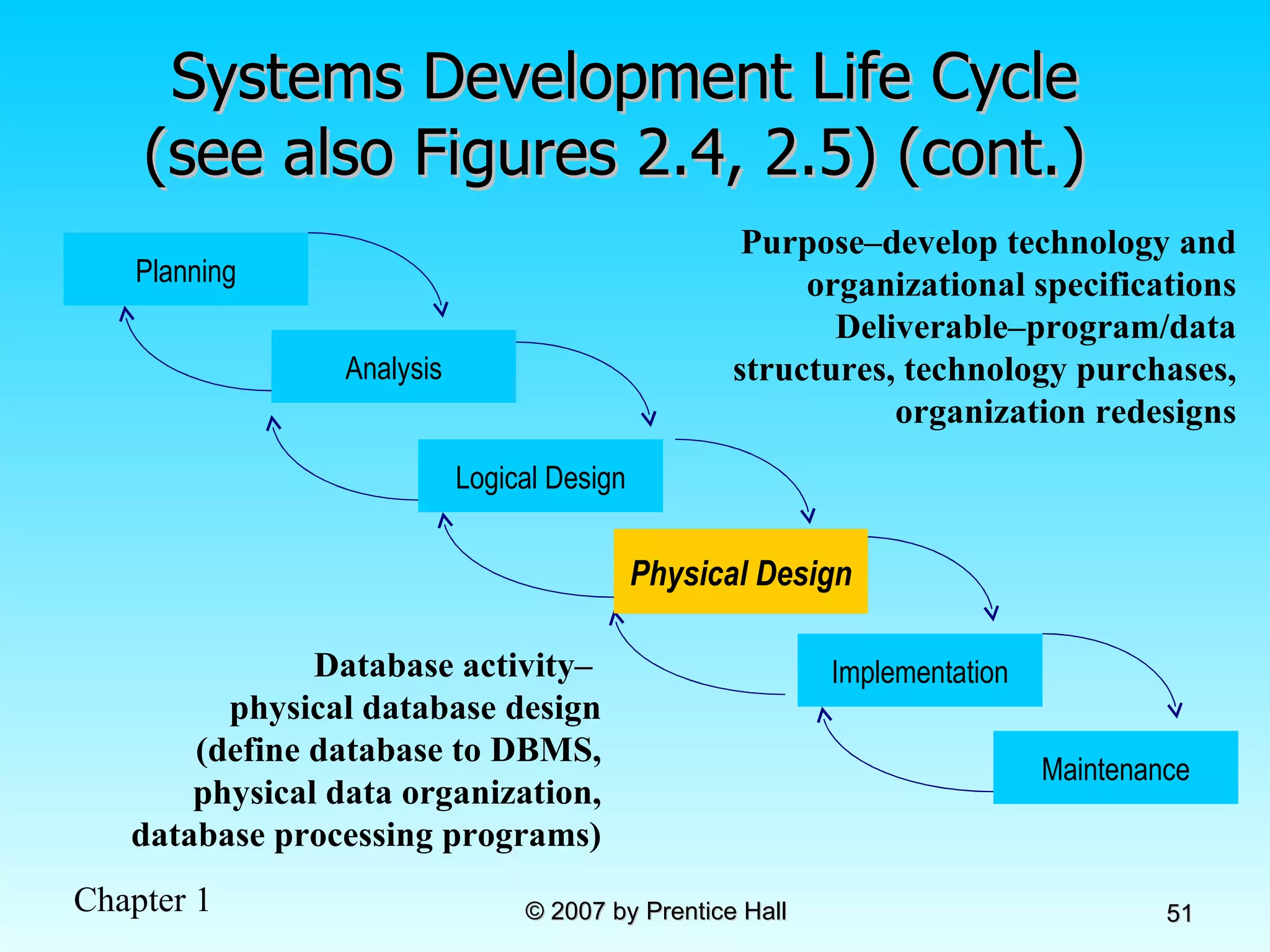
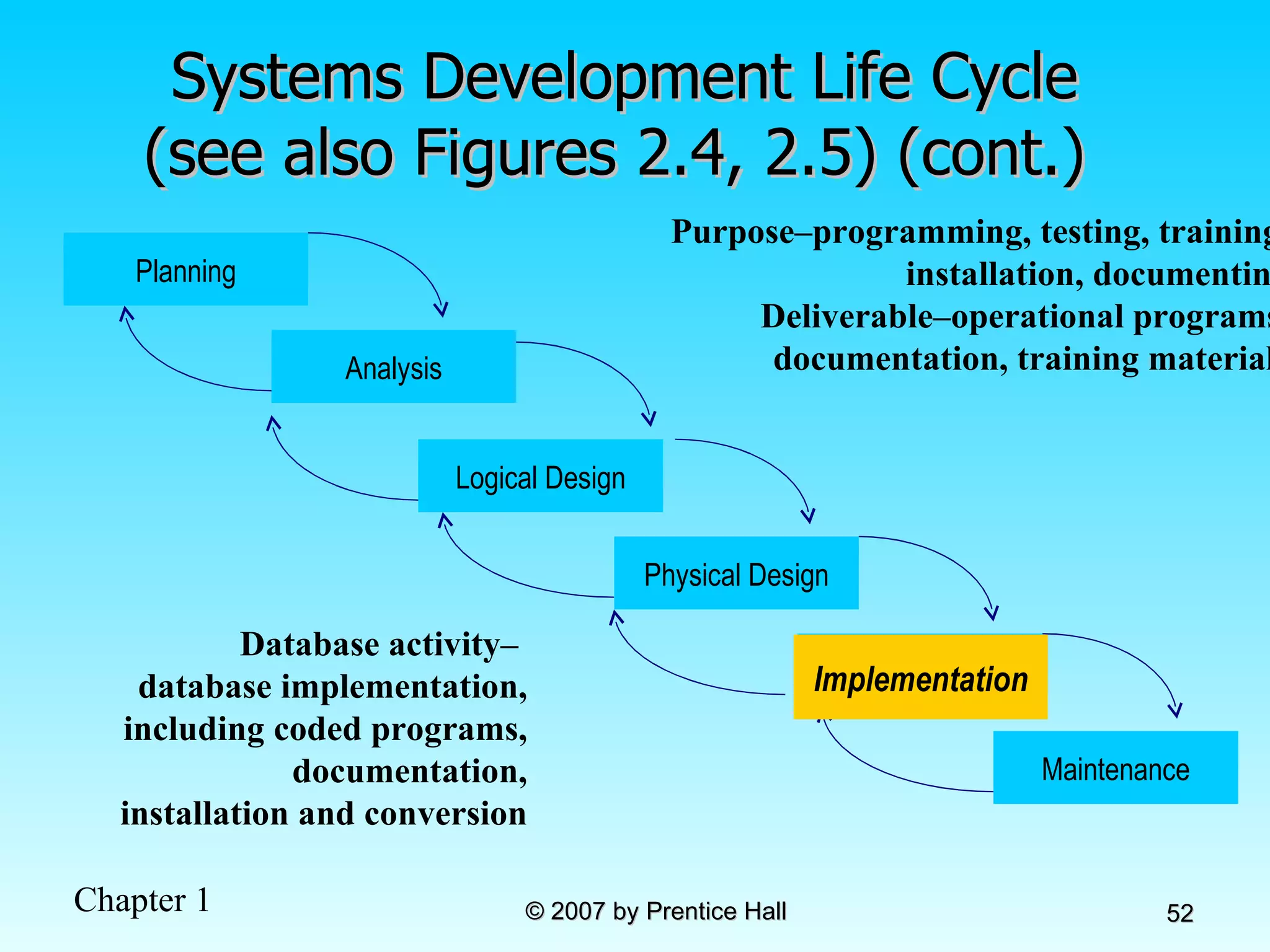
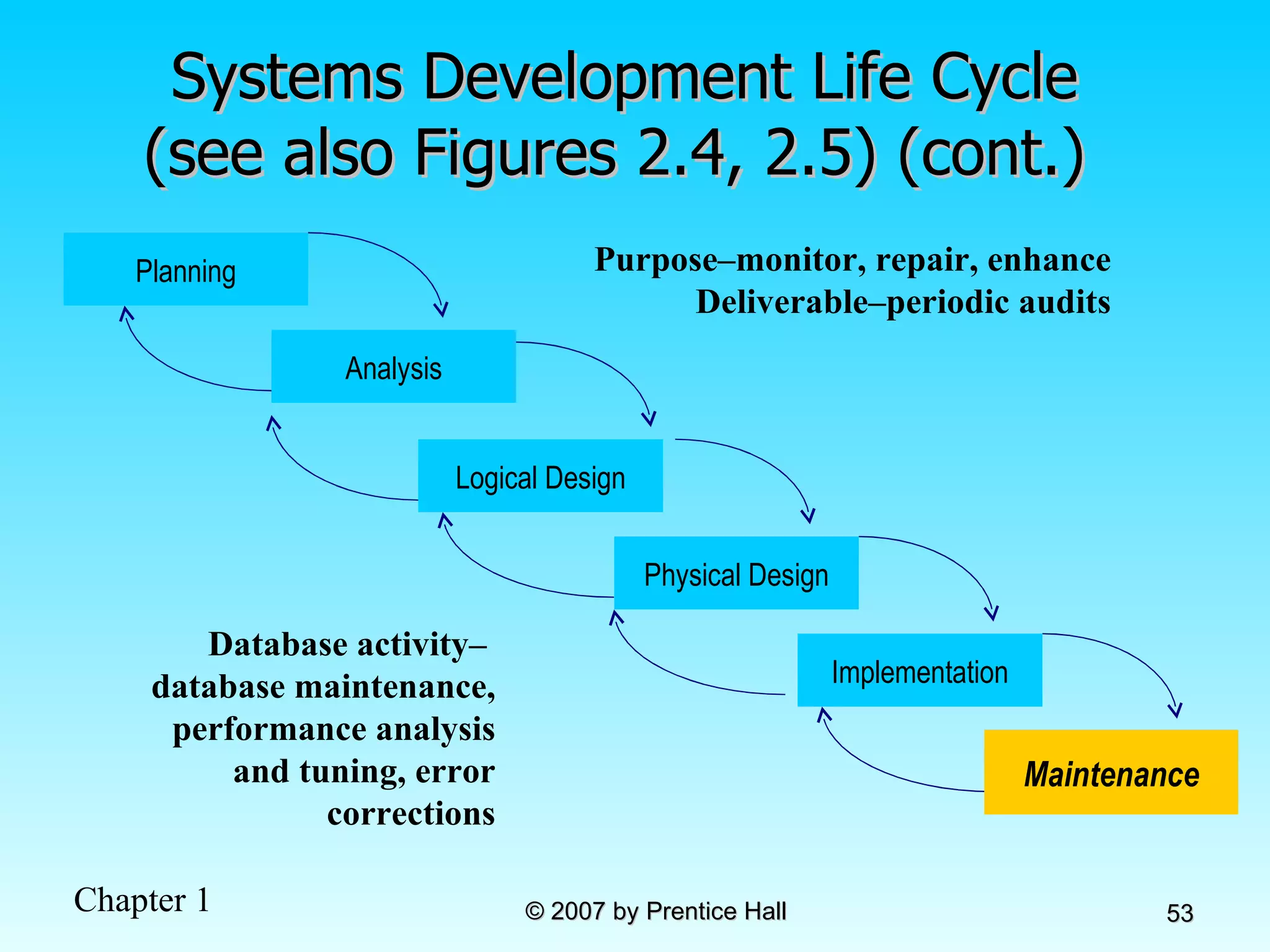
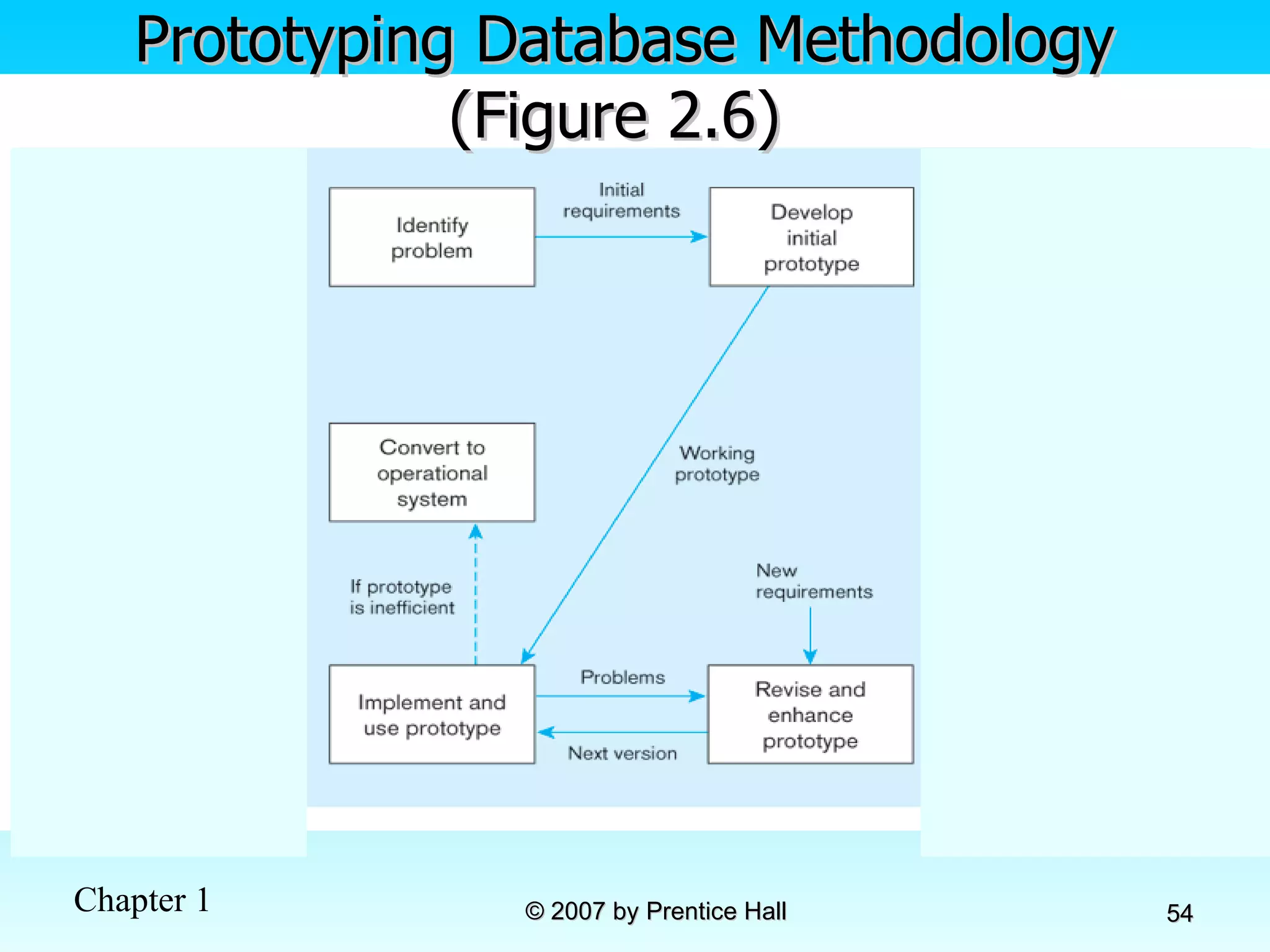
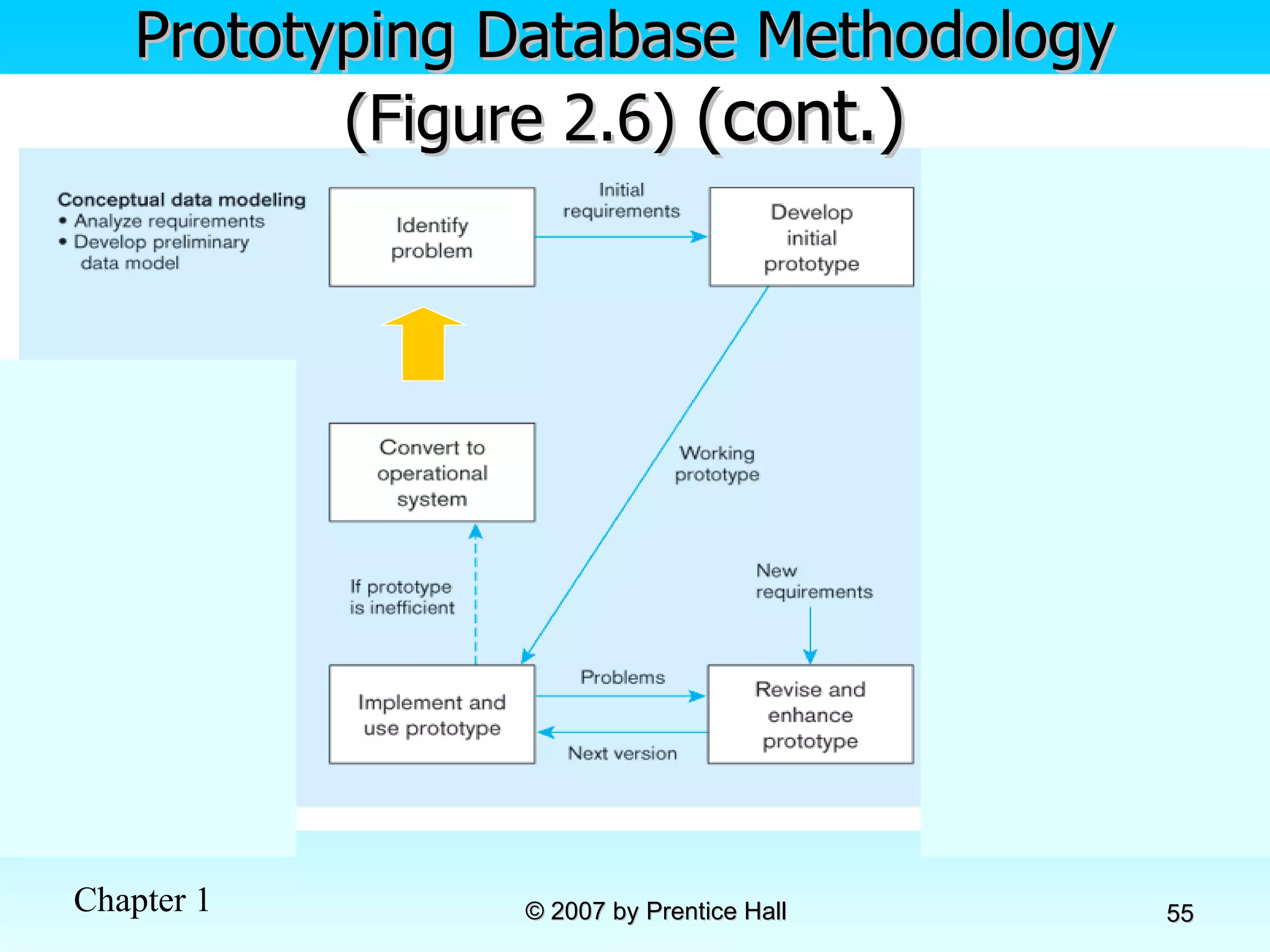
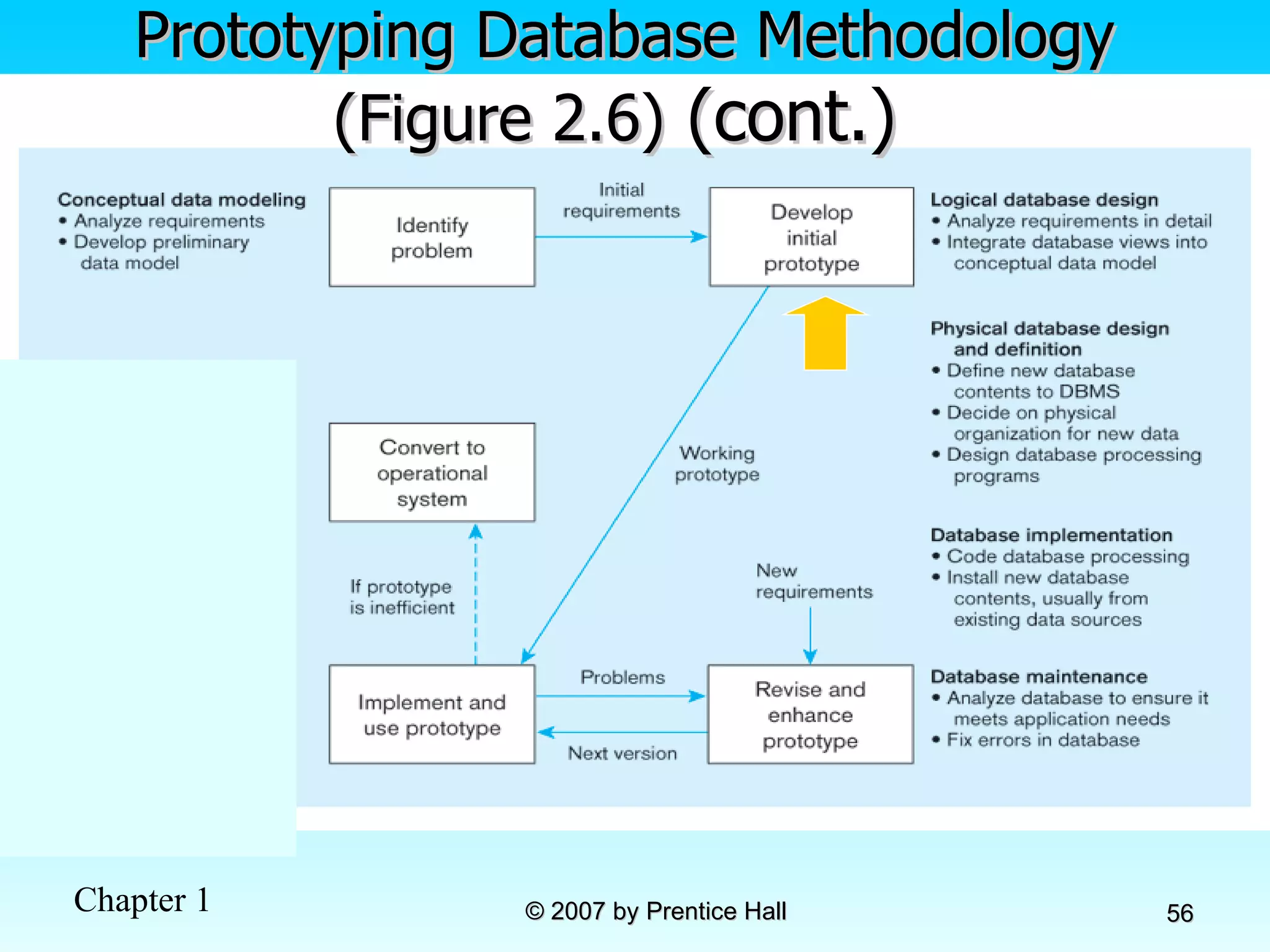
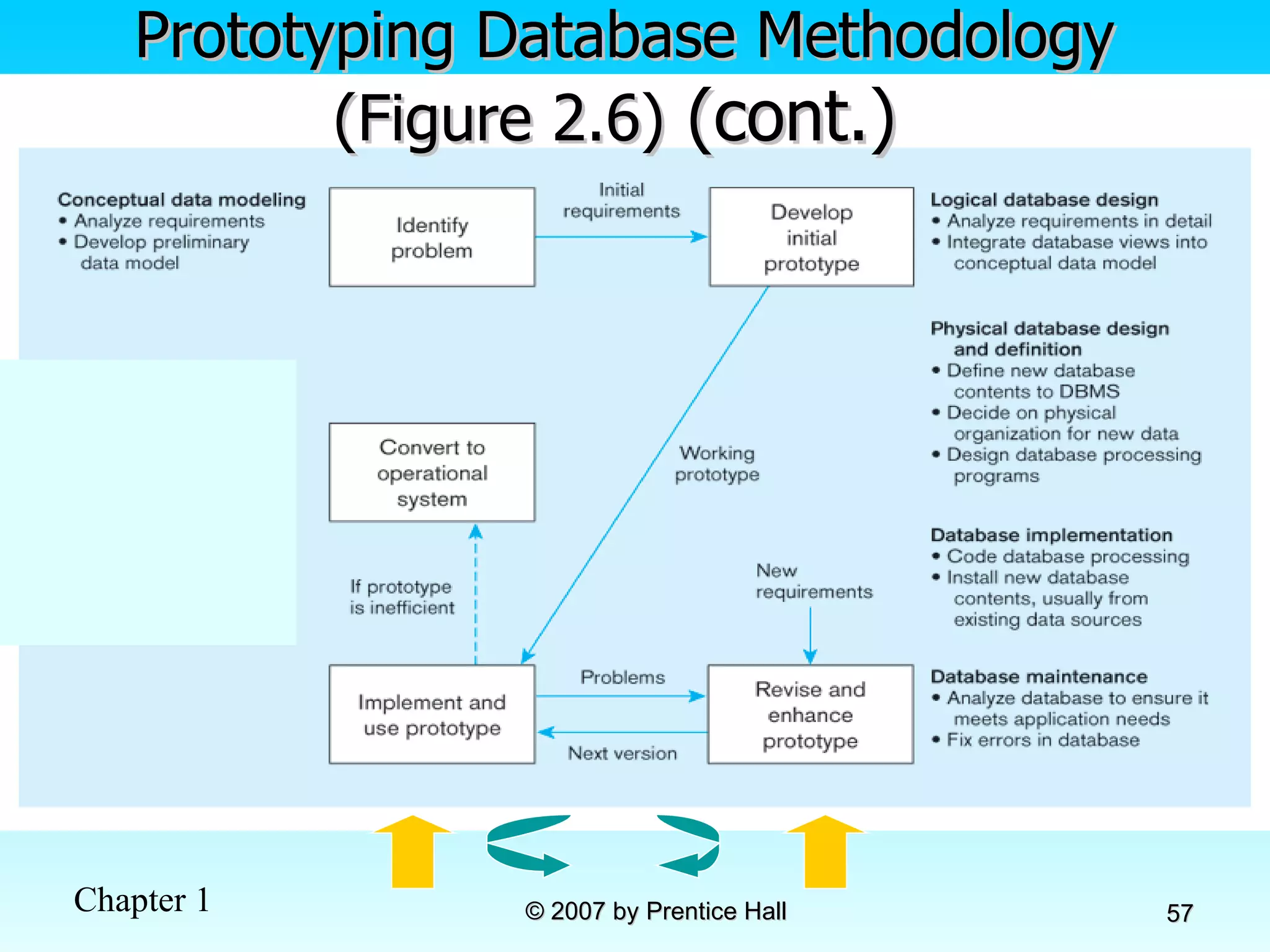
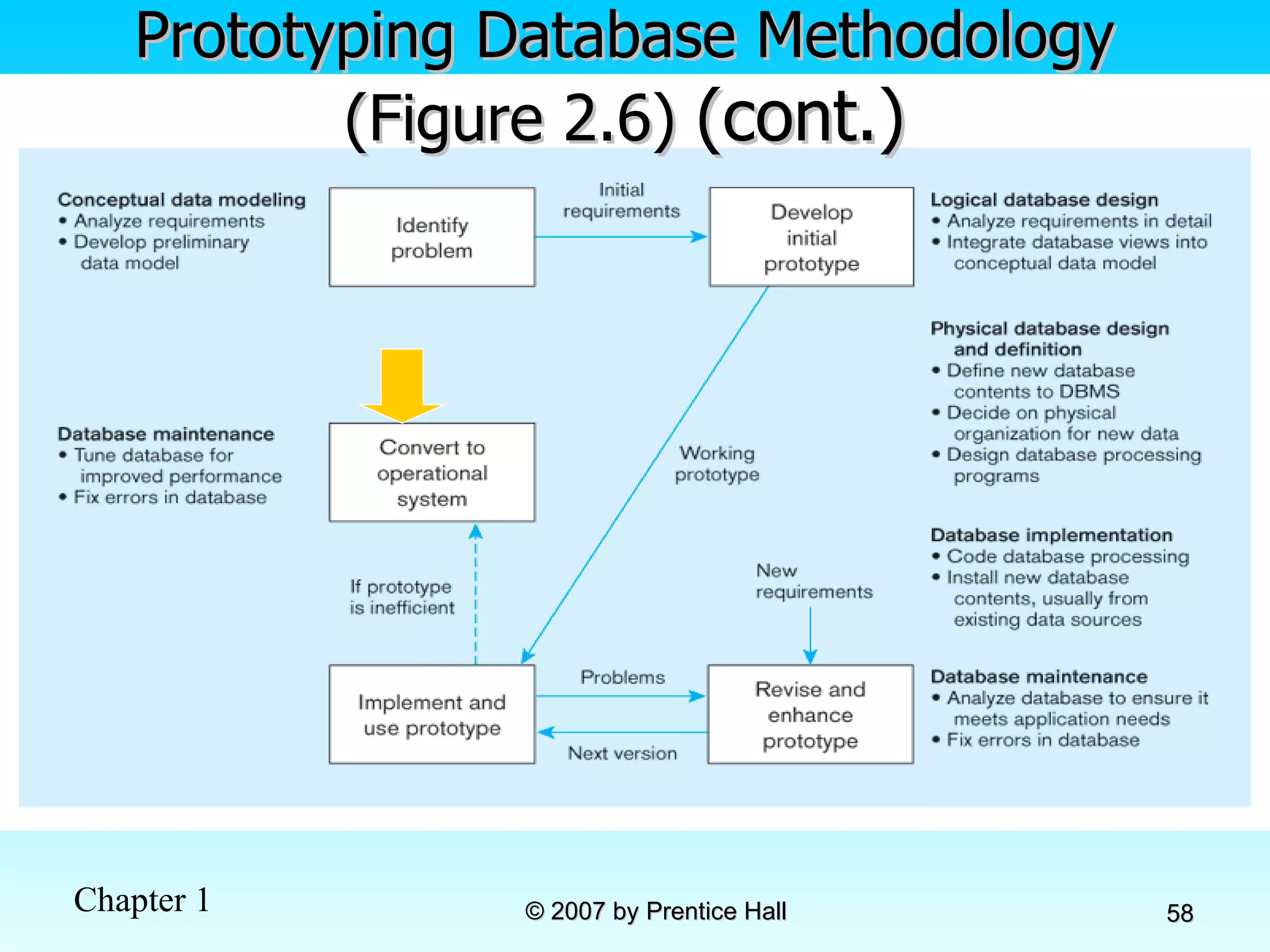





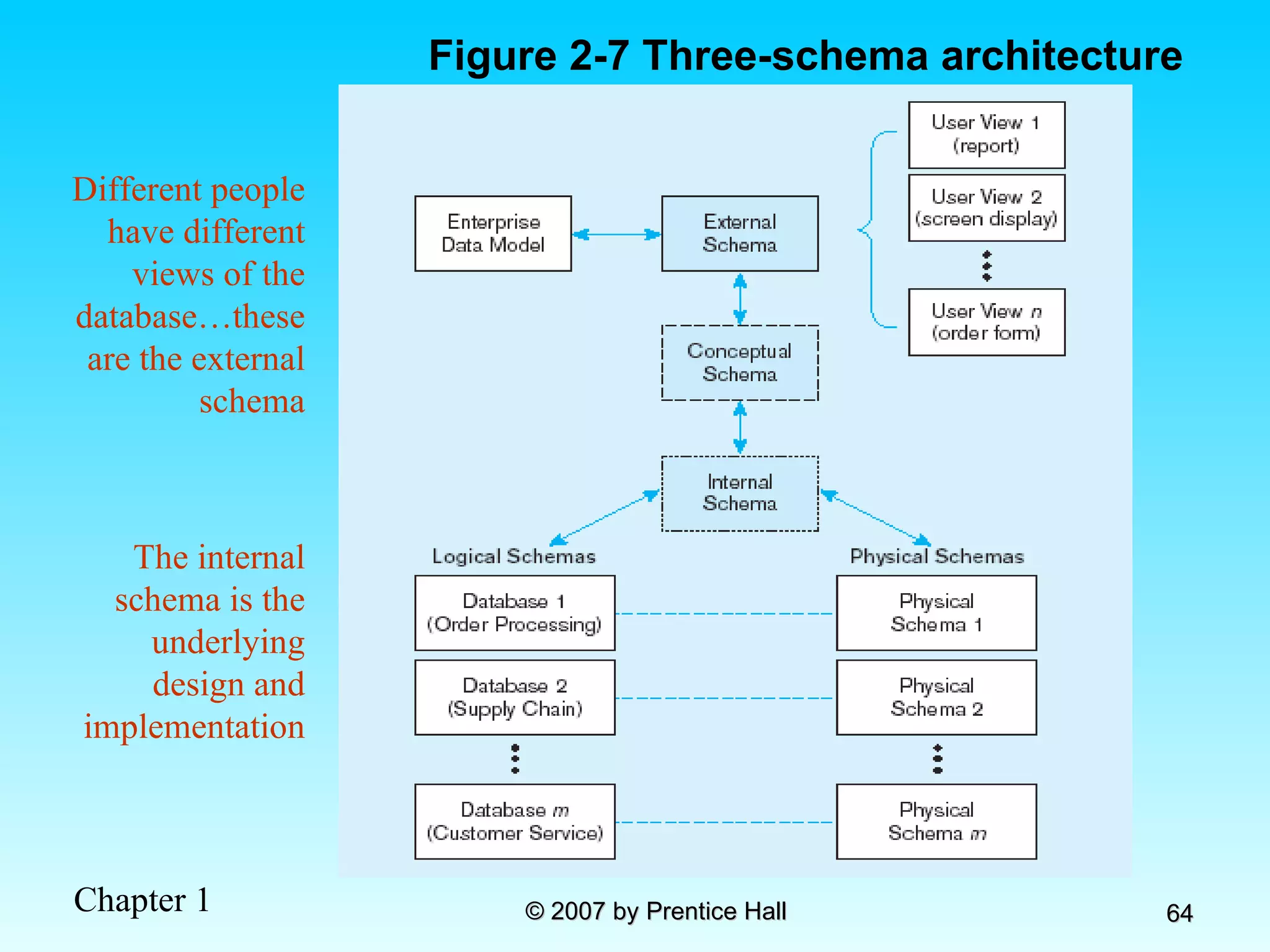
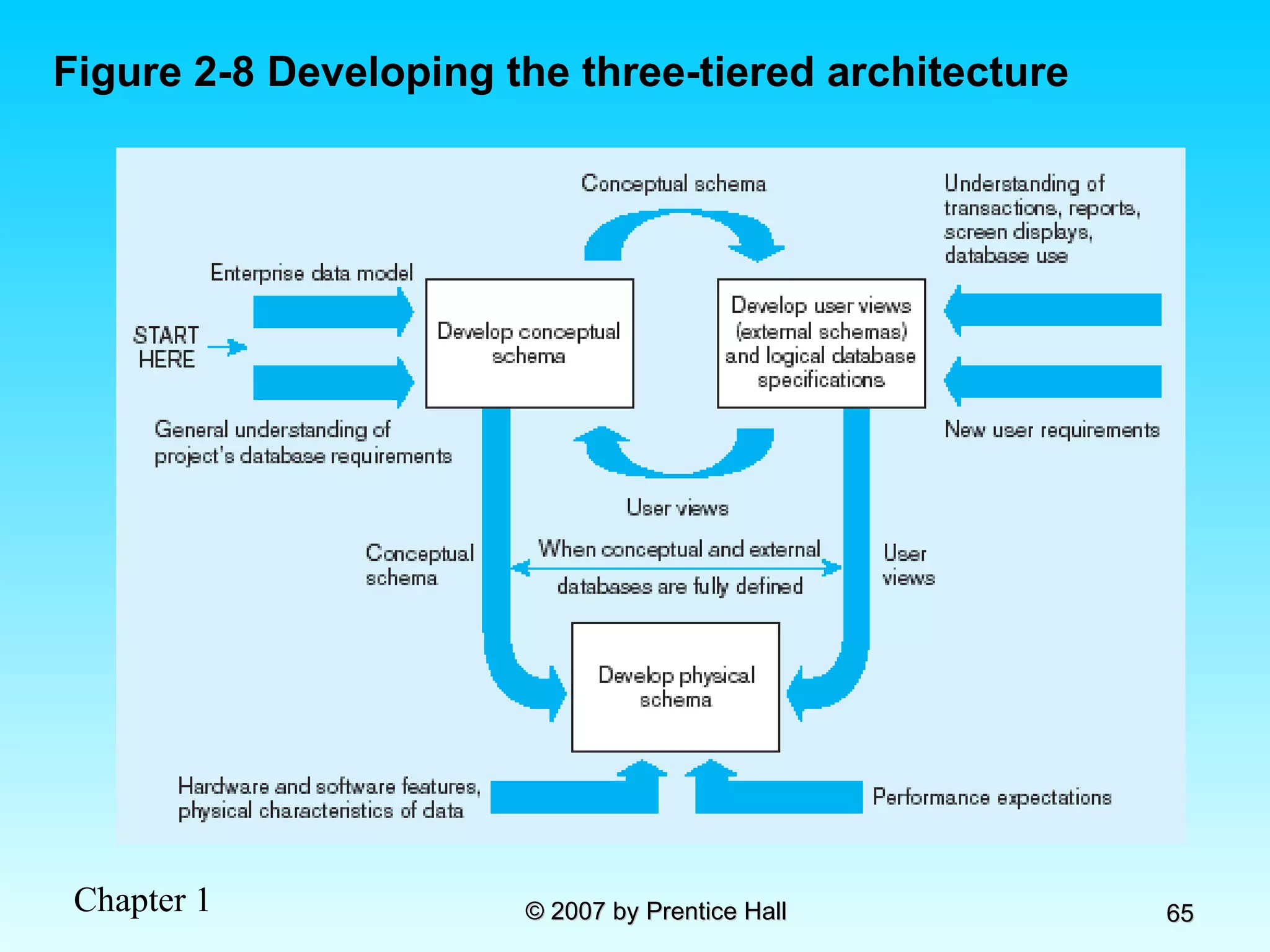
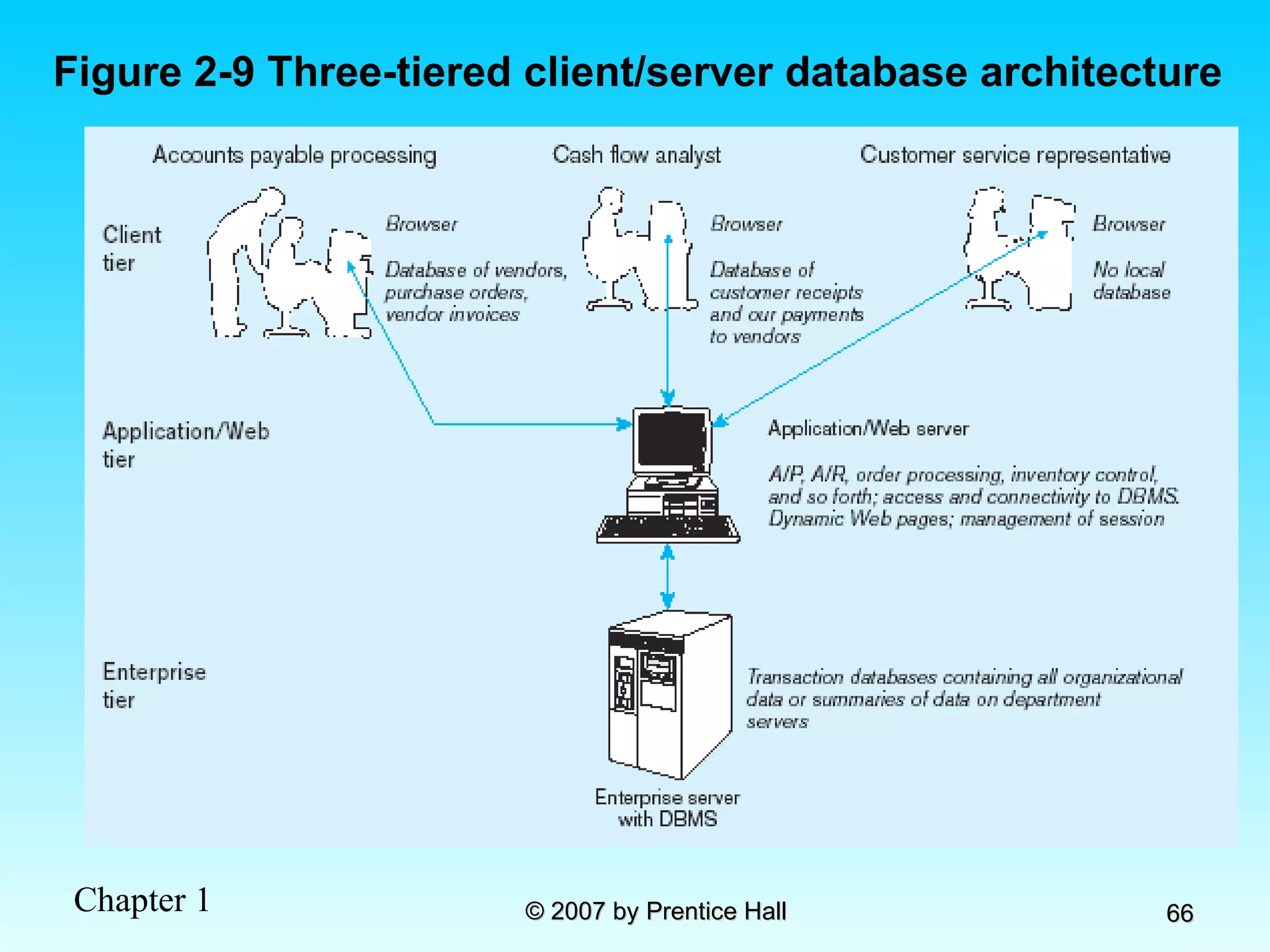
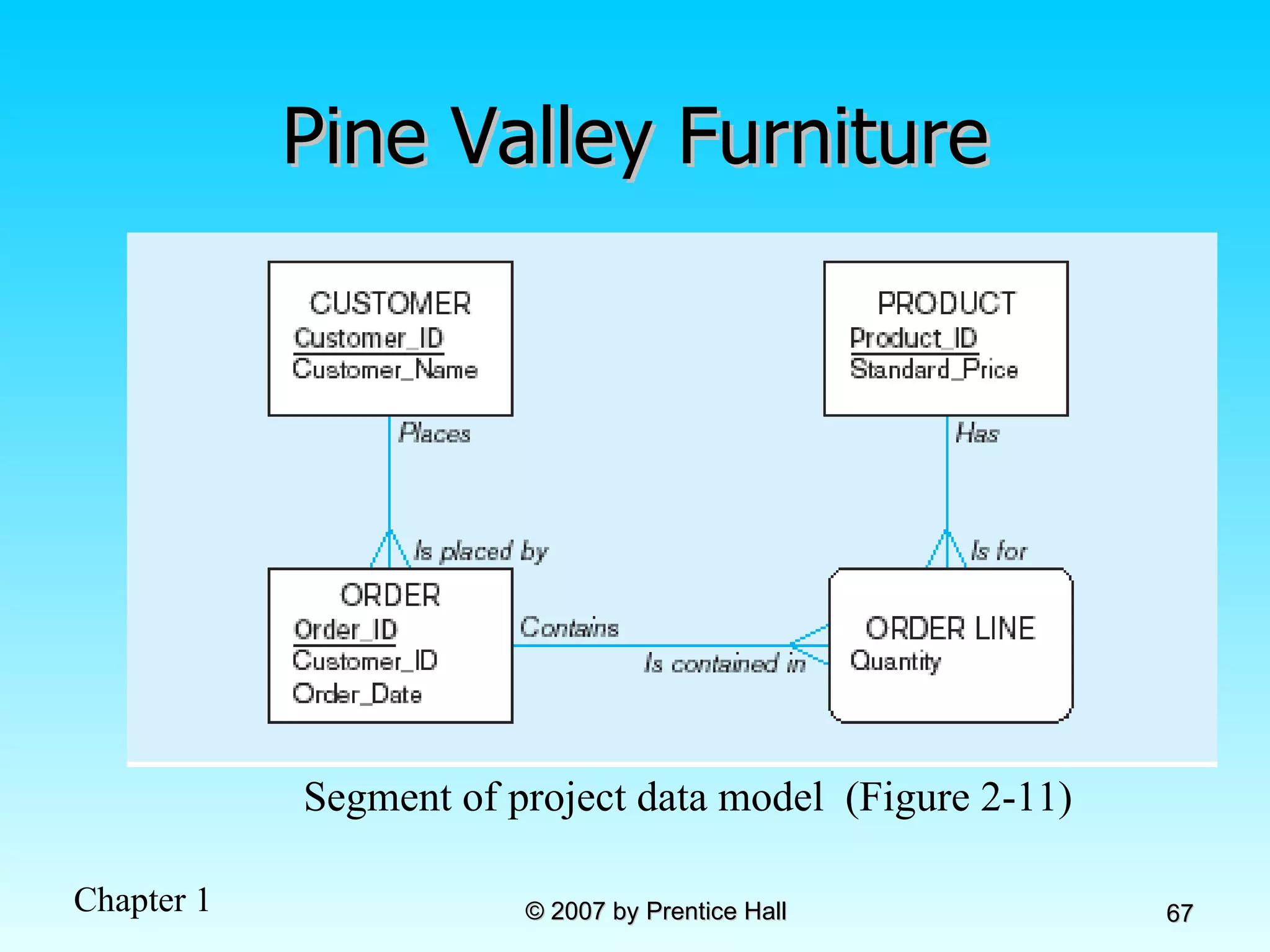




































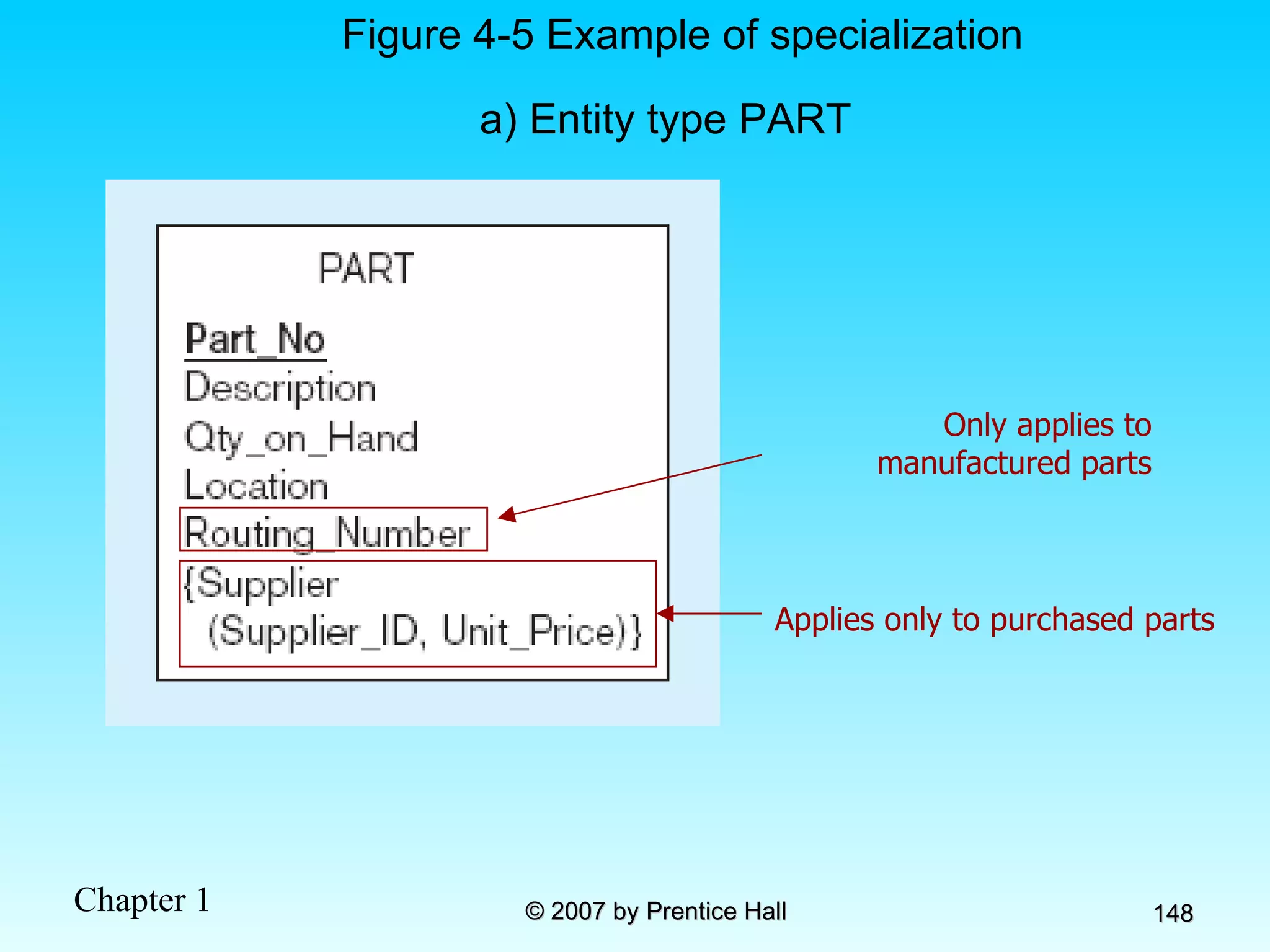
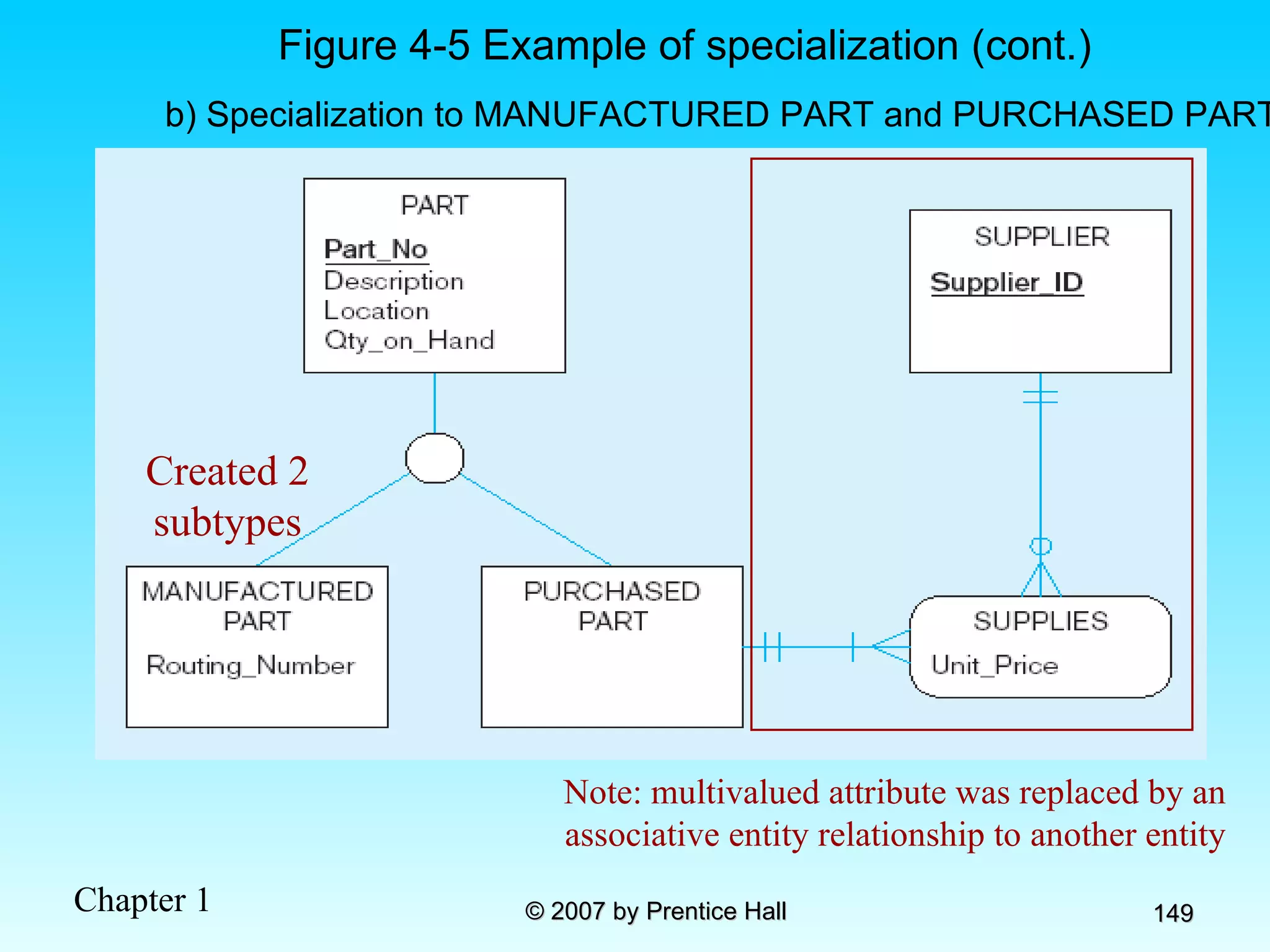


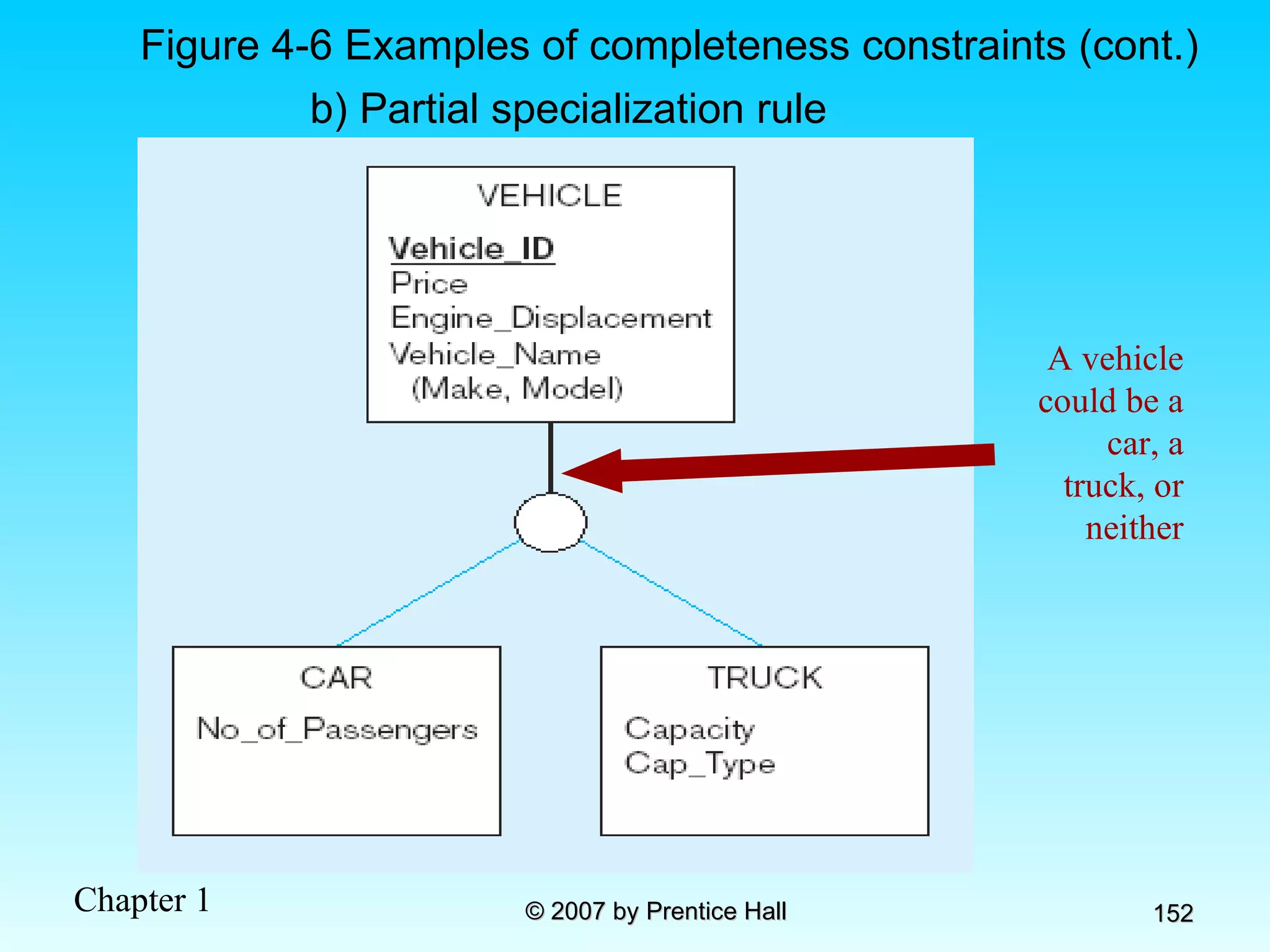

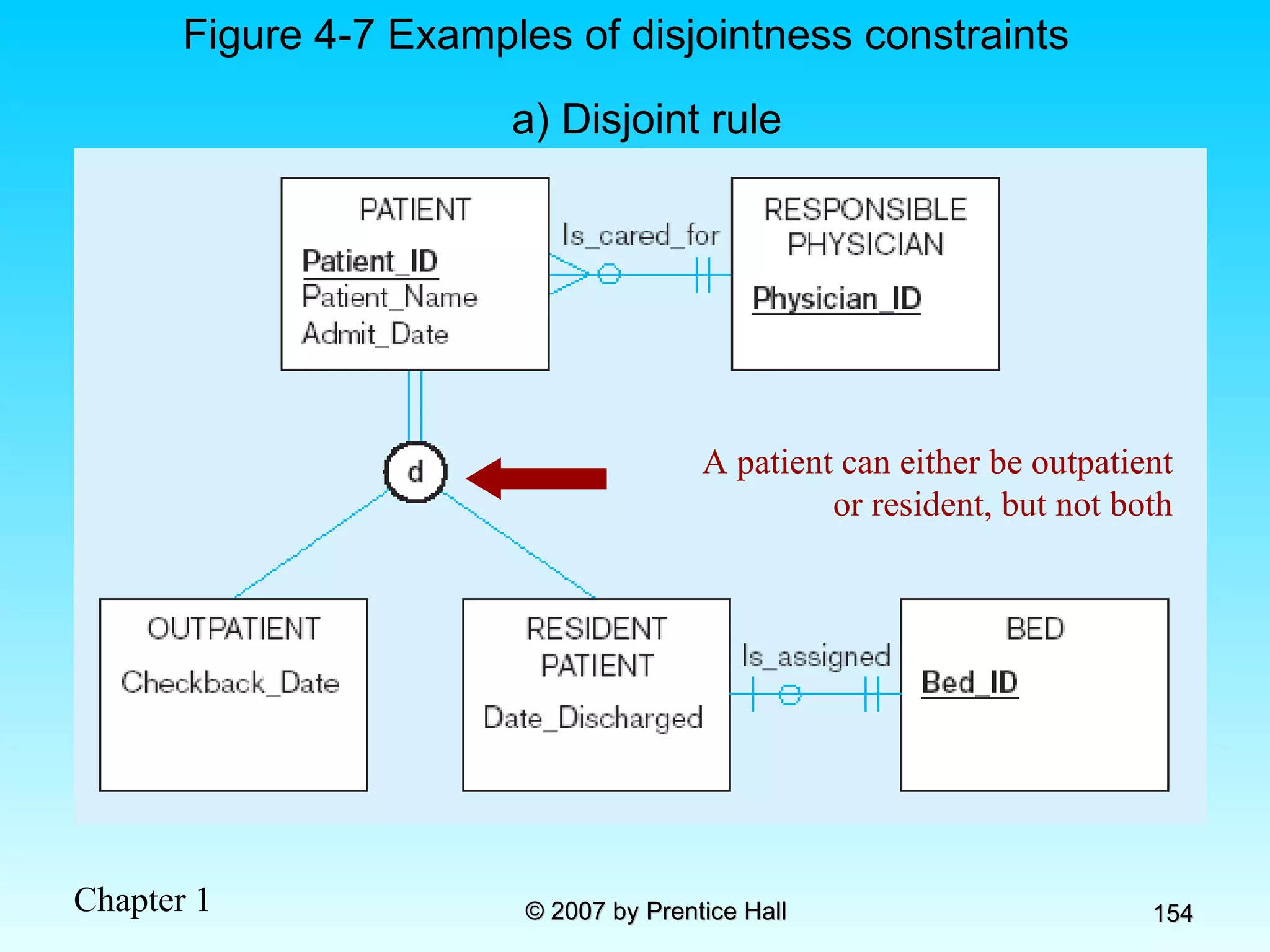





























































































































































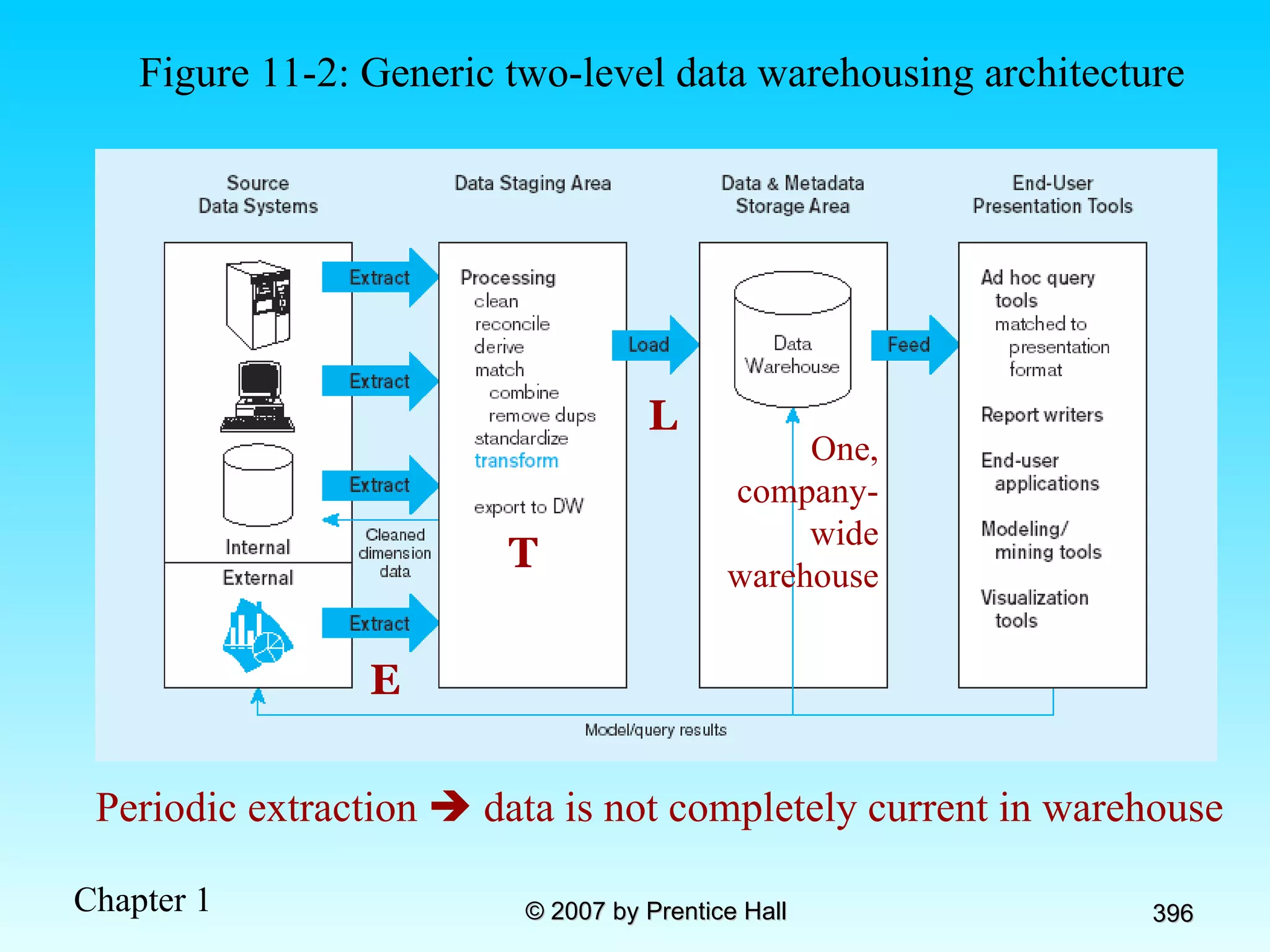
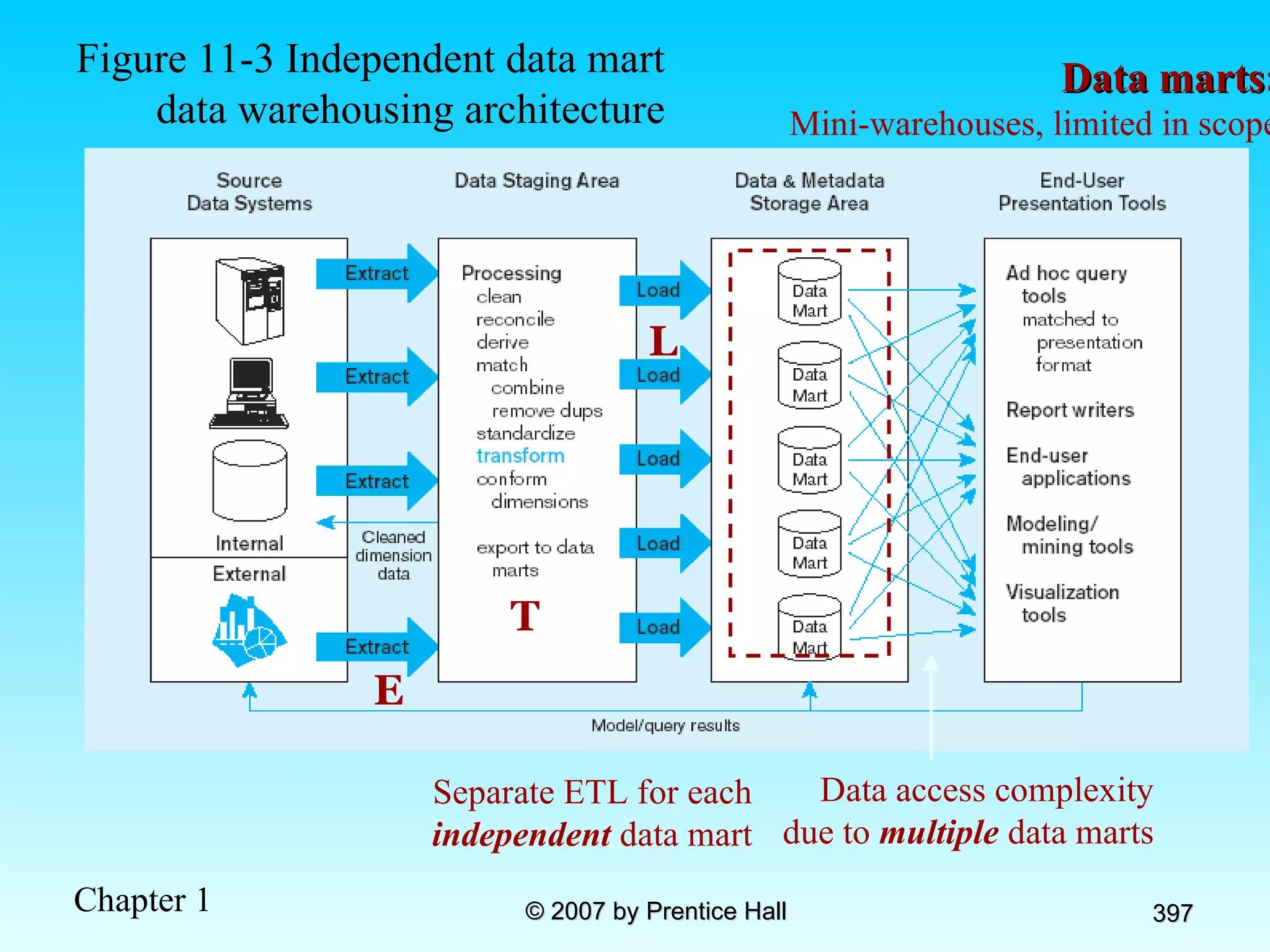
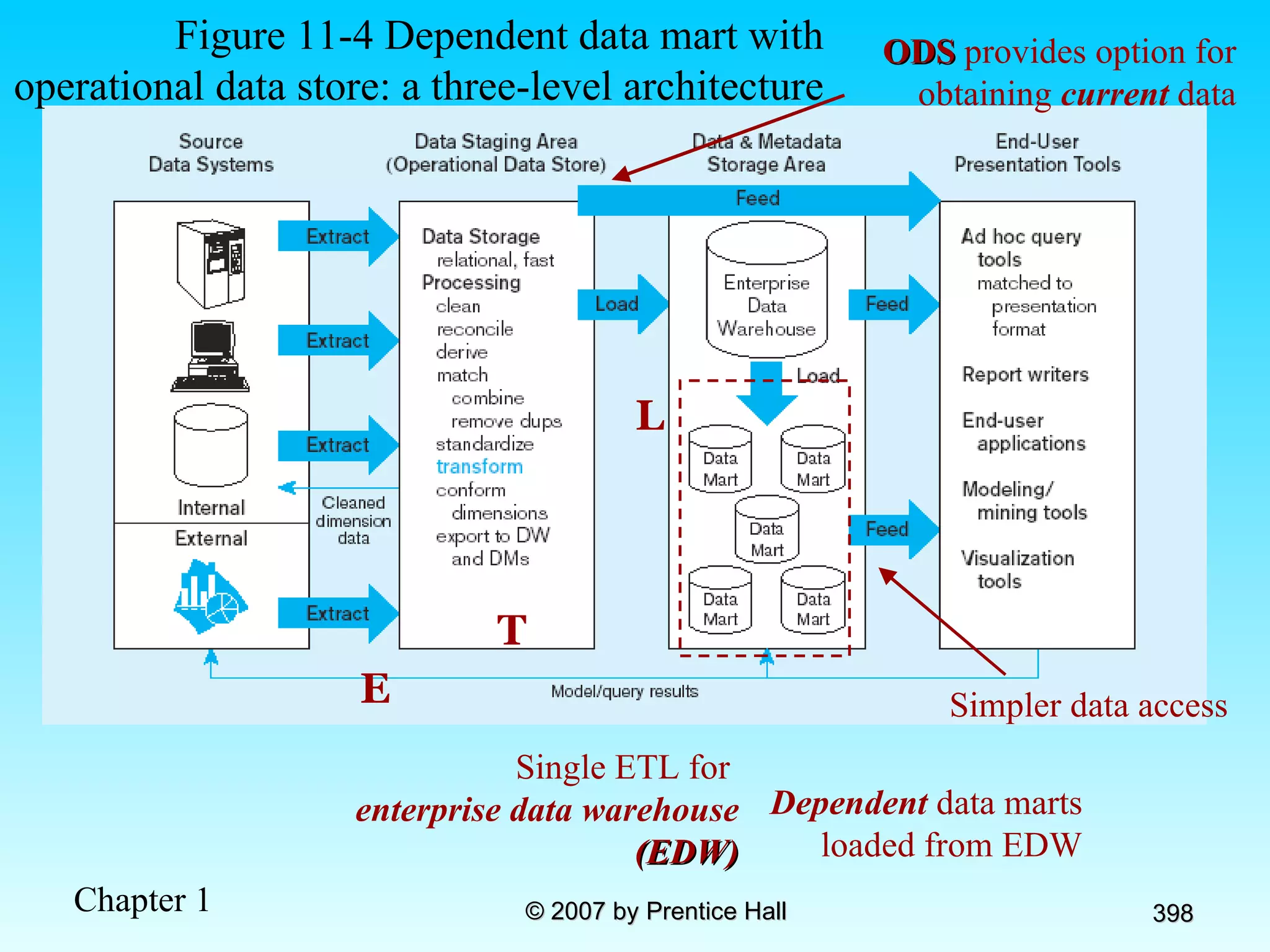
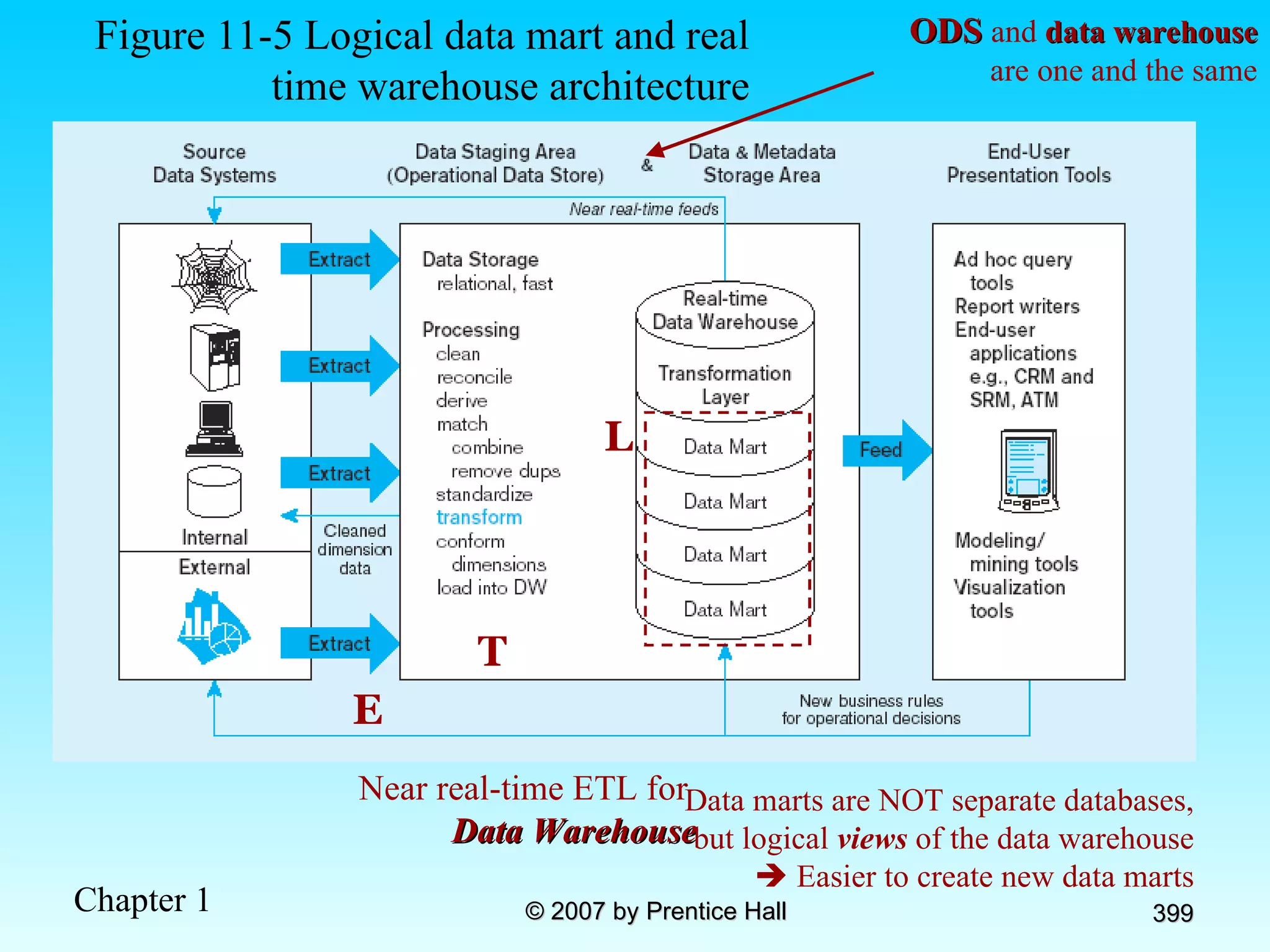














































![Data Models [DATABASE SYSTEMS: Design, Implementation, and Management]](https://cdn.slidesharecdn.com/ss_thumbnails/coronelpptch02-datamodels-190903105908-thumbnail.jpg?width=640&height=640&fit=bounds)


































































