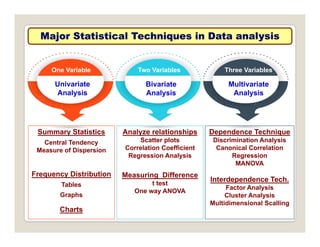
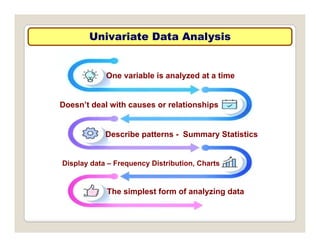
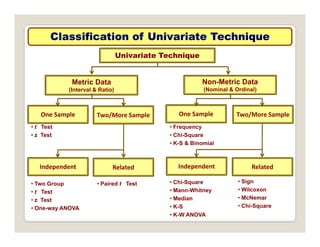
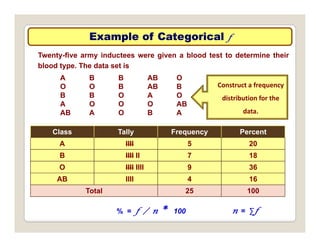
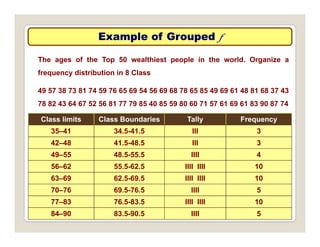
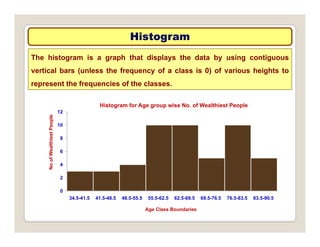
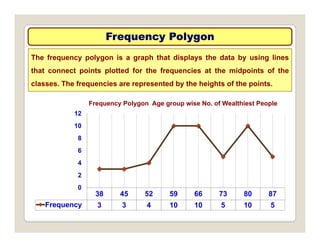
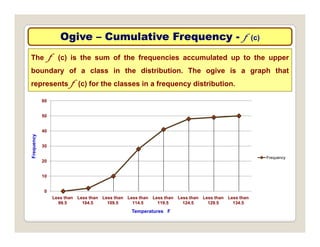
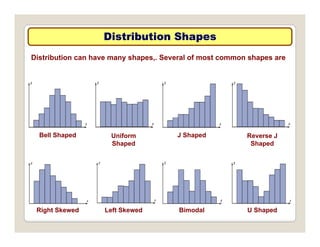
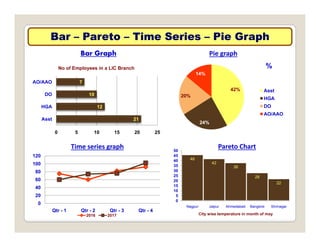
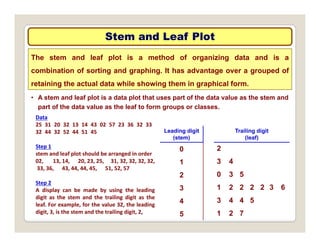
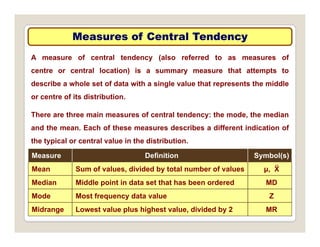
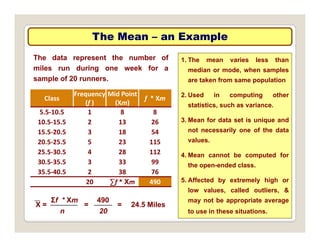
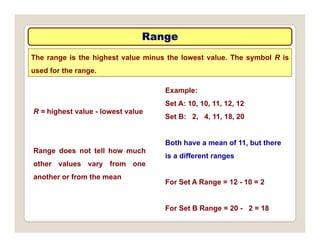
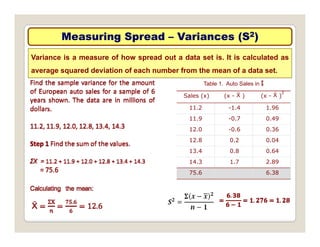
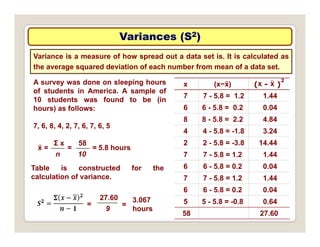
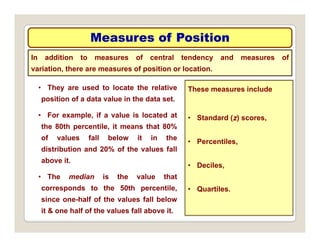
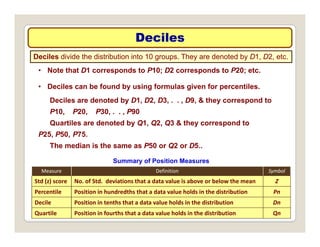
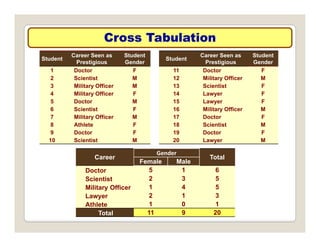
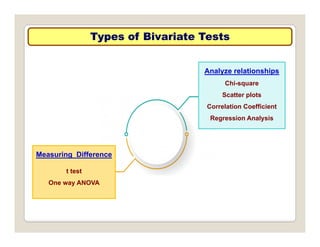
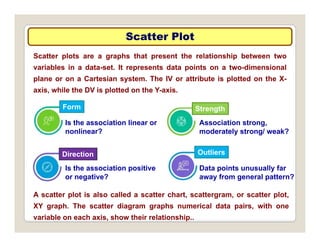
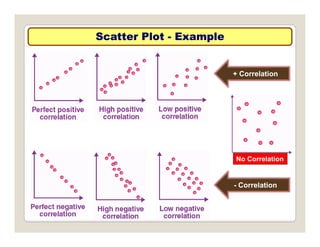
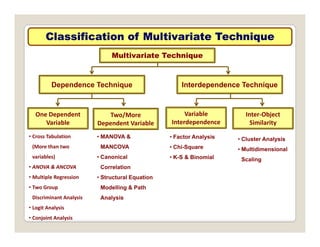
The document discusses various statistical techniques for data analysis, including univariate, bivariate, and multivariate analysis, as well as descriptive and inferential statistics. It emphasizes the importance of frequency distributions, measures of central tendency (mean, median, mode), and presents different types of graphical representations for data. Additionally, it covers measures of variability and outlines various methods for summarizing and analyzing data effectively.




















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)



