Downloaded 24 times


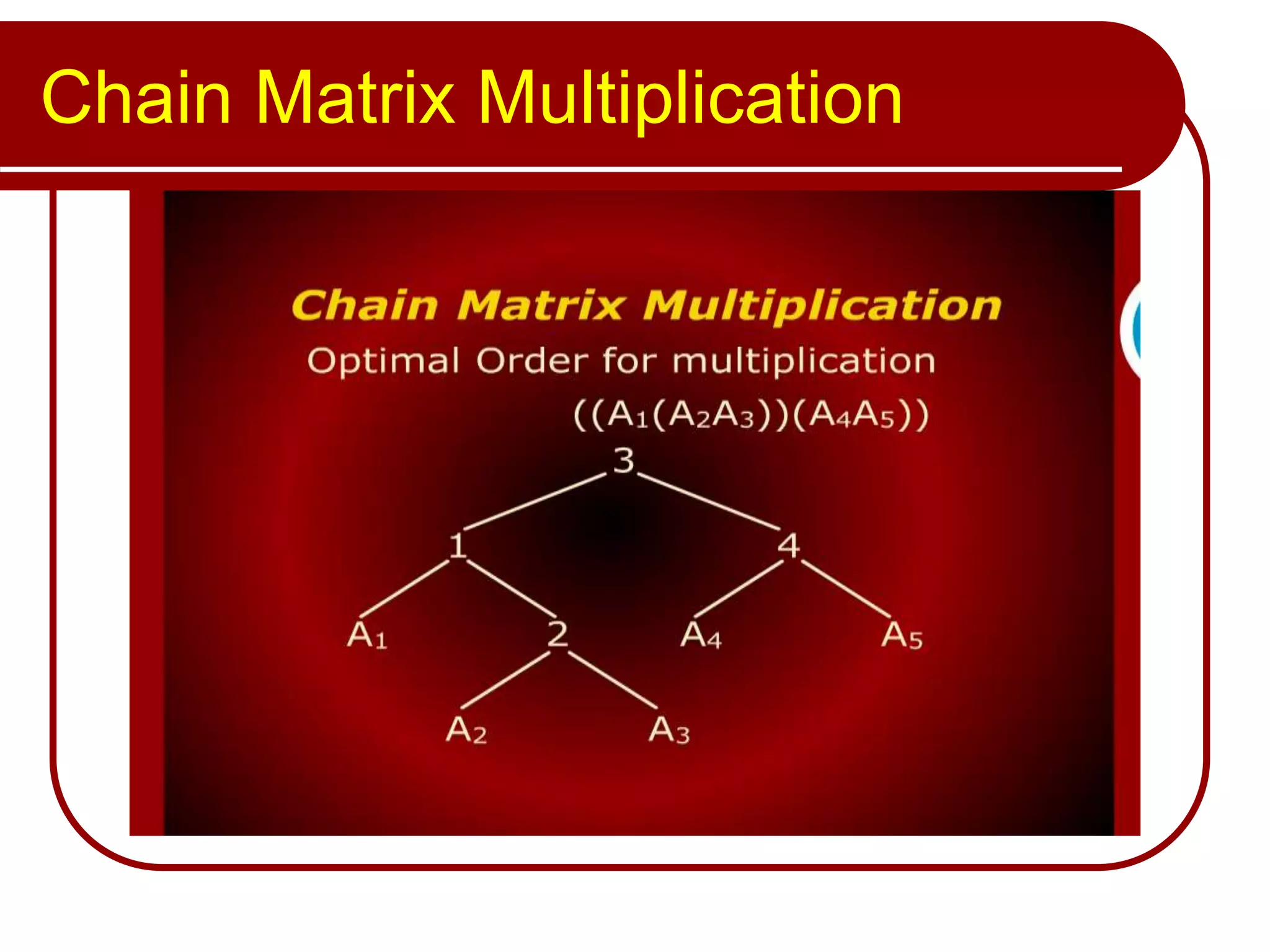





















The document discusses algorithms for chain matrix multiplication and the 0/1 knapsack problem. It covers the chain matrix multiply algorithm, the 0/1 knapsack problem, and a dynamic programming approach for solving the 0/1 knapsack problem.



































































