Download as PDF, PPTX




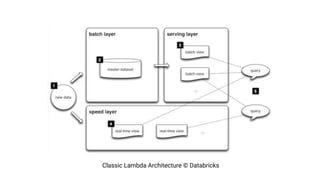


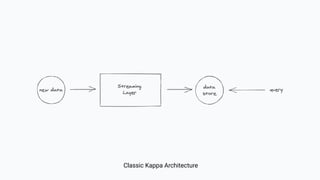








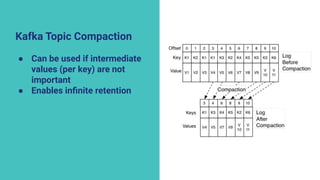
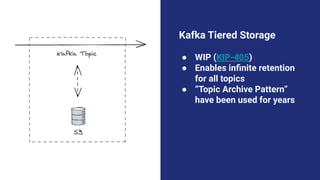

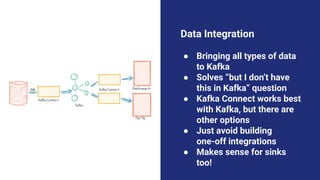
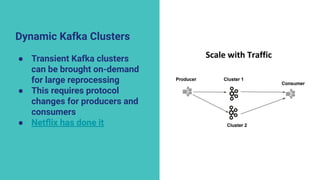

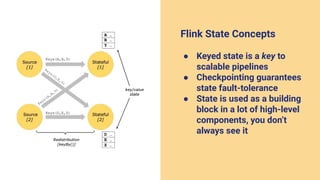

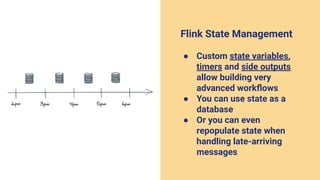






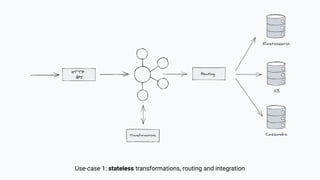
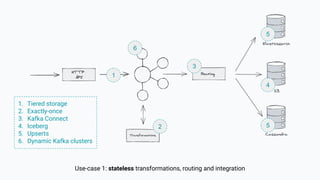
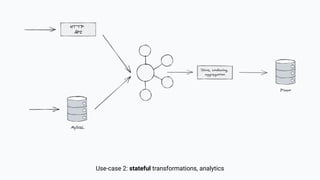
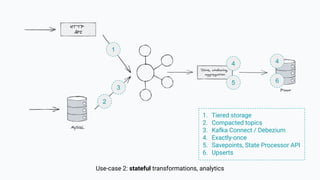


The document discusses the transition from lambda to kappa architecture in data engineering, advocating for streaming data processing due to its advantages in data availability, consistency, and handling late-arriving data. It highlights modern frameworks like Kafka and Flink that facilitate operations, observability, and complex state management necessary for effective streaming pipelines. Additionally, it addresses various architectural concerns and provides use cases demonstrating the application of kappa architecture components and techniques.



















































































