Download as PDF, PPTX





























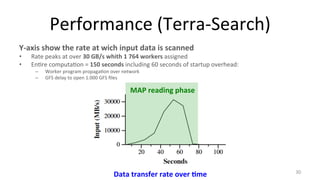
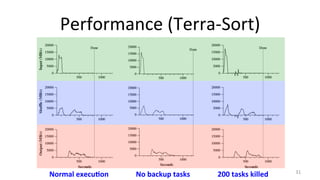







This document provides an overview of the MapReduce programming model and implementation developed by Google for processing large data sets. It outlines the programming model that involves user-defined map and reduce functions, the architecture for execution across clusters, and various refinements like fault tolerance and performance optimizations. The key features discussed include data partitioning, task scheduling, handling of machine failures, and improvements for user-defined functions and data formats.


















![Acmp study guide_d[1]](https://cdn.slidesharecdn.com/ss_thumbnails/acmpstudyguided1-130813141231-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)









































