Download to read offline












![Data sketches
[ Amanda Cox, New York Times ]](https://image.slidesharecdn.com/quantviz-120628100512-phpapp02/75/Quant-viz-26-2048.jpg)


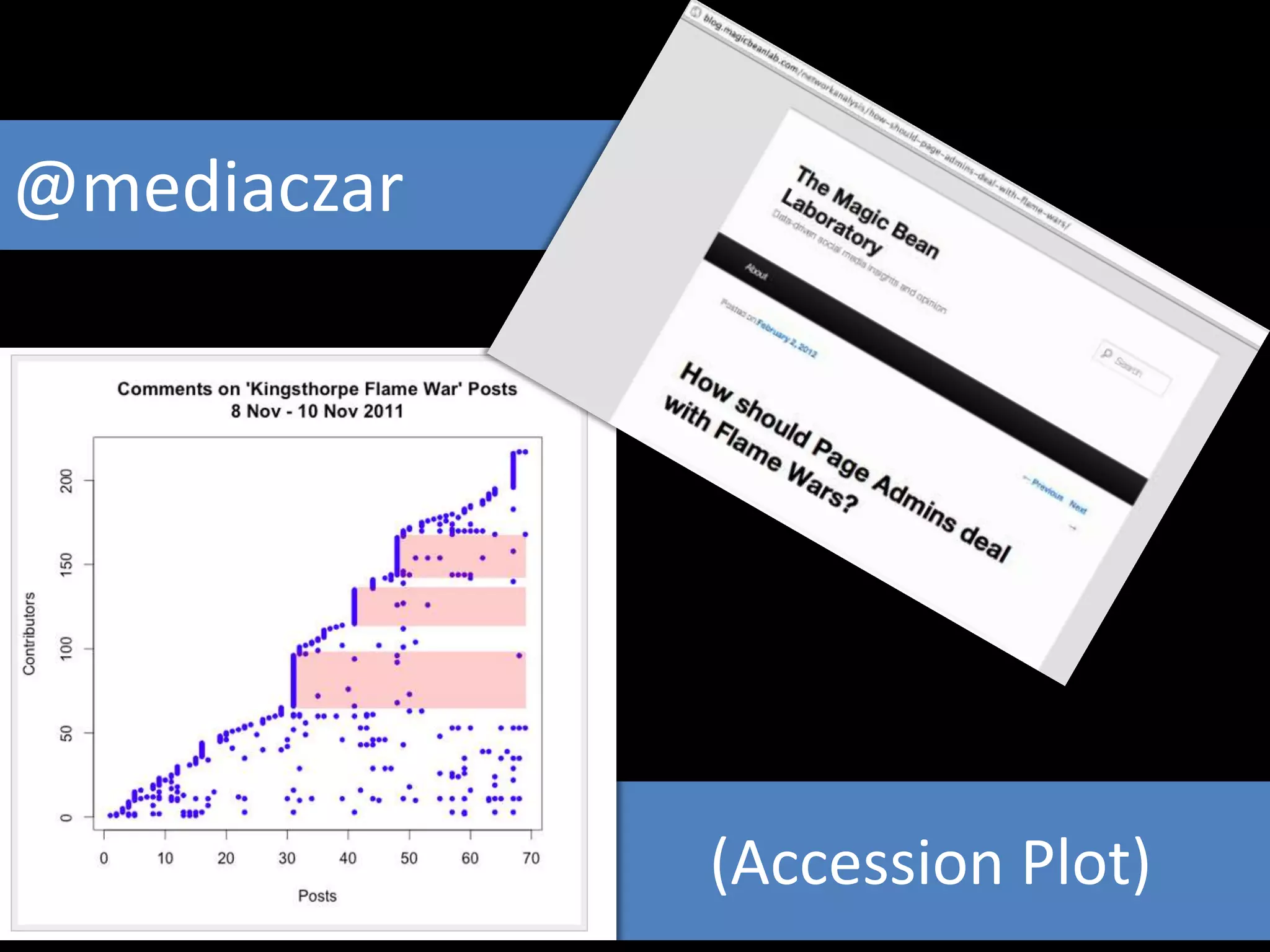
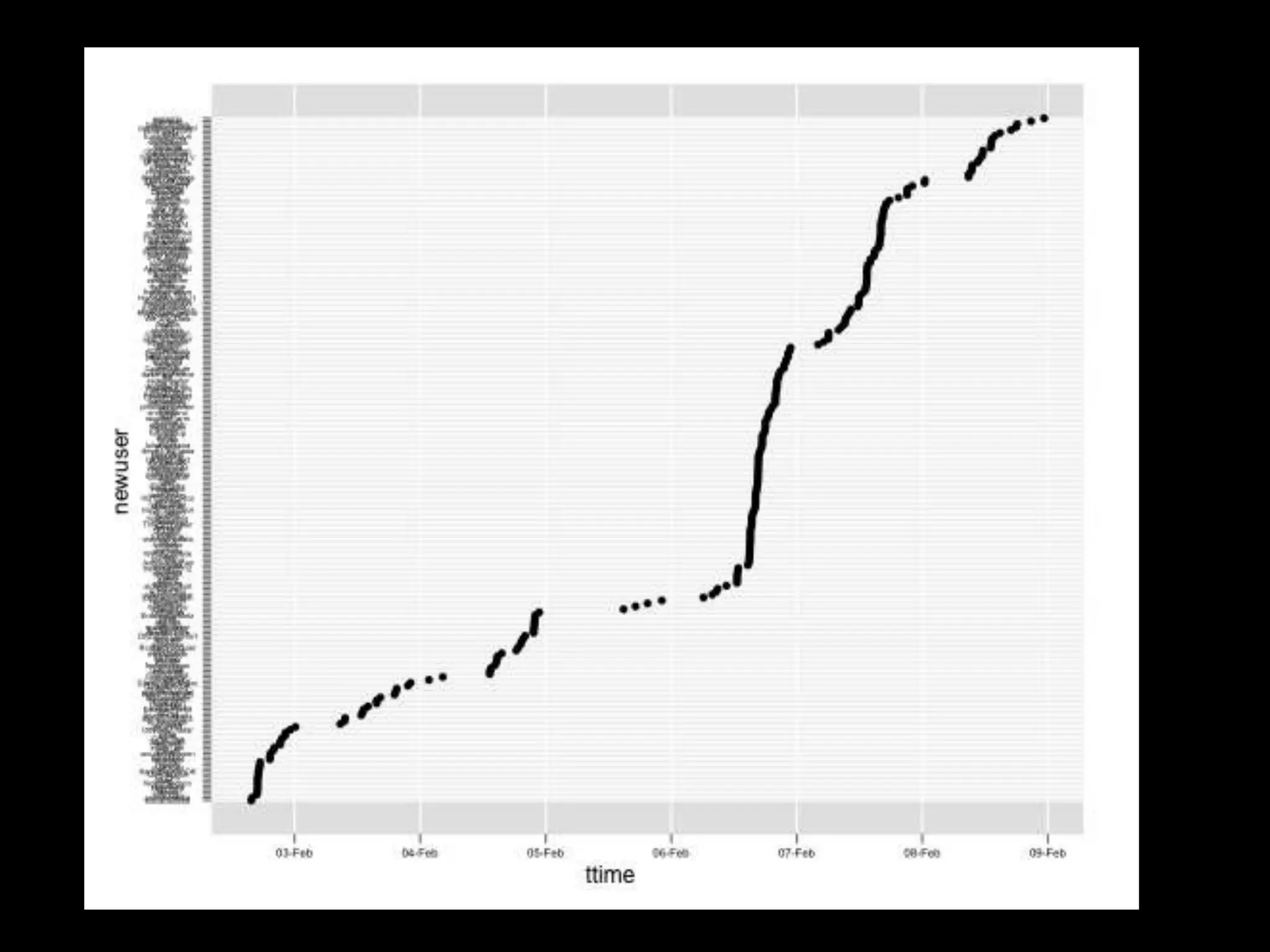
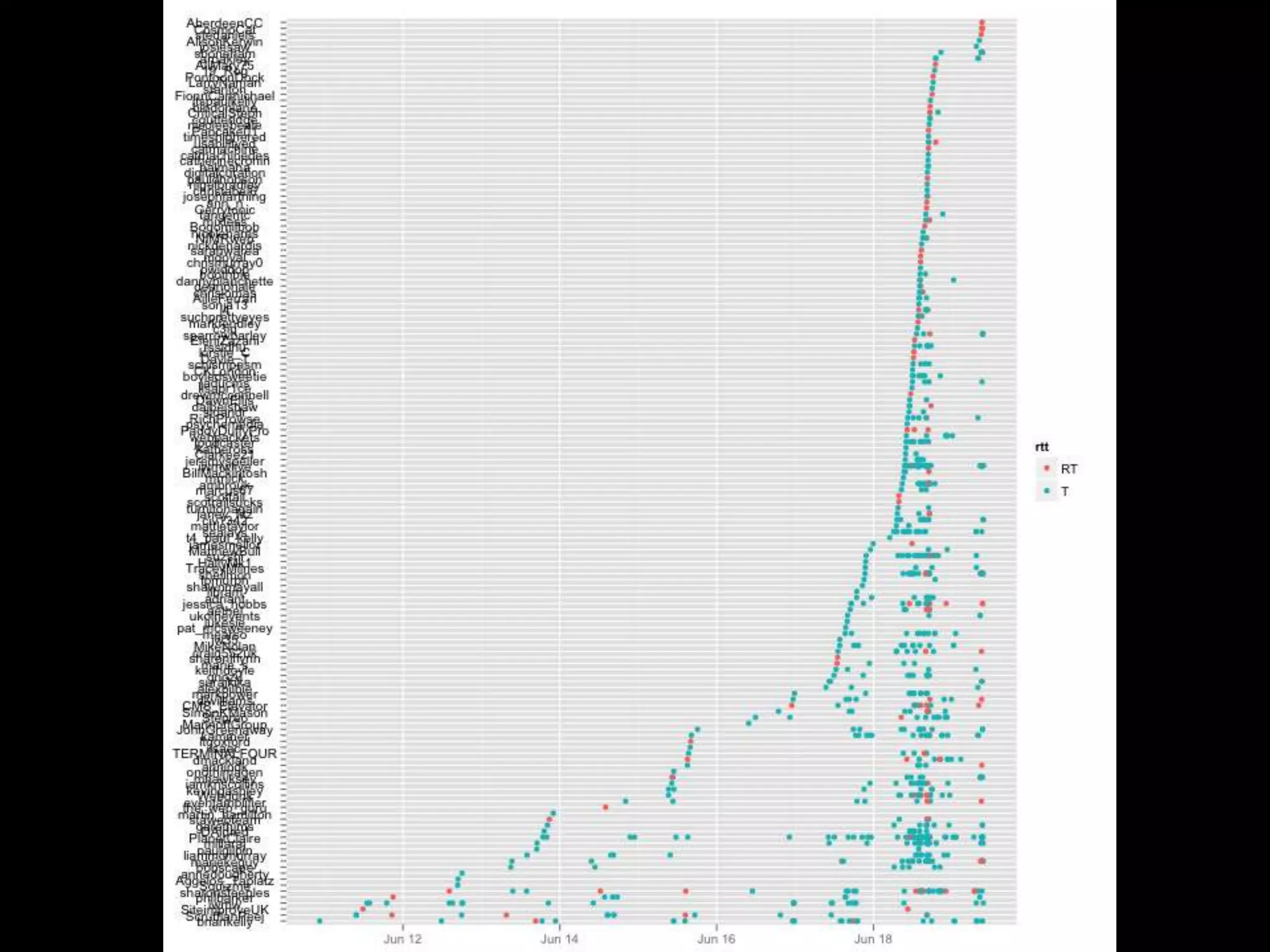
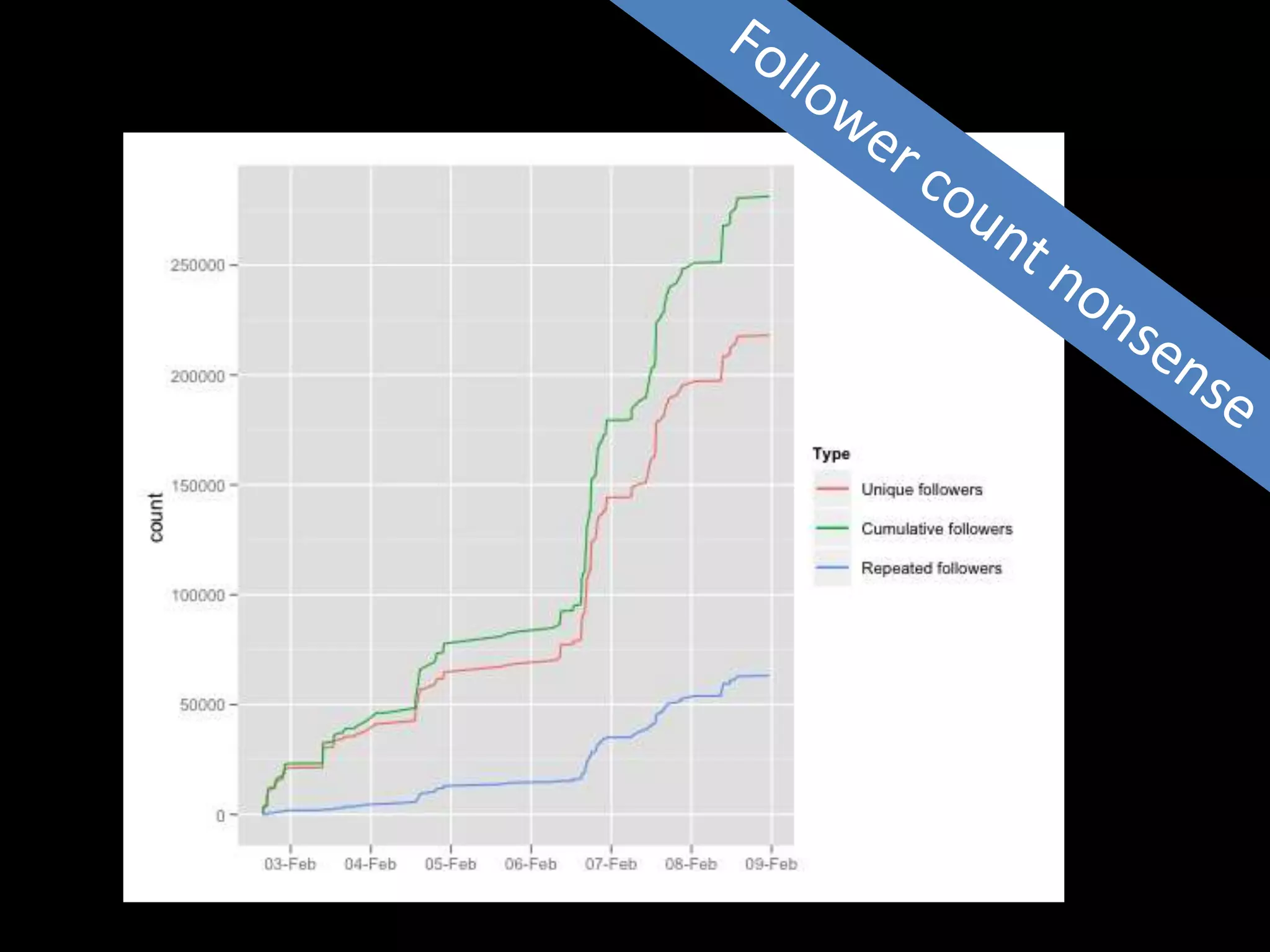
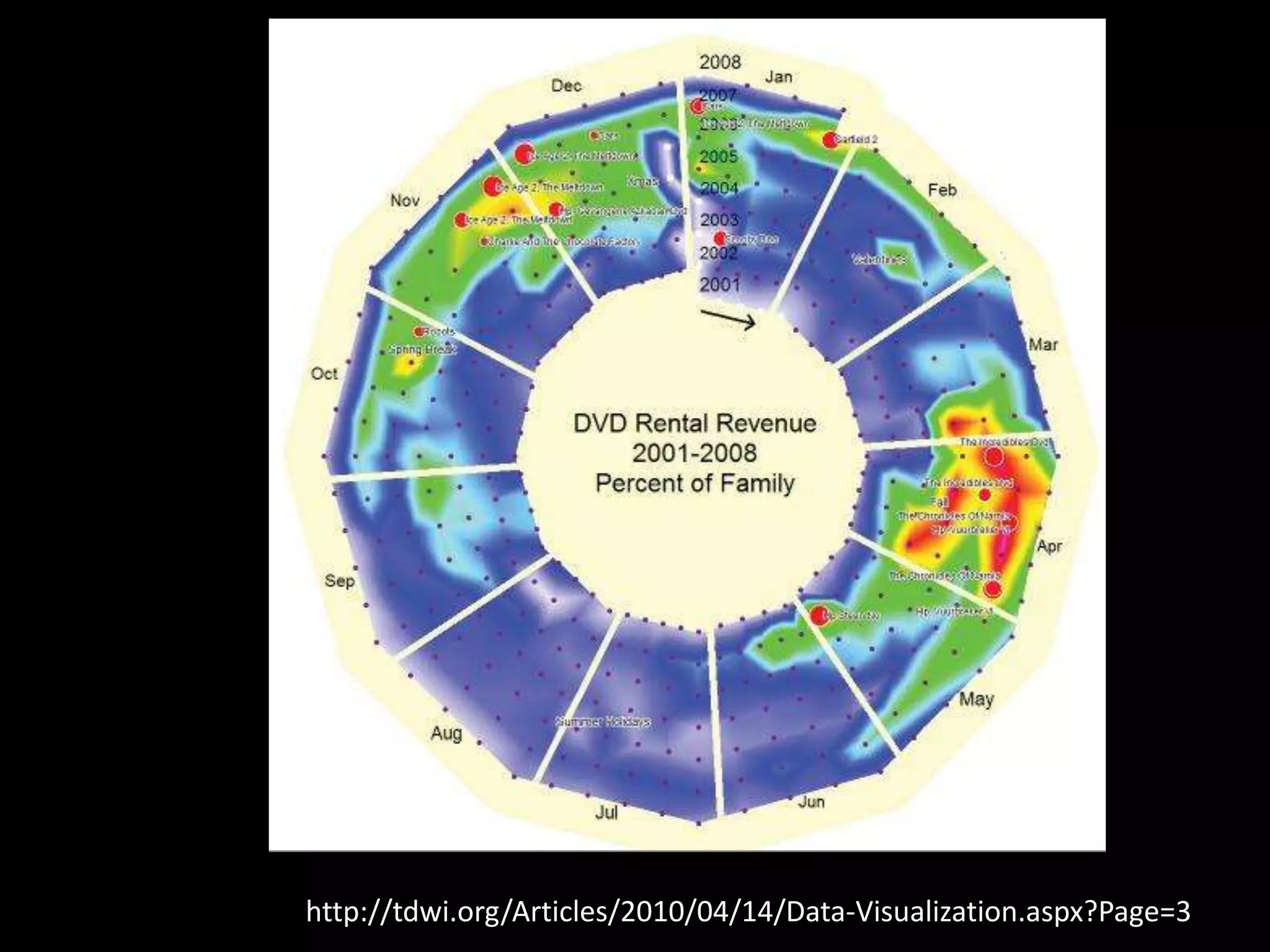

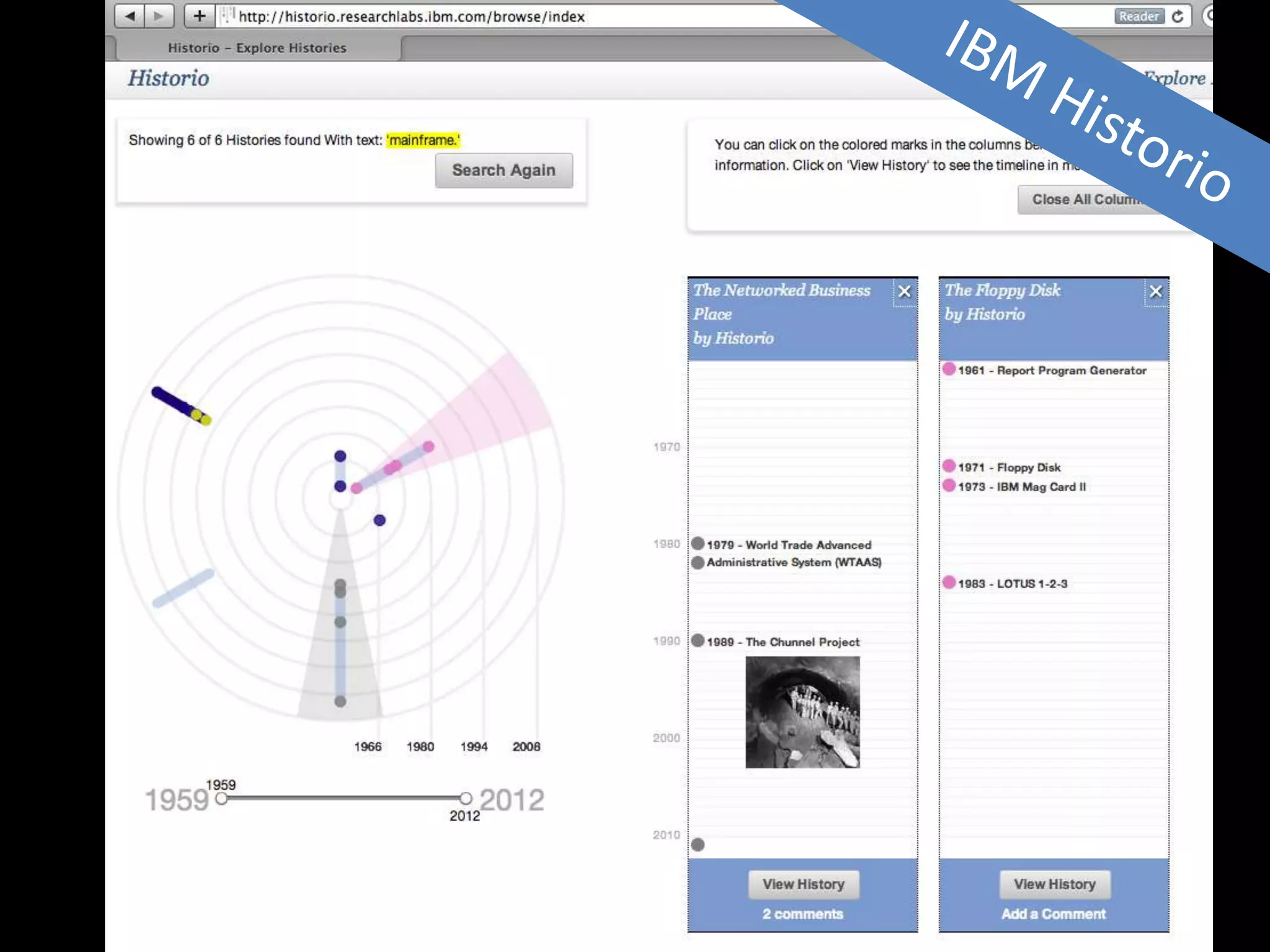

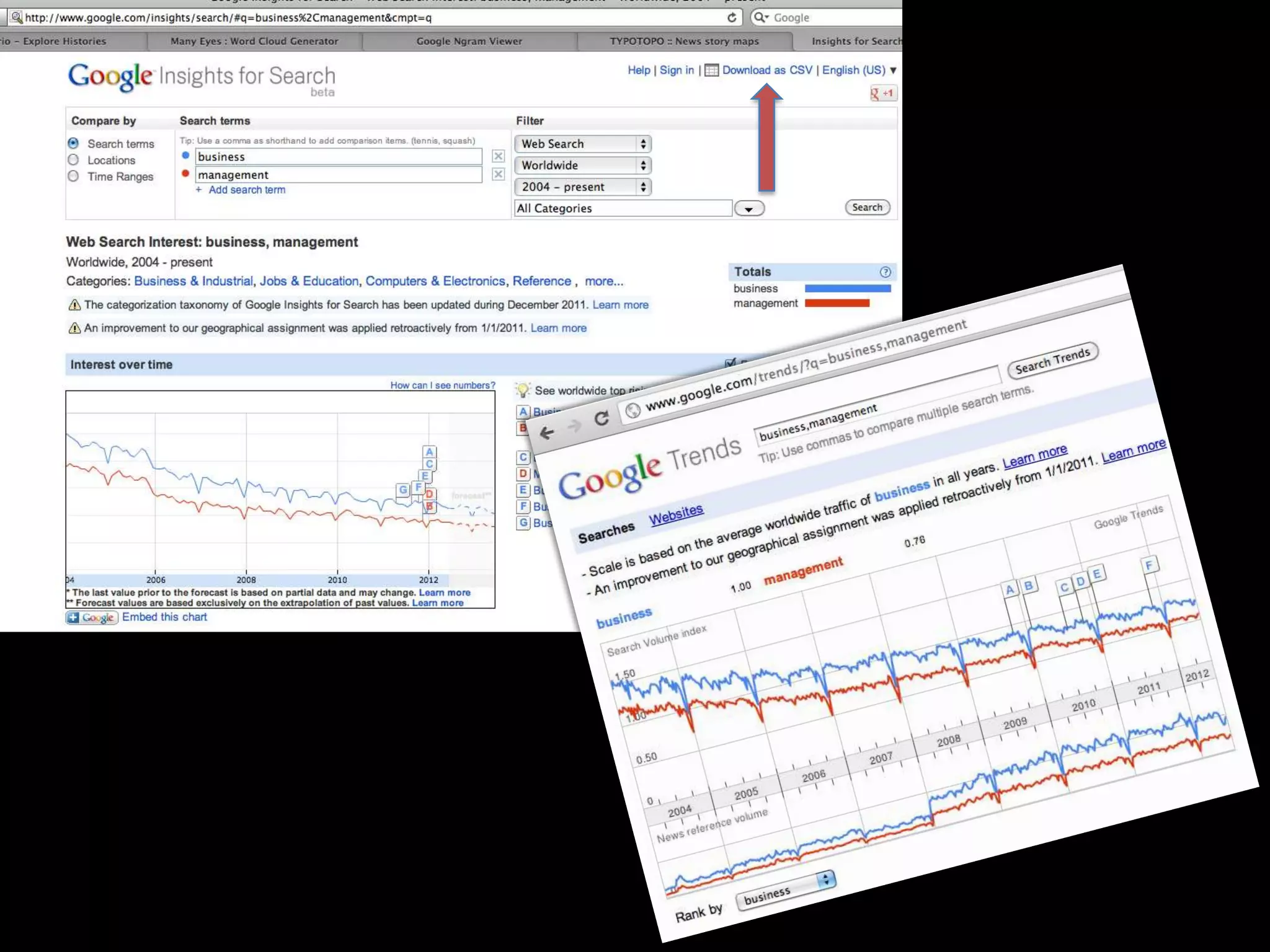
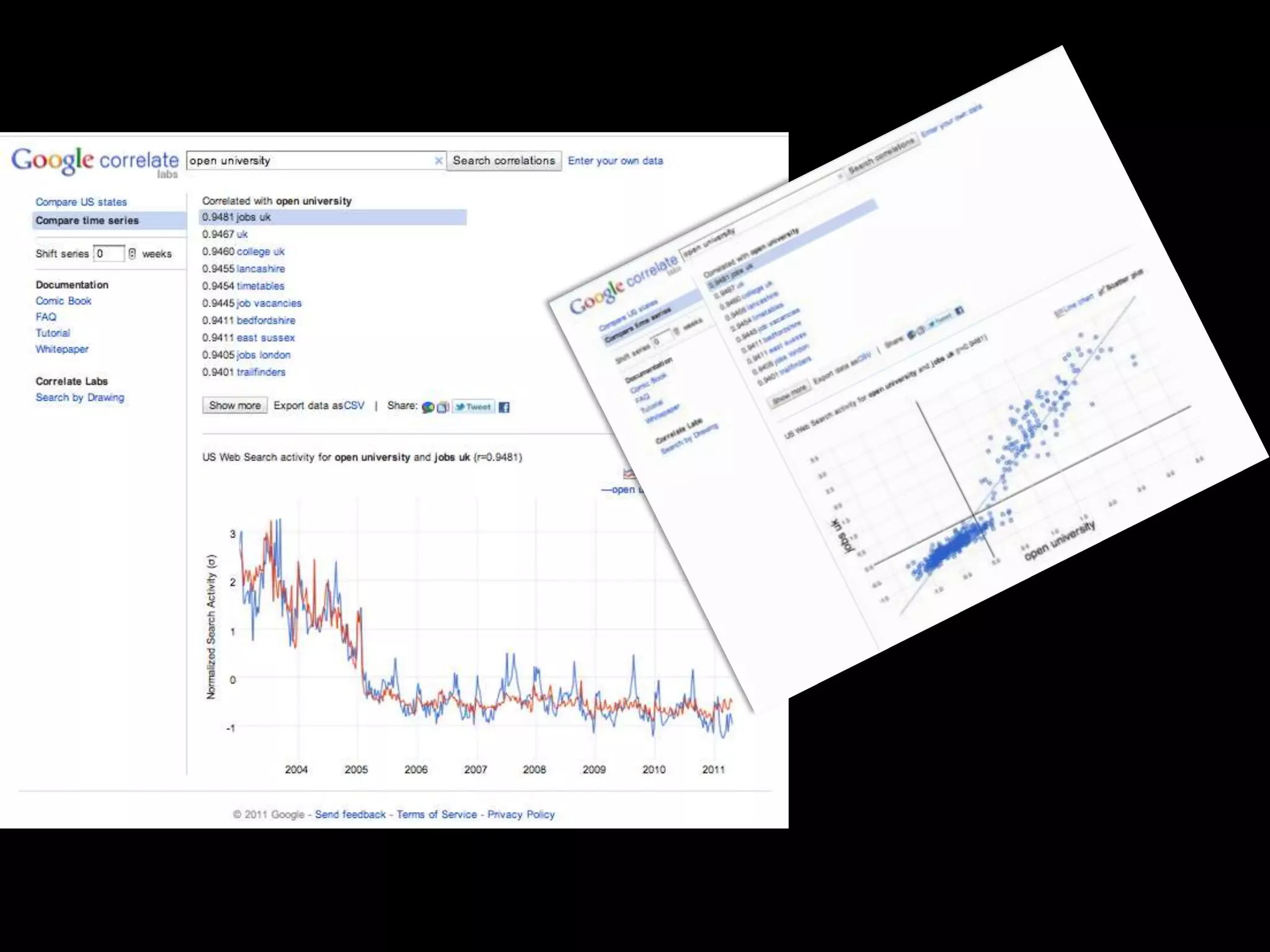
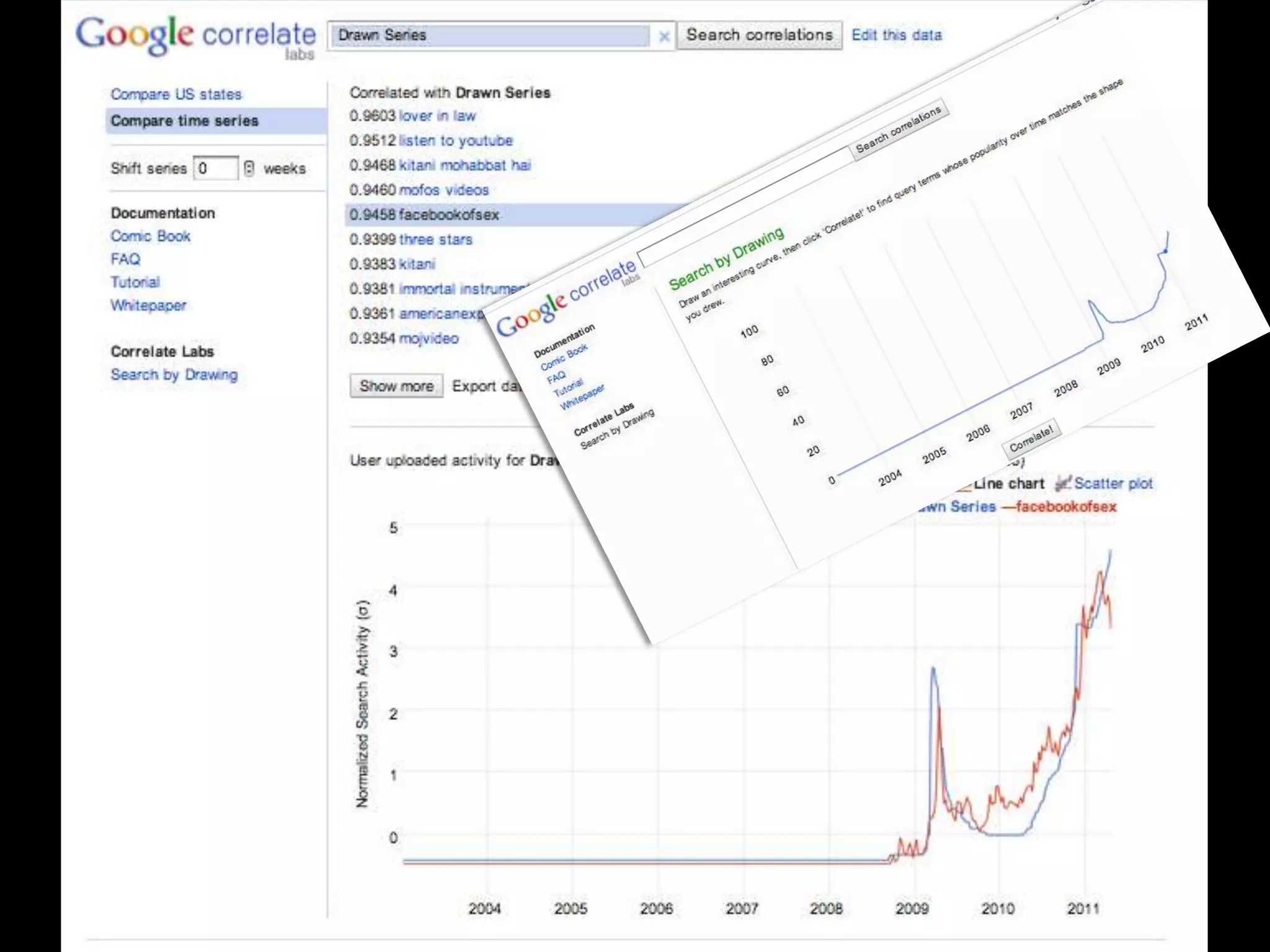

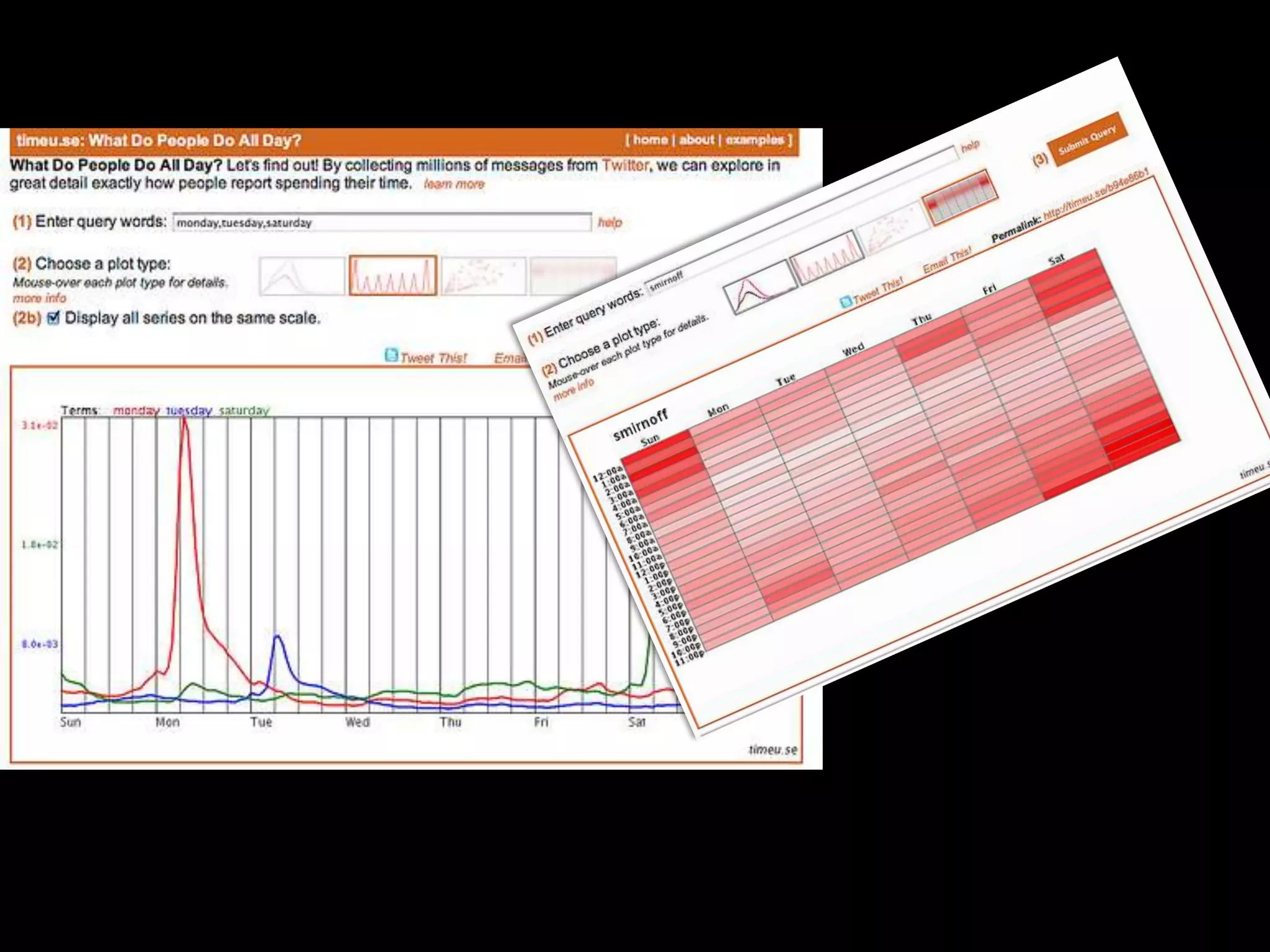
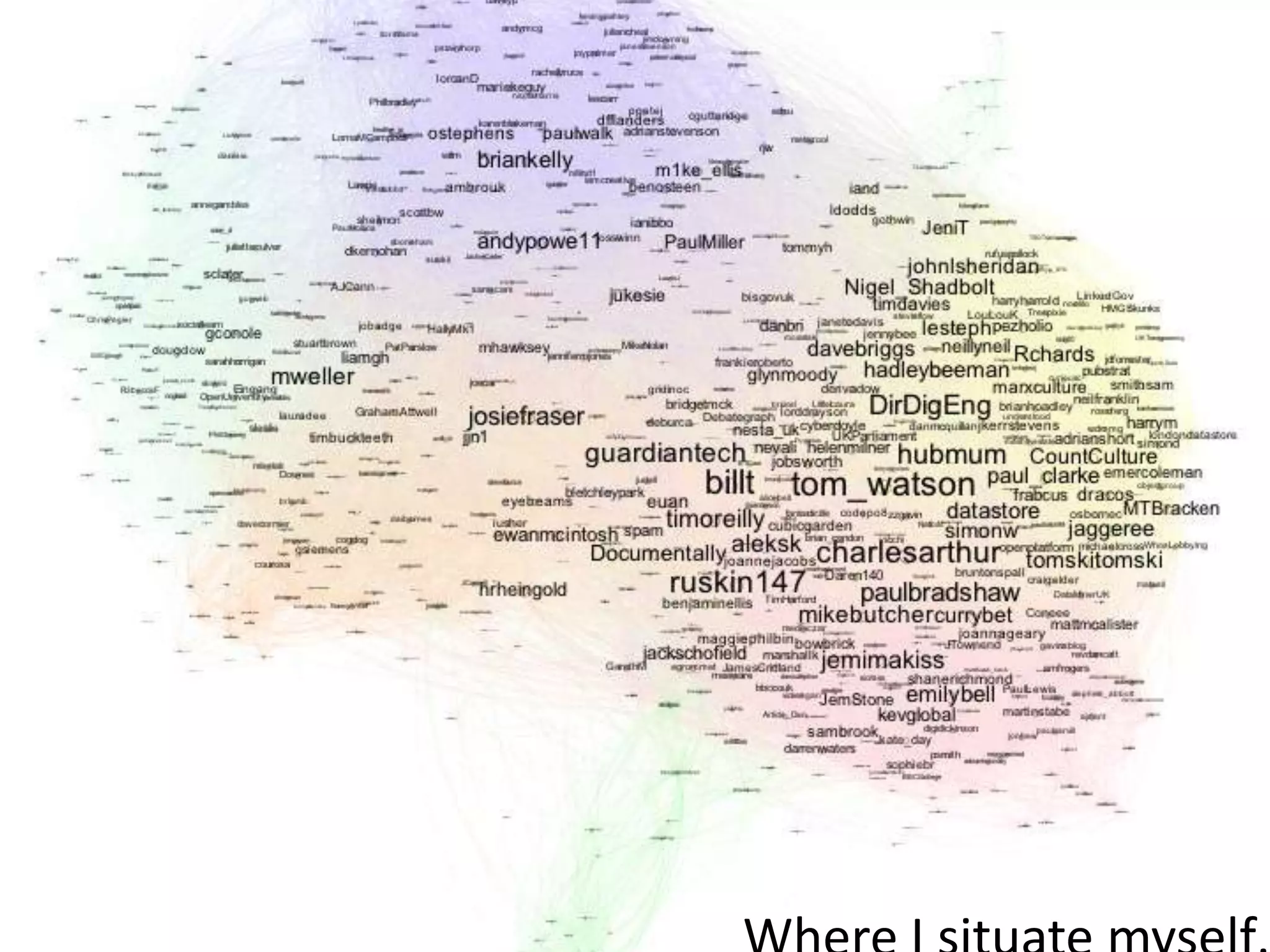


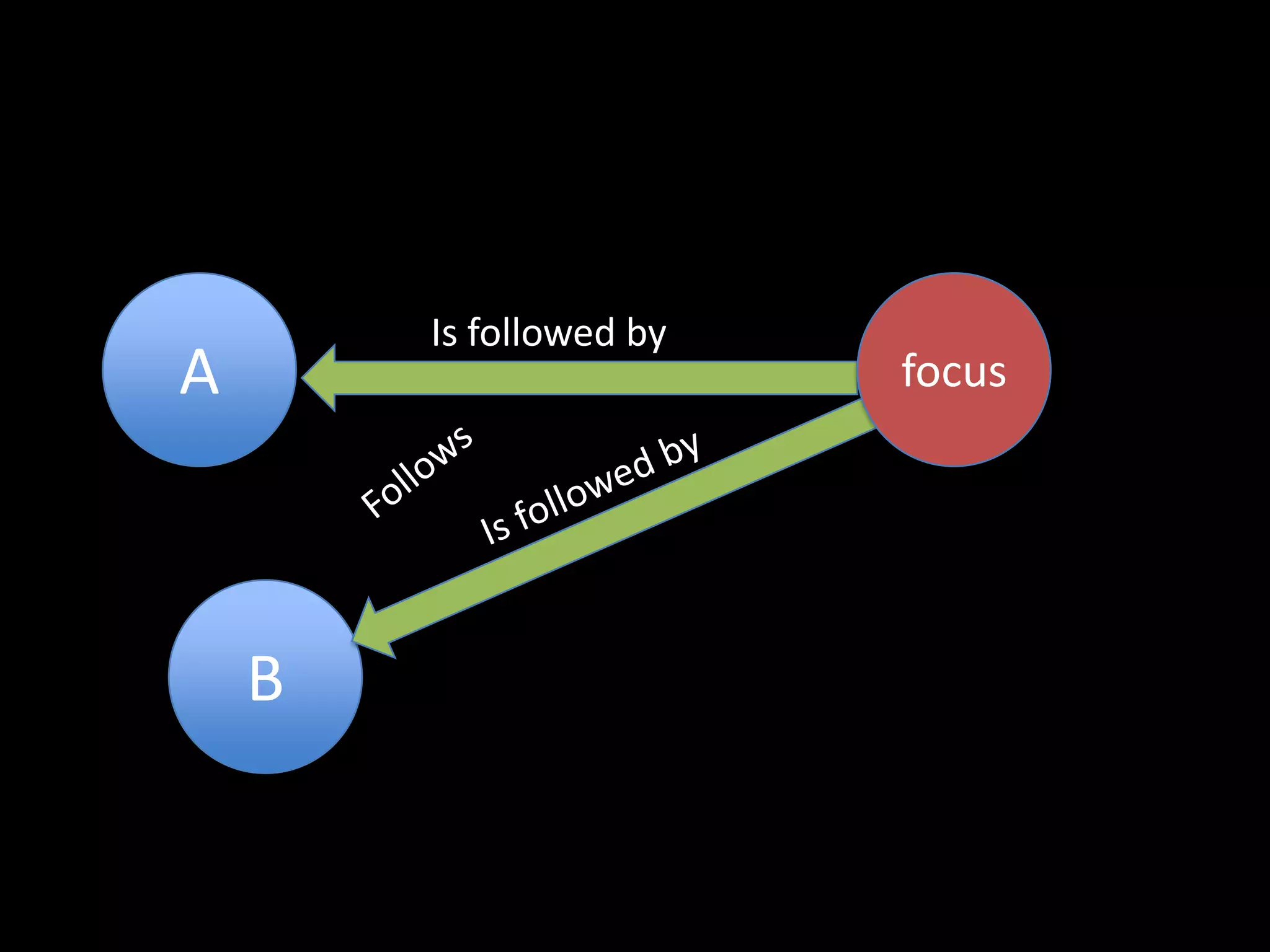
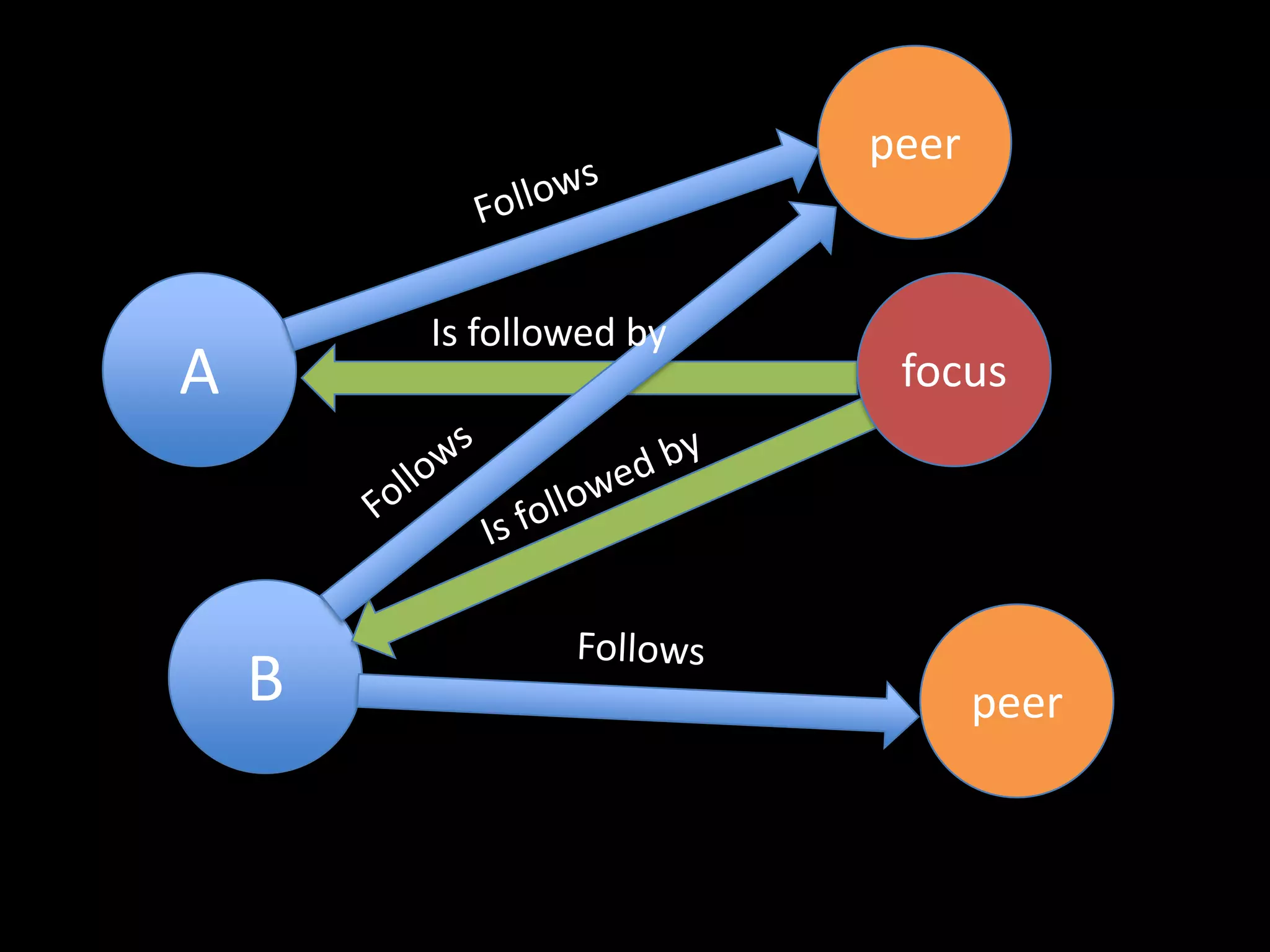

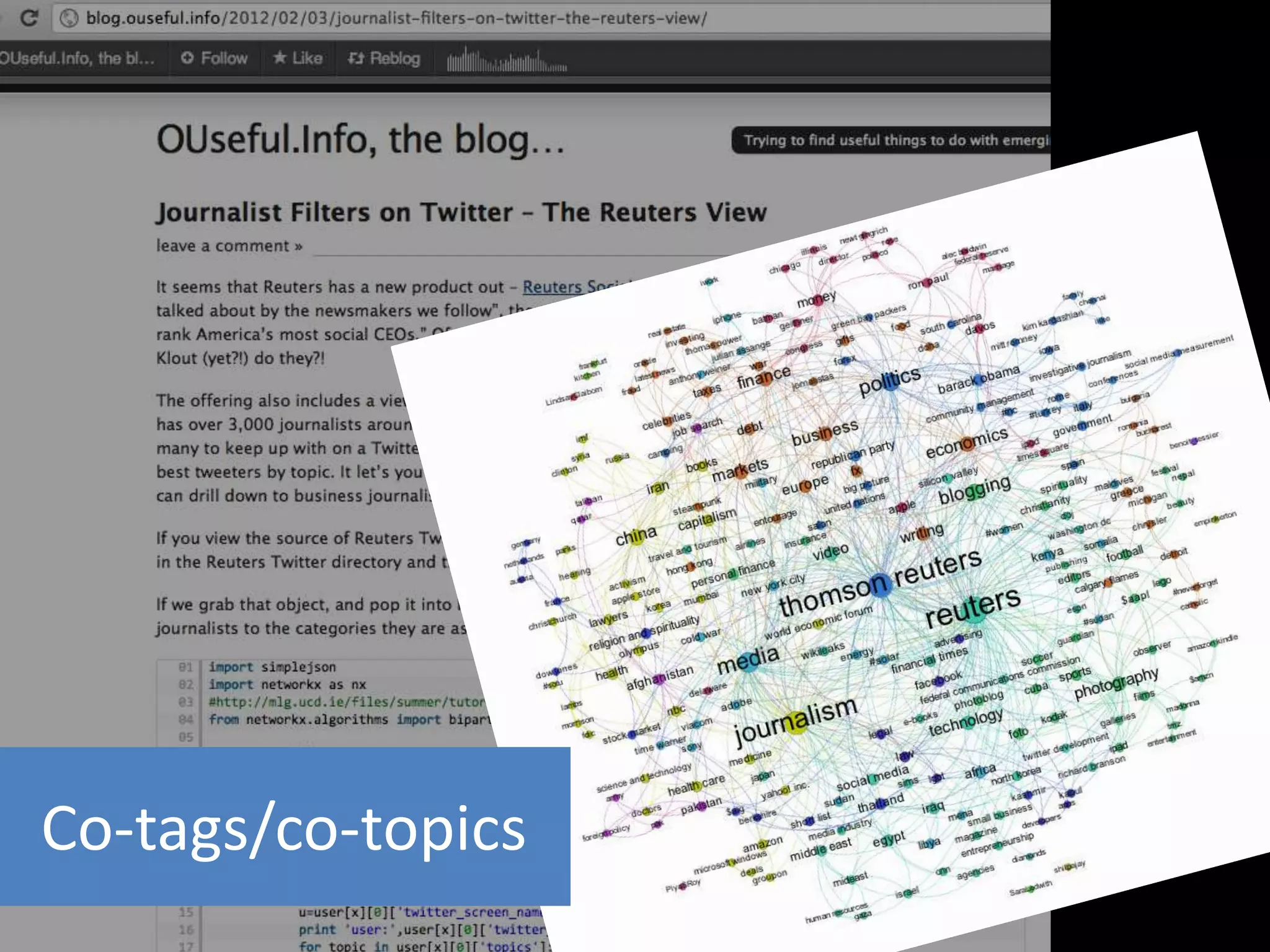
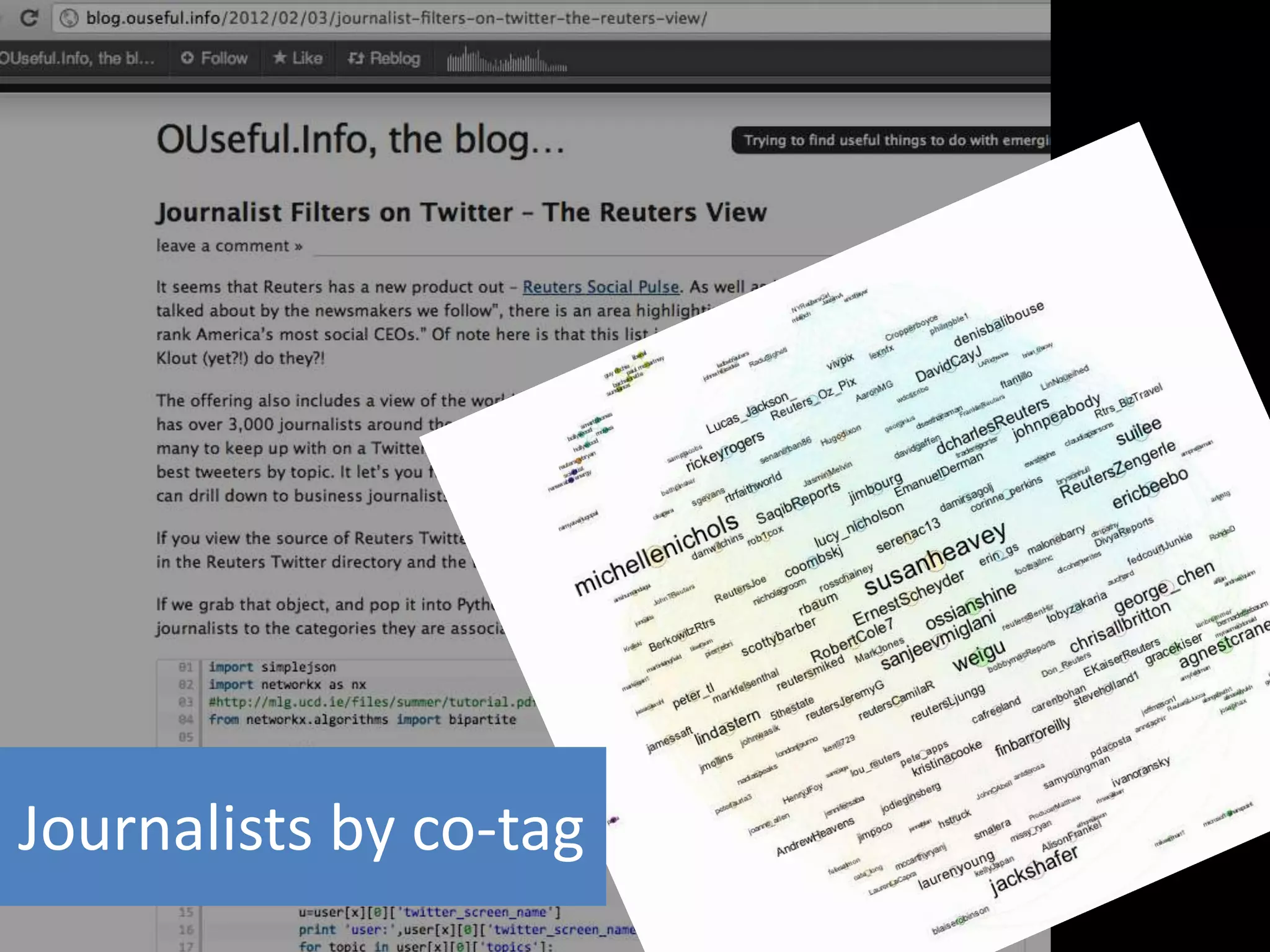

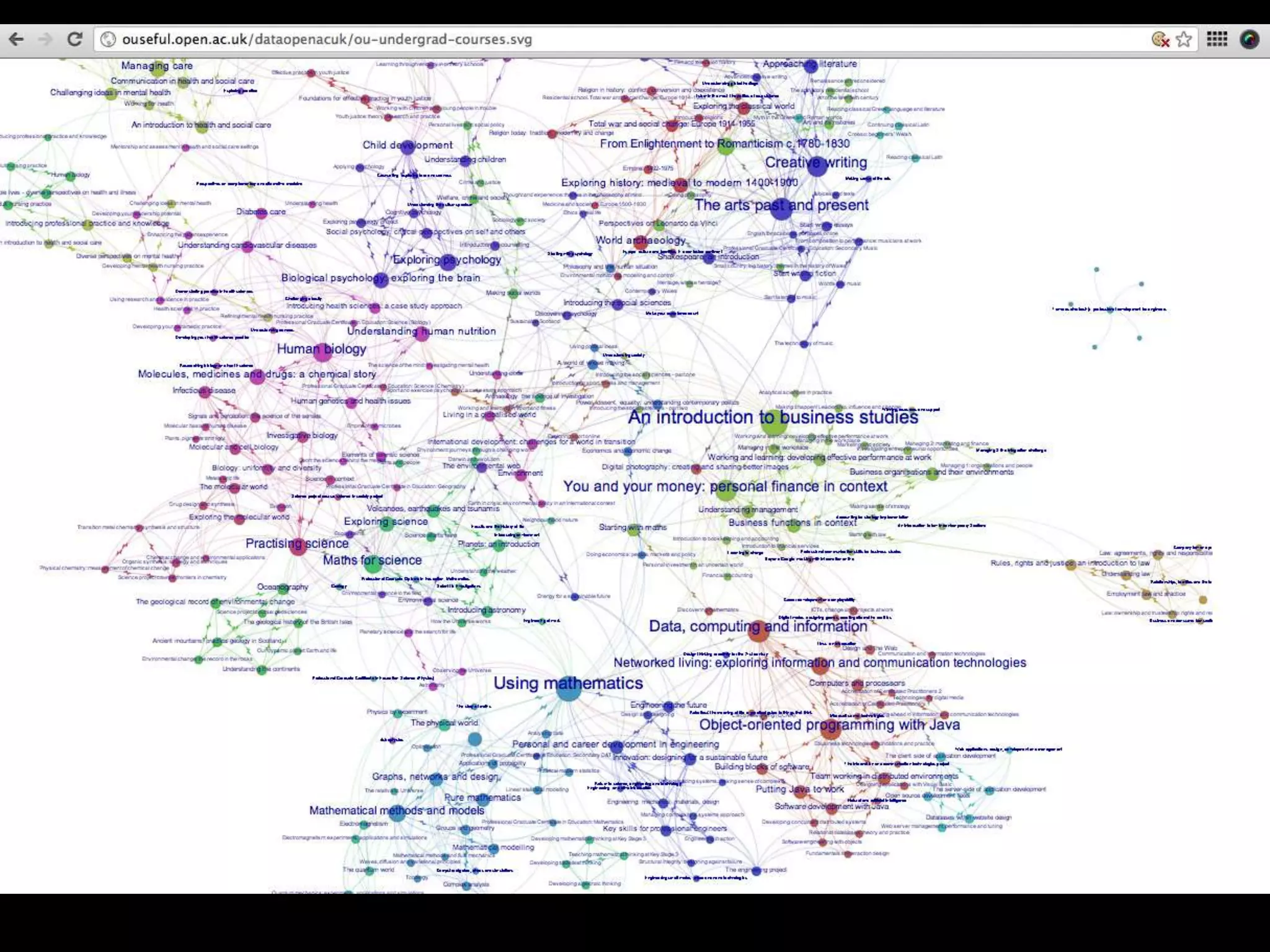
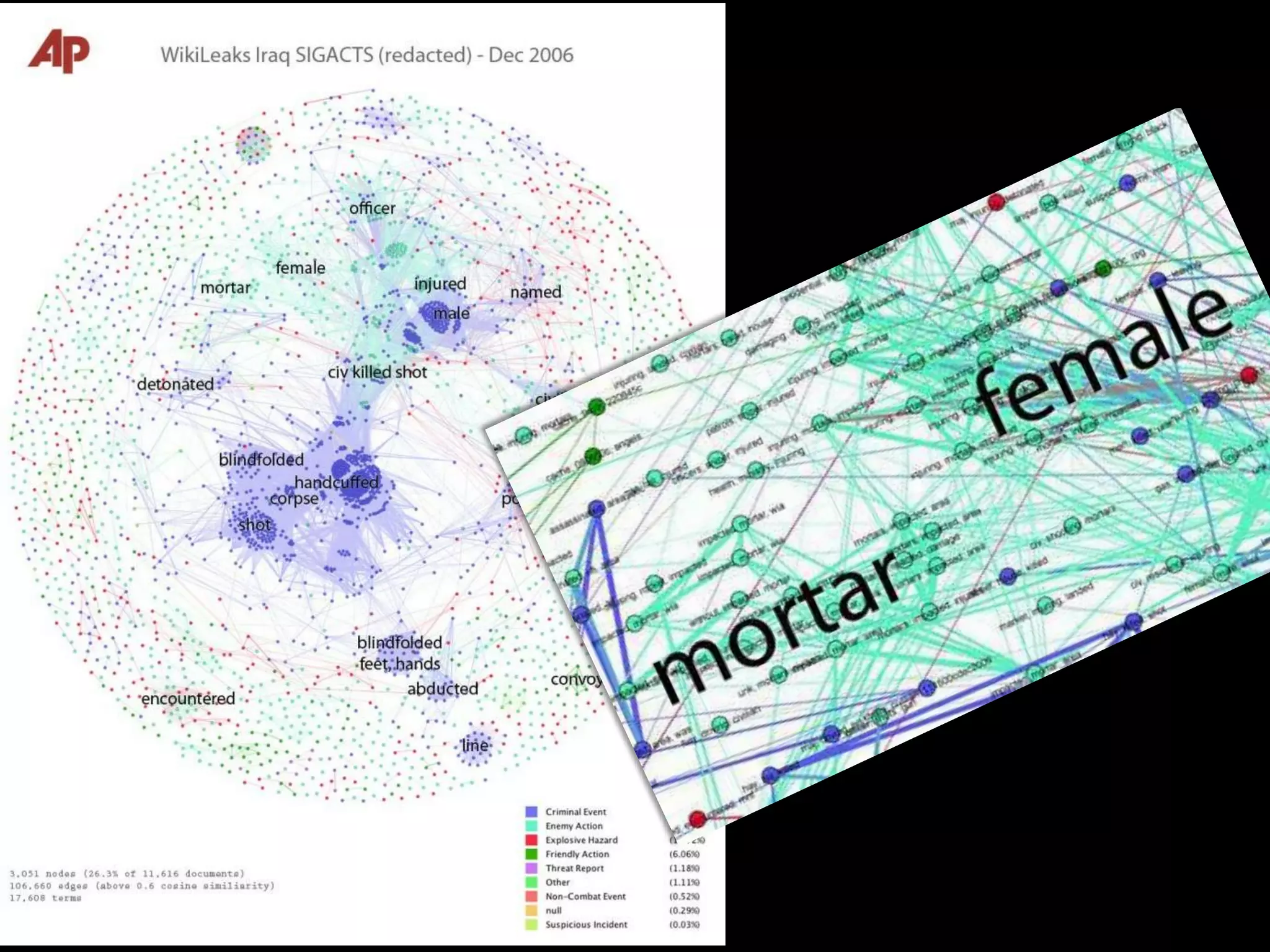
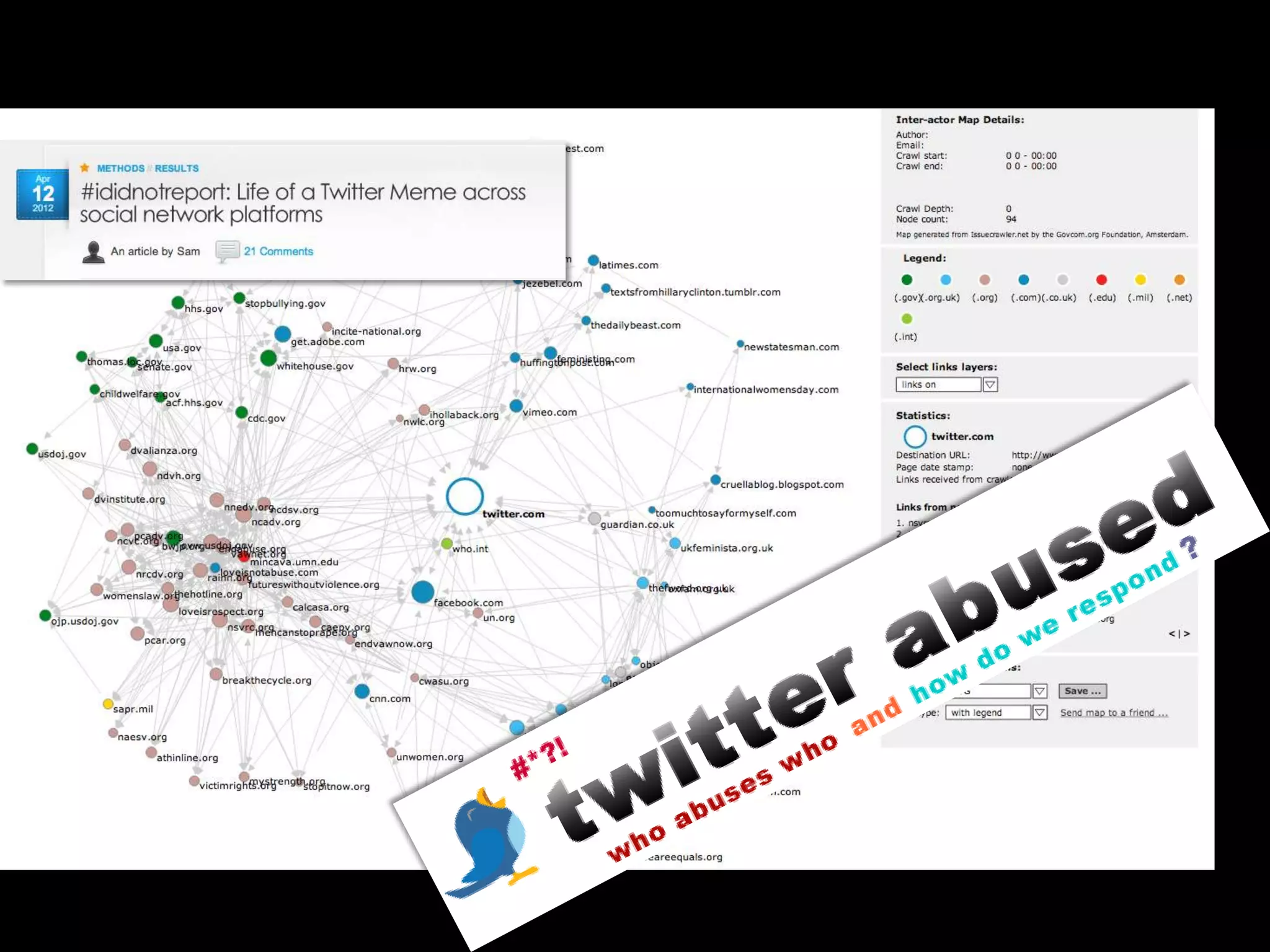
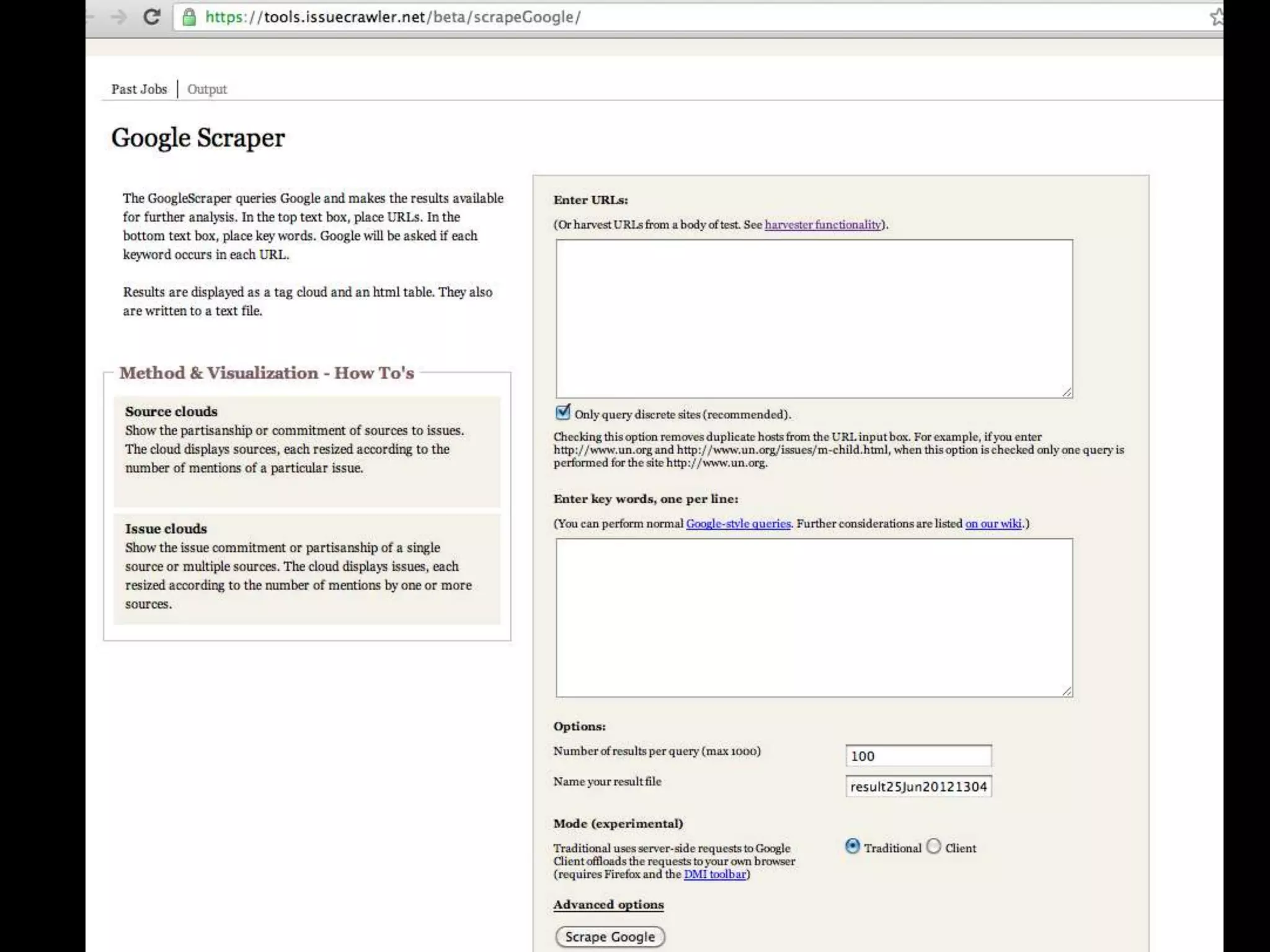


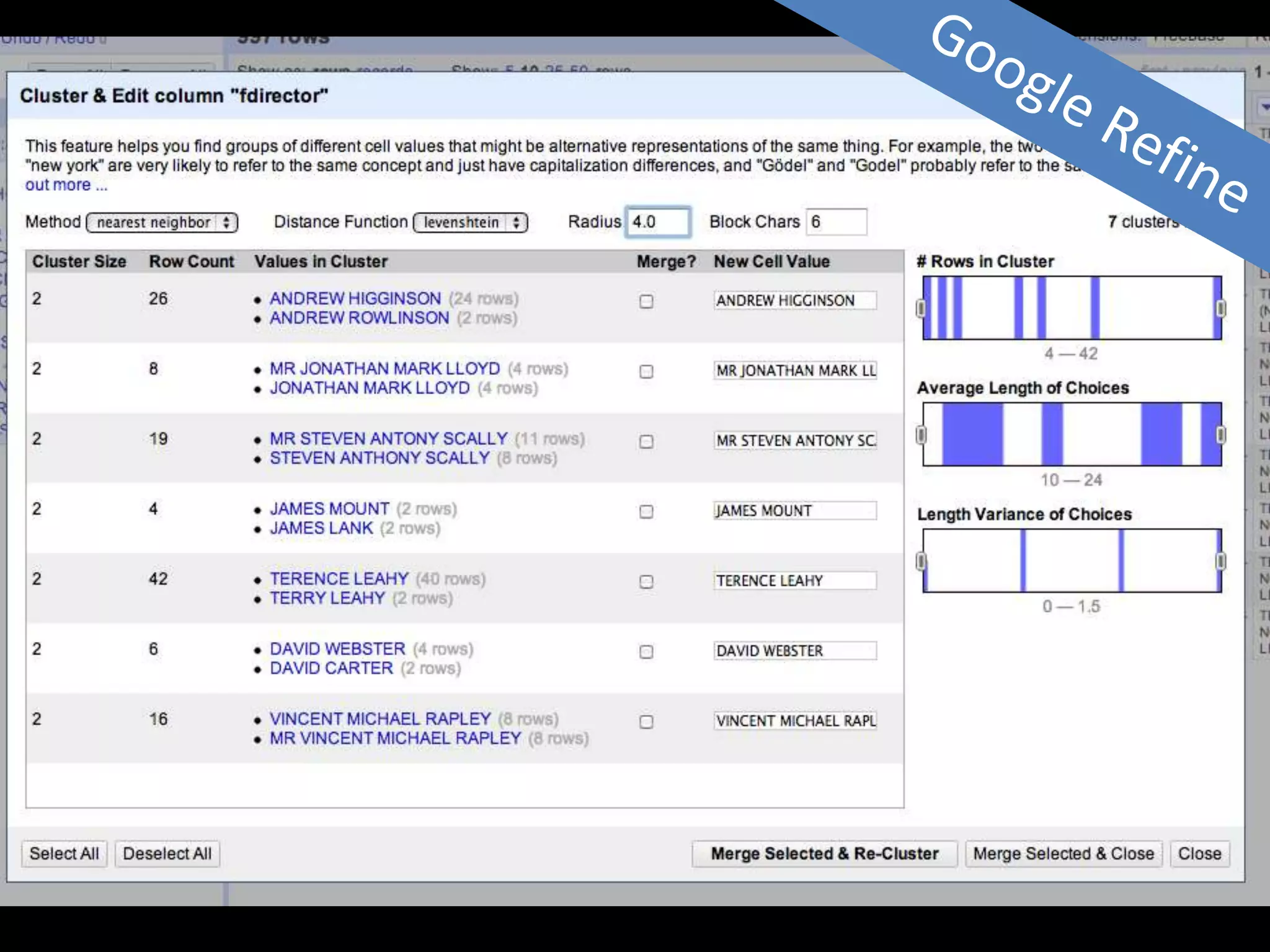


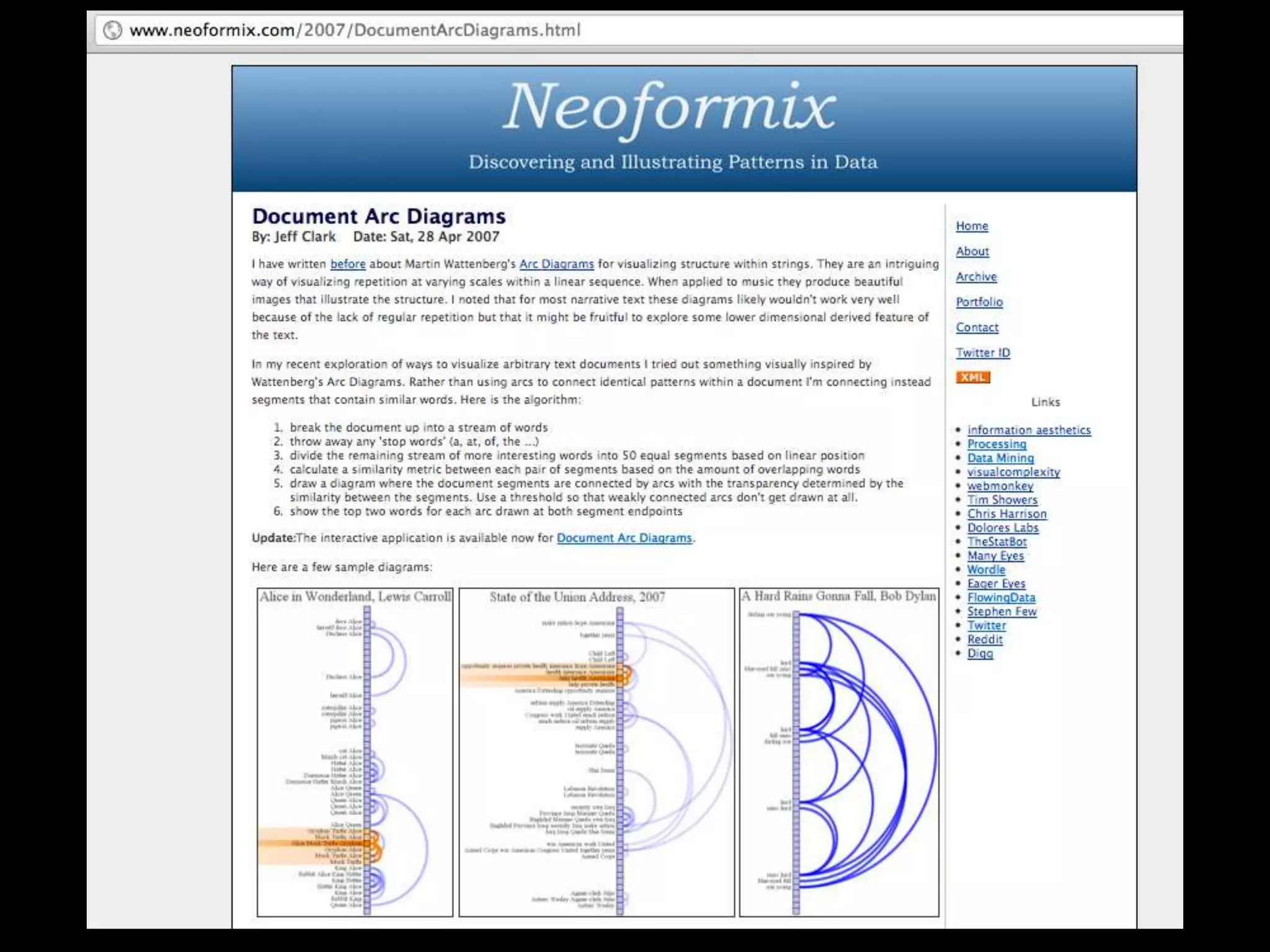
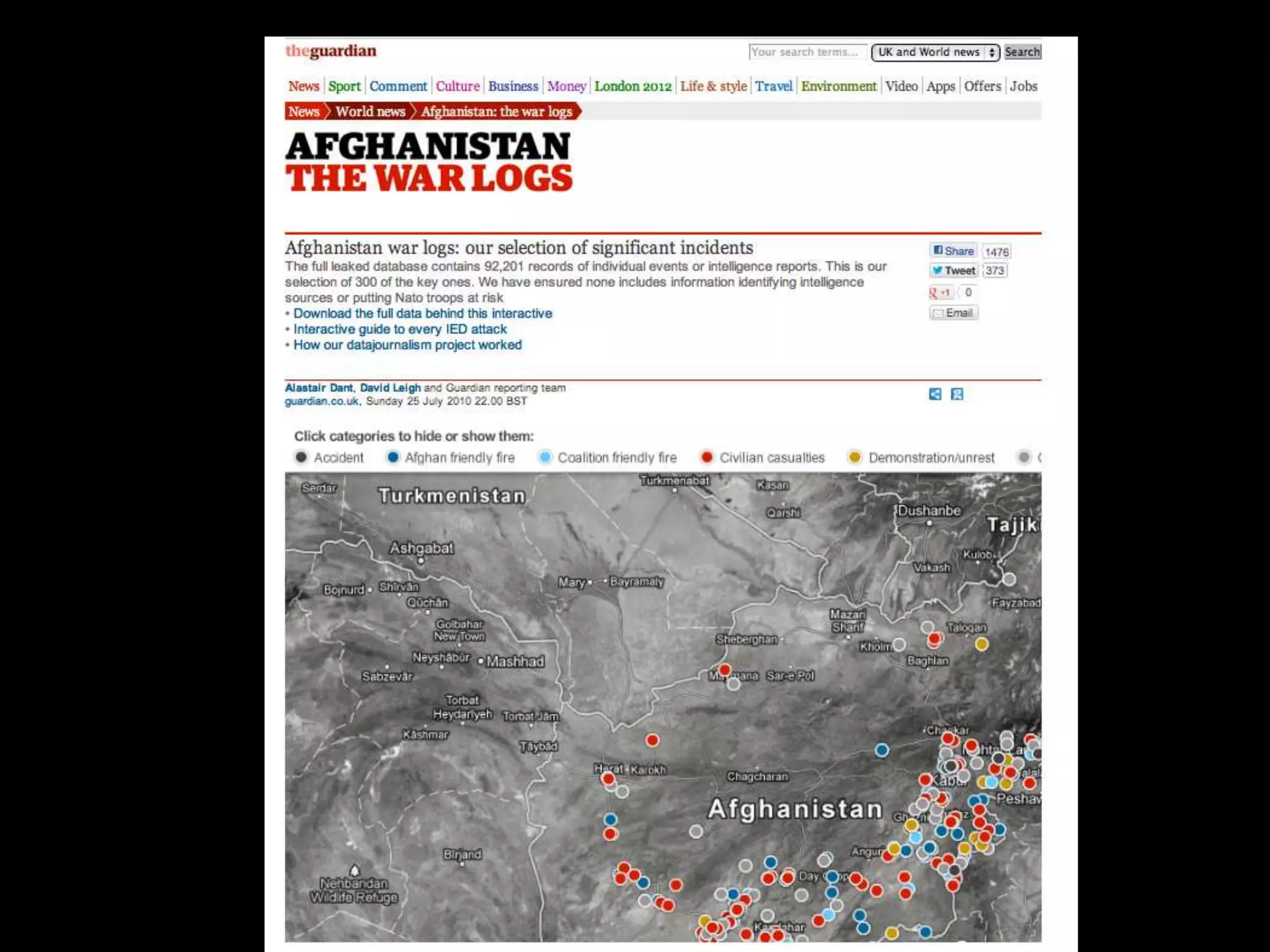




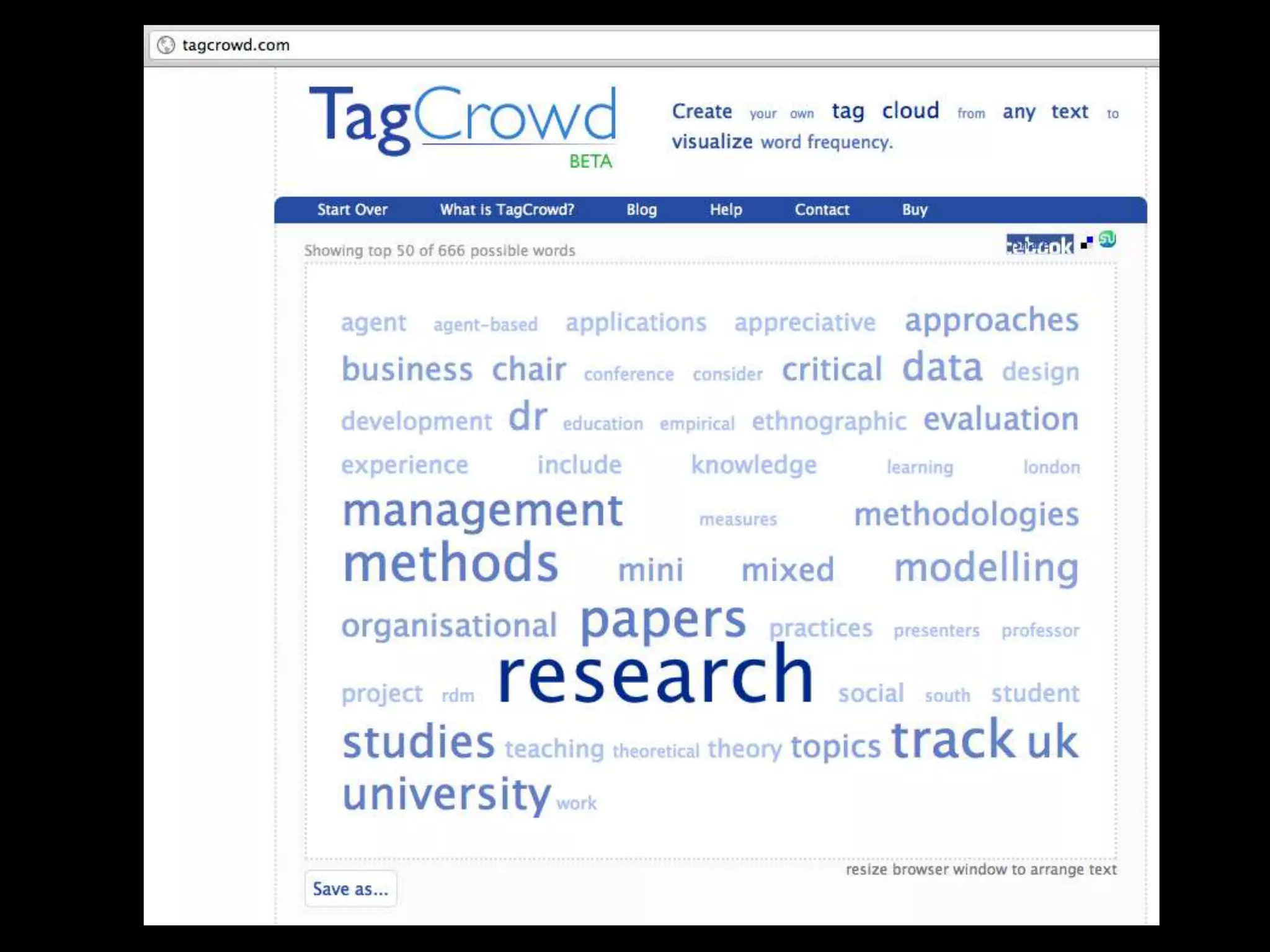
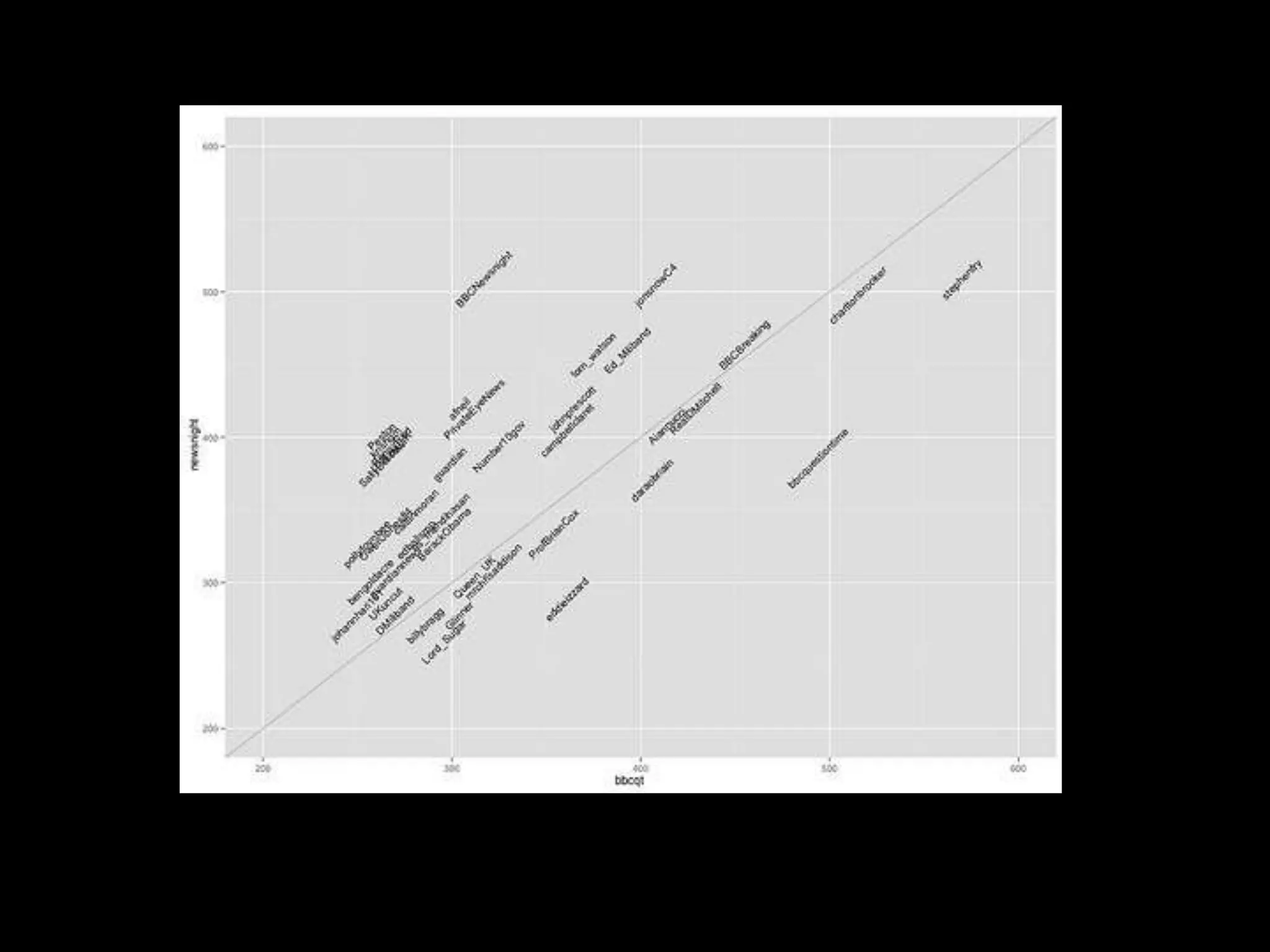
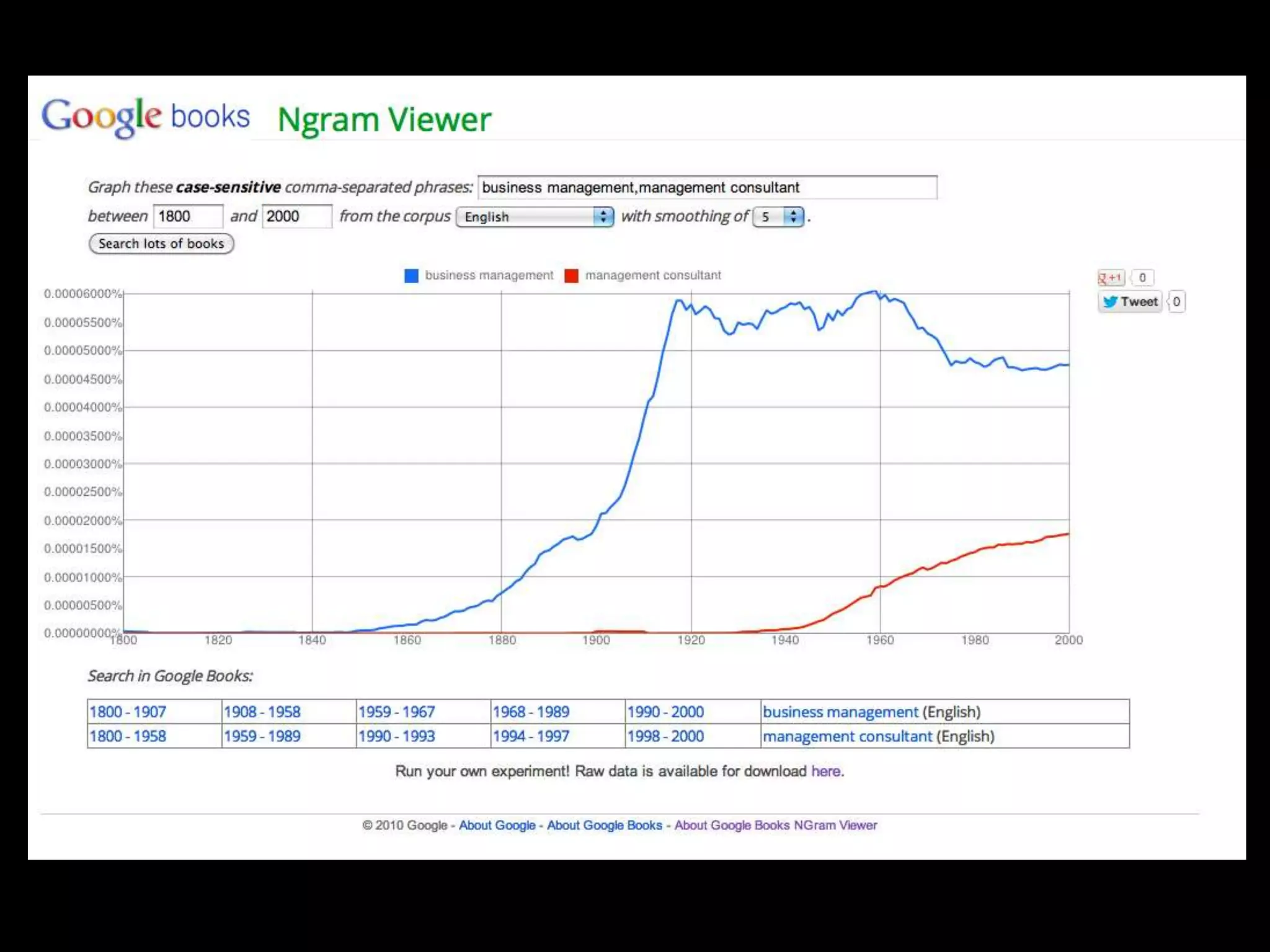
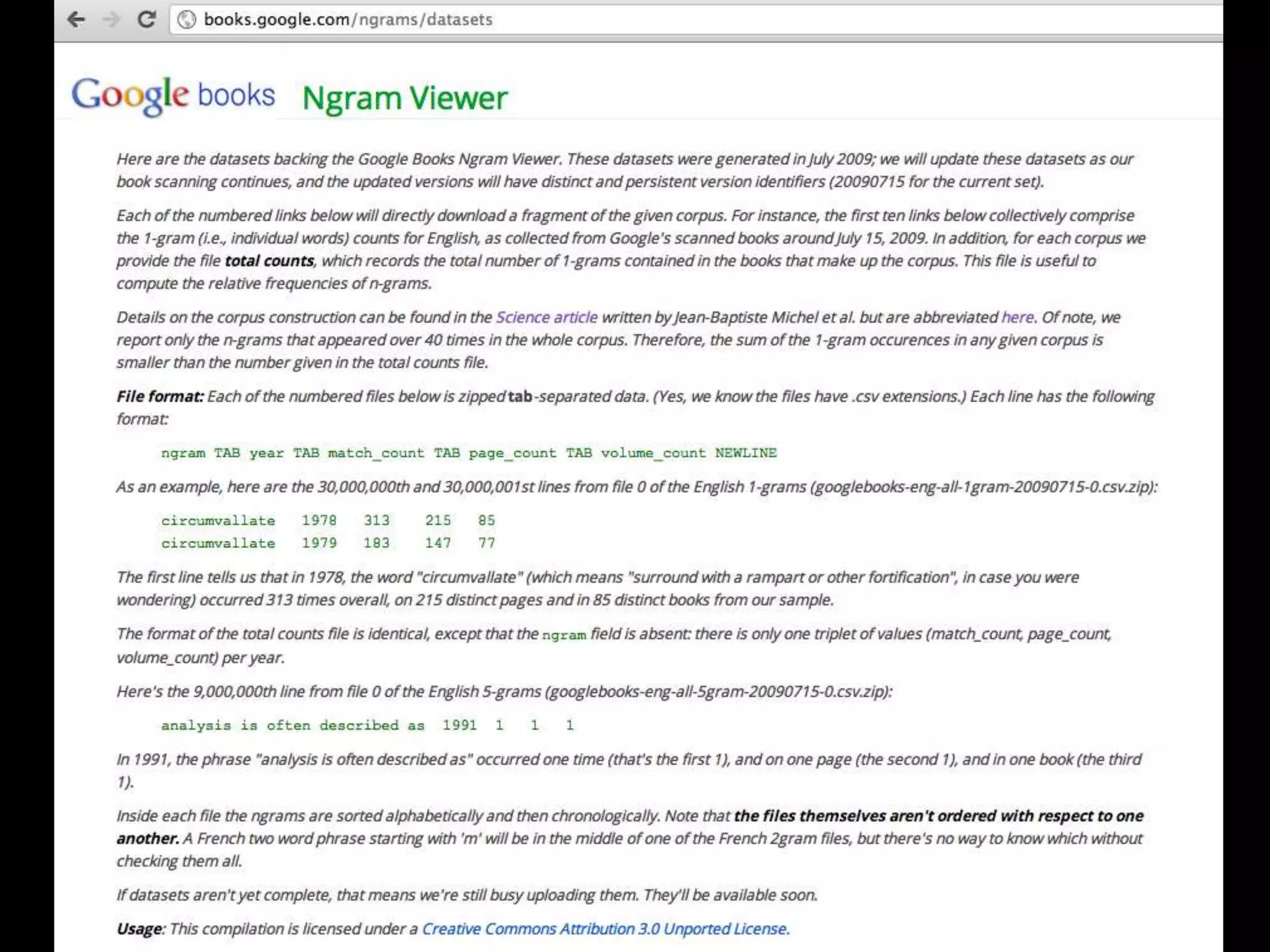
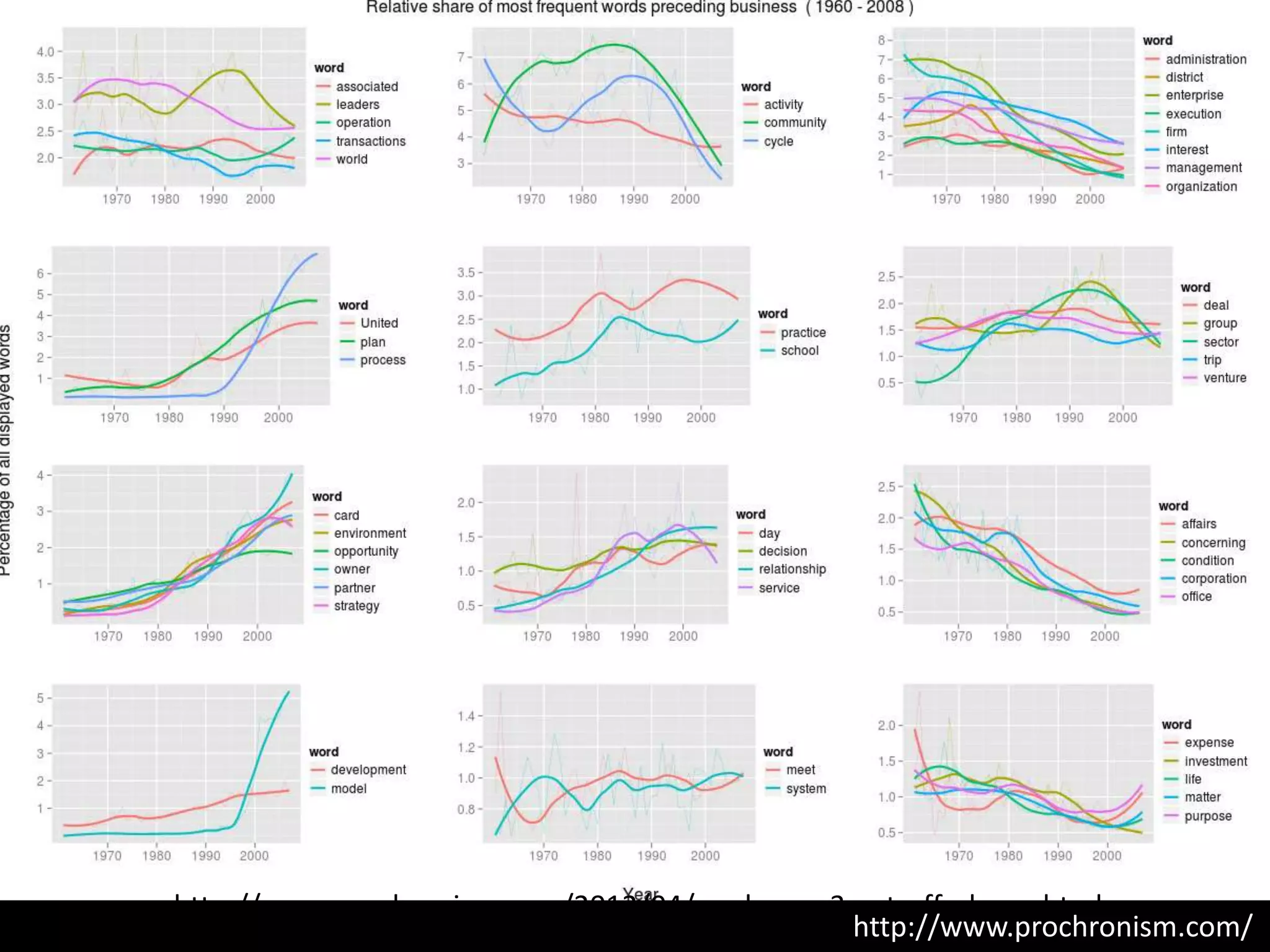
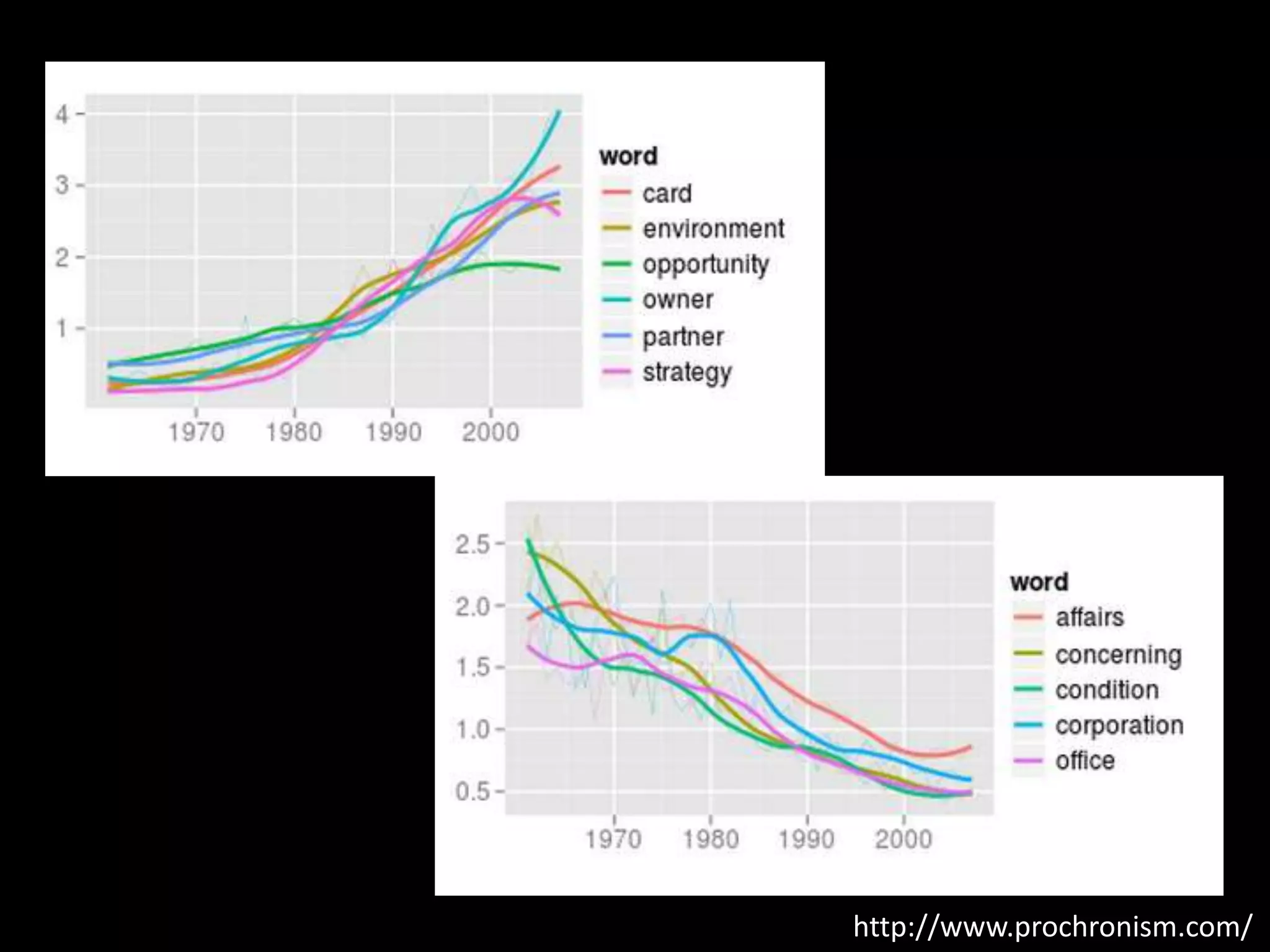
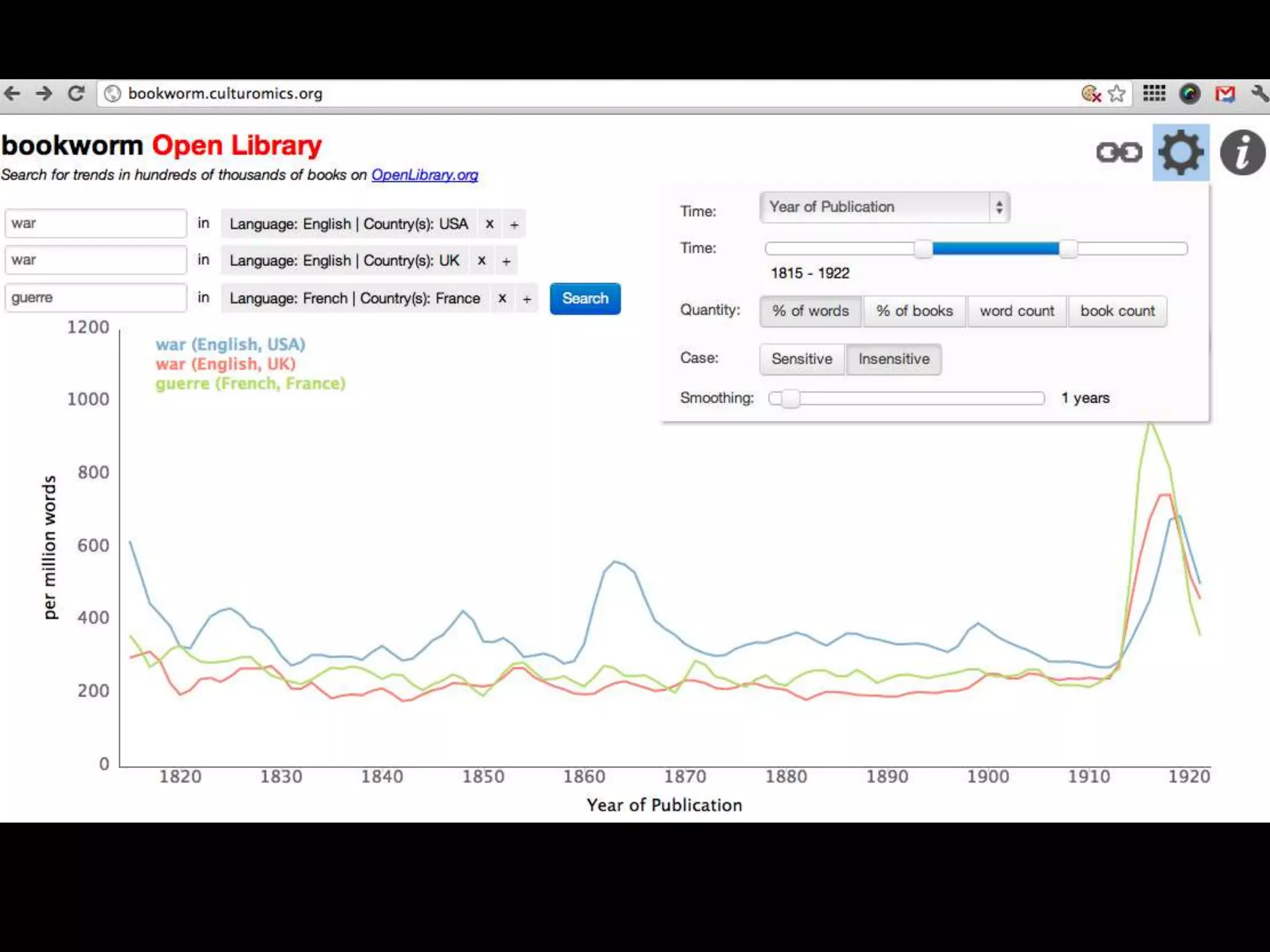
The document discusses various topics related to visualizing data including: - Term frequency-inverse document frequency and how it relates to information retrieval research - The differences between explanatory and exploratory visualization - Using data sketches and visualization to tell stories with data - Examples of visualization techniques like spirals, accession plots, and visualizing structure through signatures























































































