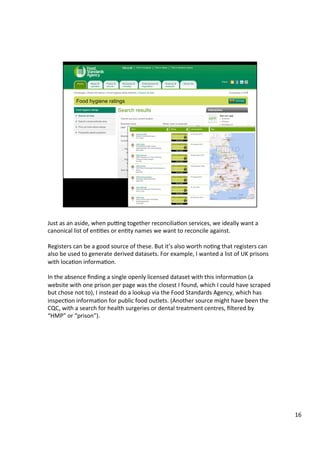
Downloaded 10 times



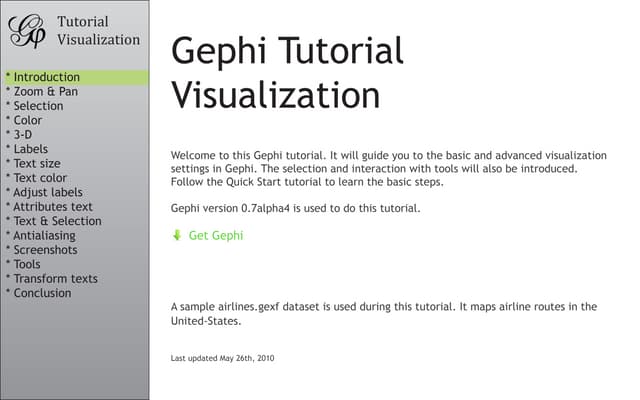
![The tools I’m going to talk about are situated within a data context. I spend a lot of
Ame playing with openly licensed datasets, working across the whole data pipeline.
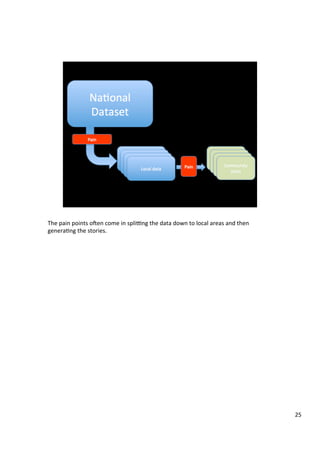
This example, taken from the third year undergrad equivalent OU course TM351
“Data Analysis and Management” provides a simplisAc view of some of the processes
involved in working with data.
(We all know it’s not quite that straighSorward, and oTen involves a lot of iteraAon
or backtracking, but as well as “The role of the academic [making] everything less
simple”, as Mary Beard put it in an Observer interview a few weeks ago, the
academic also simplifies and idealises through abstracAon and revisionist storytelling,
parAcularly when it comes to describing processes.
So what I plan to do is spend a few minutes show you some of the tools and
emerging approaches I use working across the various steps of this pipeline.
3](https://image.slidesharecdn.com/gorsappropriate-160520133943/85/Gors-appropriate-3-320.jpg)
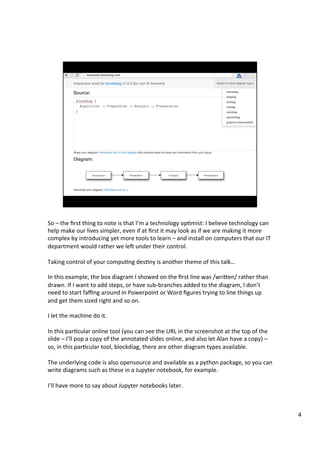

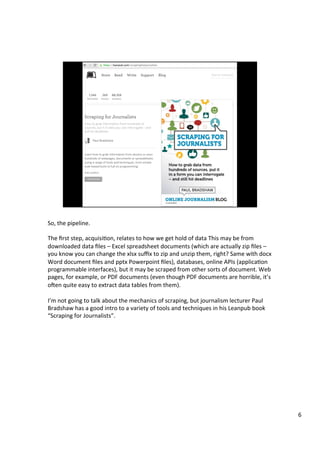
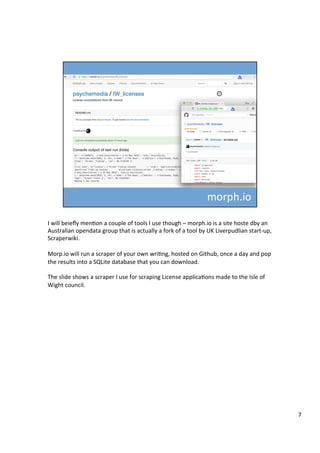



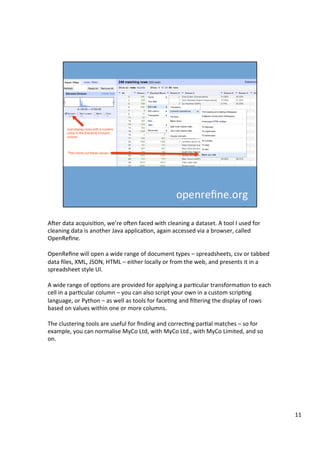

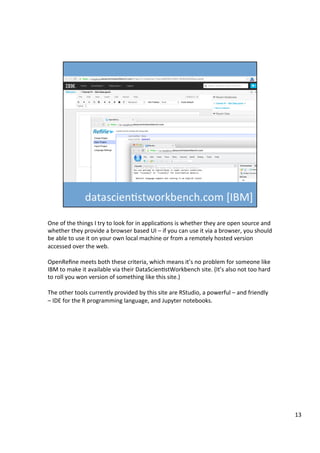
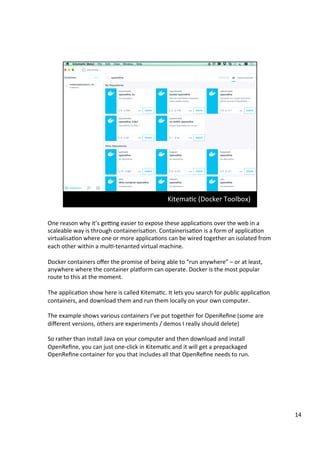
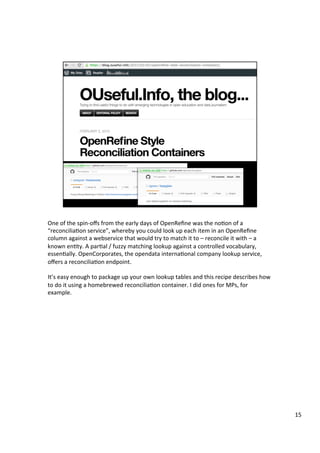













The document discusses various tools that can be used across different stages of the data pipeline, including acquisition, cleaning, and analysis. It describes scraping tools like Morph and Tabula that can extract data from websites and PDFs. For data cleaning, it recommends OpenRefine for tasks like normalization. It also discusses hosting tools like these in Docker containers to make them accessible via a web browser. Jupyter notebooks and RStudio are highlighted as useful for interactive data exploration and analysis.