




![Schema-Level Indices [Stuckenschmidt et al.
2004]
! Keep index of properties and/or classes contained in
sources
! (?s #p ?o), (?s rdf:type #o)
! Covers only queries containing schema-level elements
! Commonly used properties select potentially too many
sources
SELECT ?x1 ?x2 WHERE {
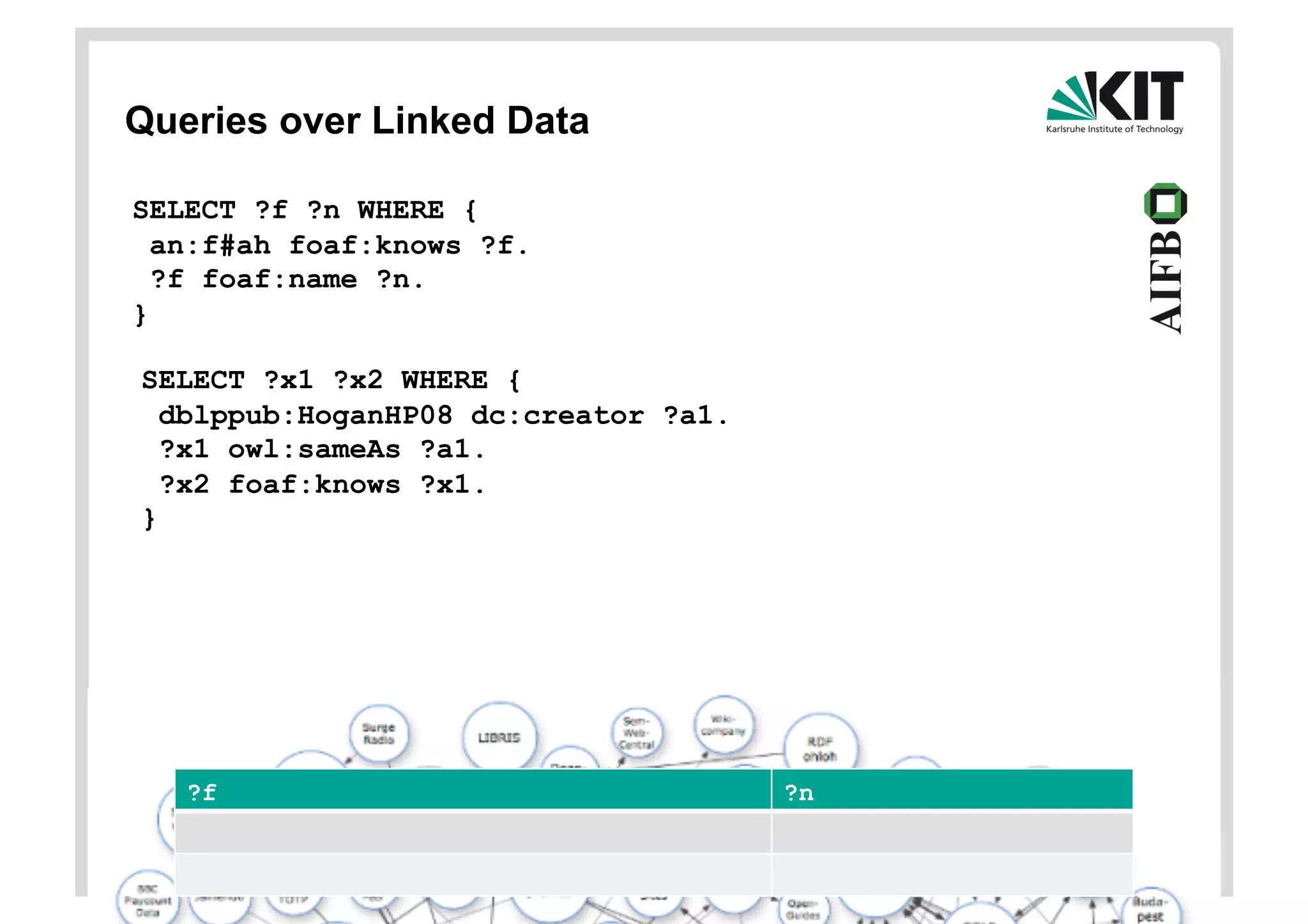
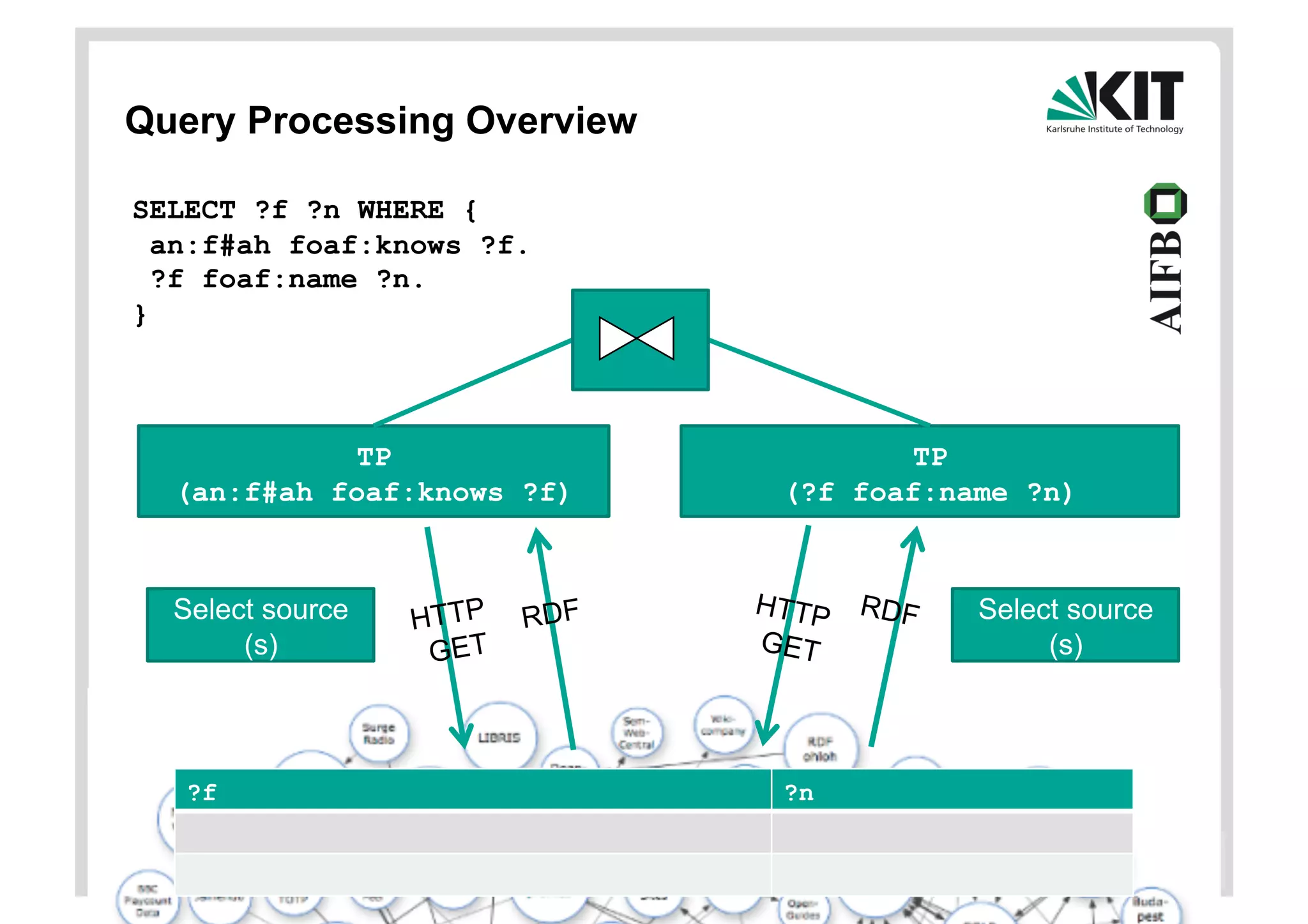
SELECT ?f ?n WHERE {
dblppub:HoganHP08 dc:creator ?a1.
an:f#ah foaf:knows ?f.
?x1 owl:sameAs ?a1.
?f foaf:name ?n.
?x2 foaf:knows ?x1.
}
}
14 15.03.2010 Andreas Harth KIT – University of the State of Baden-Wuerttemberg and
Data Summaries for On-Demand Queries over Linked Data National Laboratory of the Helmholtz Association](https://image.slidesharecdn.com/combinationsoflinkeddataandfunctionality-110810103008-phpapp01/75/Linked-Data-and-Sevices-14-2048.jpg)
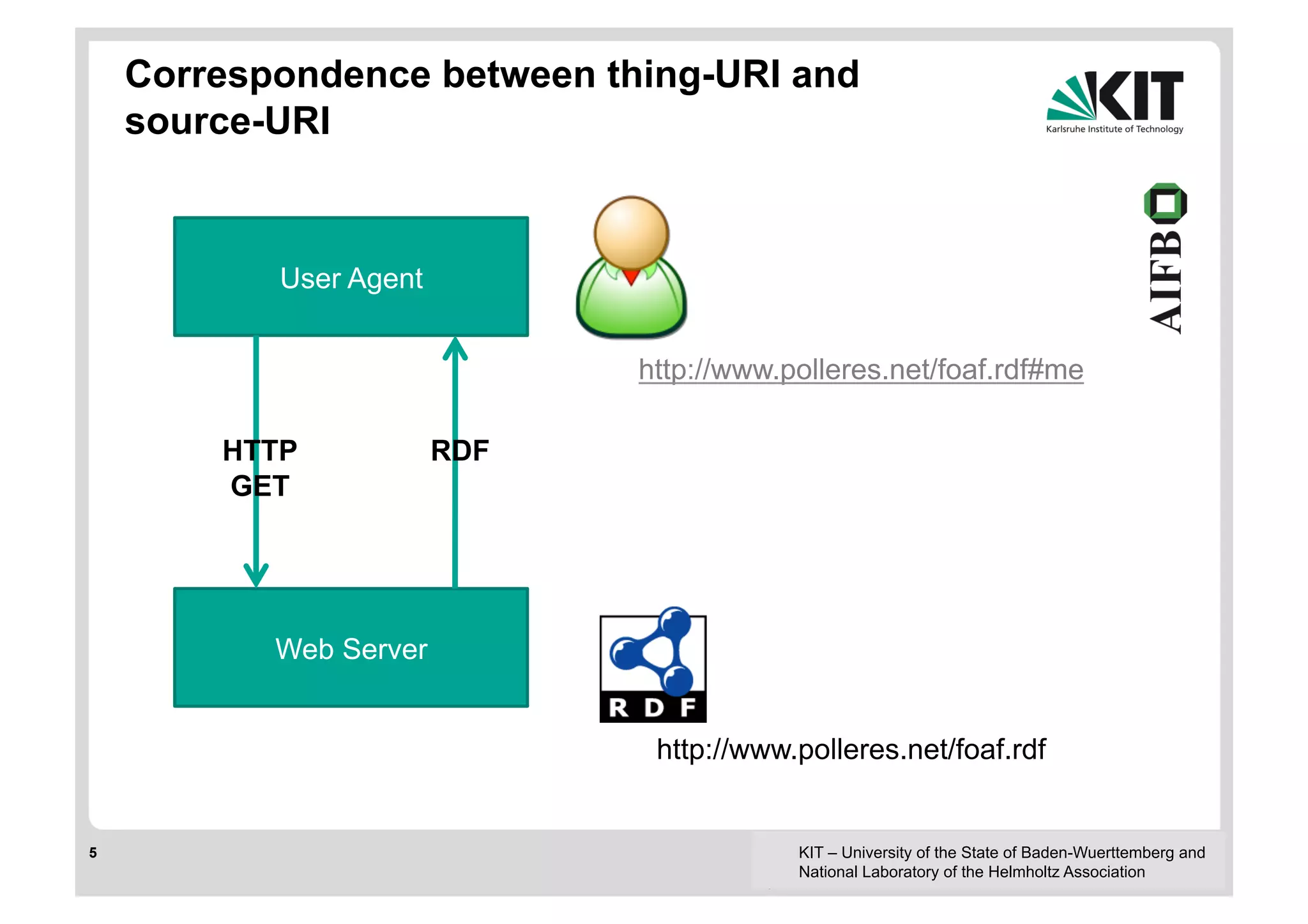
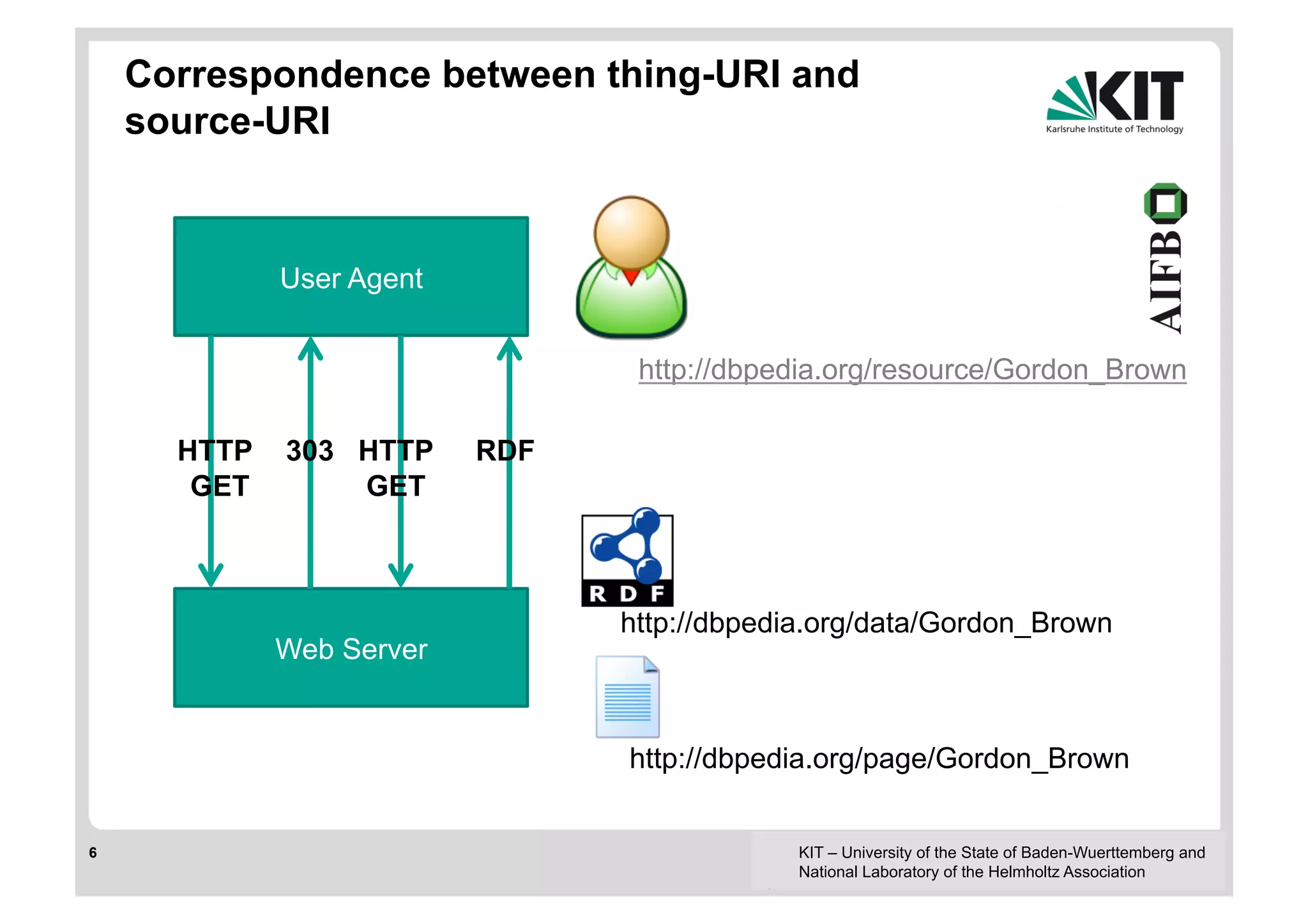
![Direct Lookup (DL) [Hartig et al. 2009]
! Exploits correspondence between thing-URI and source-URI
! Linked Data sources (aka RDF files) return typically triples with a
subject corresponding to the source
! Sometimes the sources return triples with object corresponding to the
source
! (#s ?p ?o), (#s #p ?o), (#s #p #o)
! (?s ?p #o), (?s #p #o)
! Incomplete wrt. patterns but also wrt. to URI reuse across sources
! Limited parallelism, unclear how to schedule lookups
SELECT ?x1 ?x2 WHERE {
SELECT ?f ?n WHERE {
dblppub:HoganHP08 dc:creator ?a1.
an:f#ah foaf:knows ?f.
?x1 owl:sameAs ?a1.
?f foaf:name ?n.
?x2 foaf:knows ?x1.
}
}
15 15.03.2010 Andreas Harth KIT – University of the State of Baden-Wuerttemberg and
Data Summaries for On-Demand Queries over Linked Data National Laboratory of the Helmholtz Association](https://image.slidesharecdn.com/combinationsoflinkeddataandfunctionality-110810103008-phpapp01/75/Linked-Data-and-Sevices-15-2048.jpg)


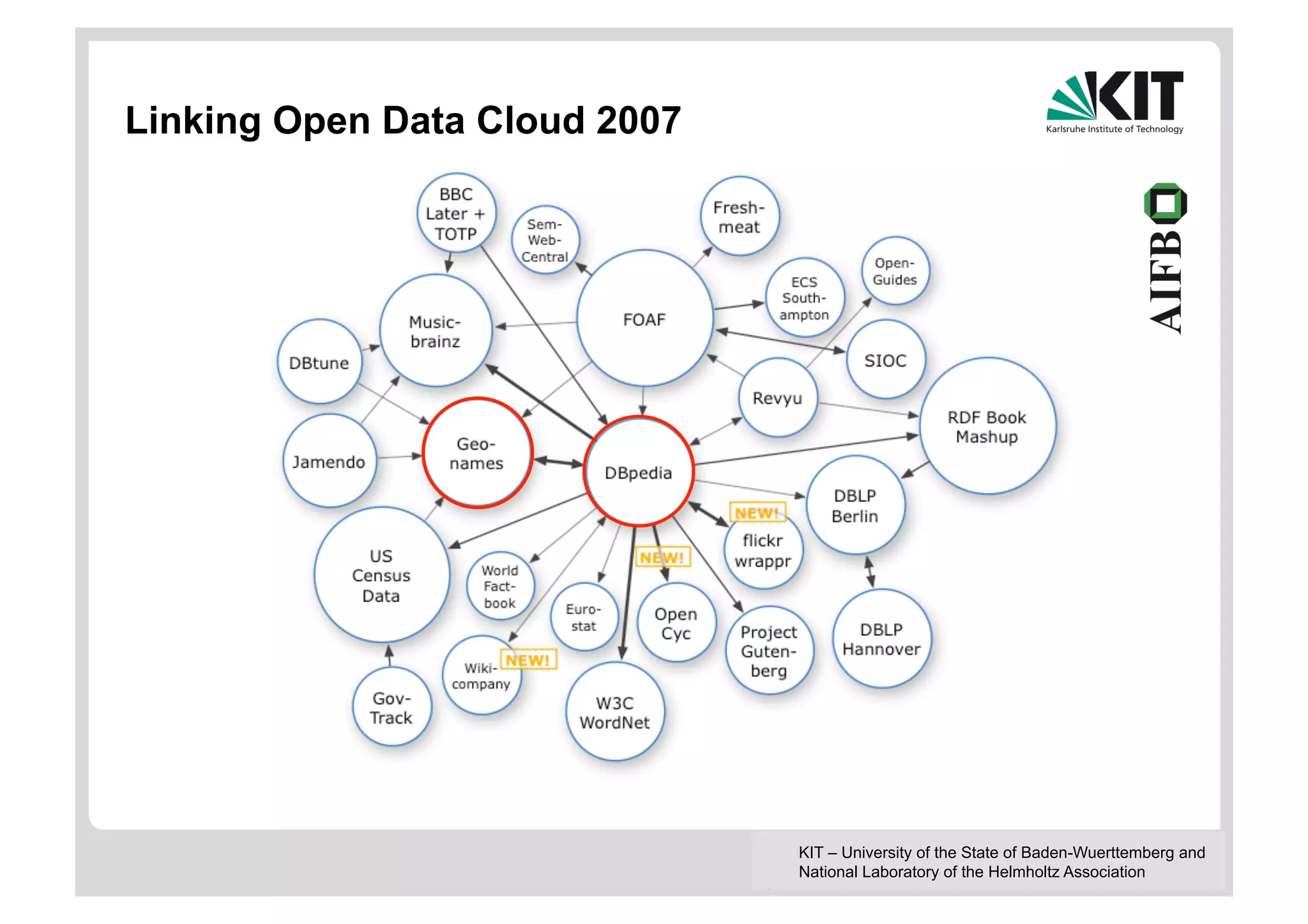
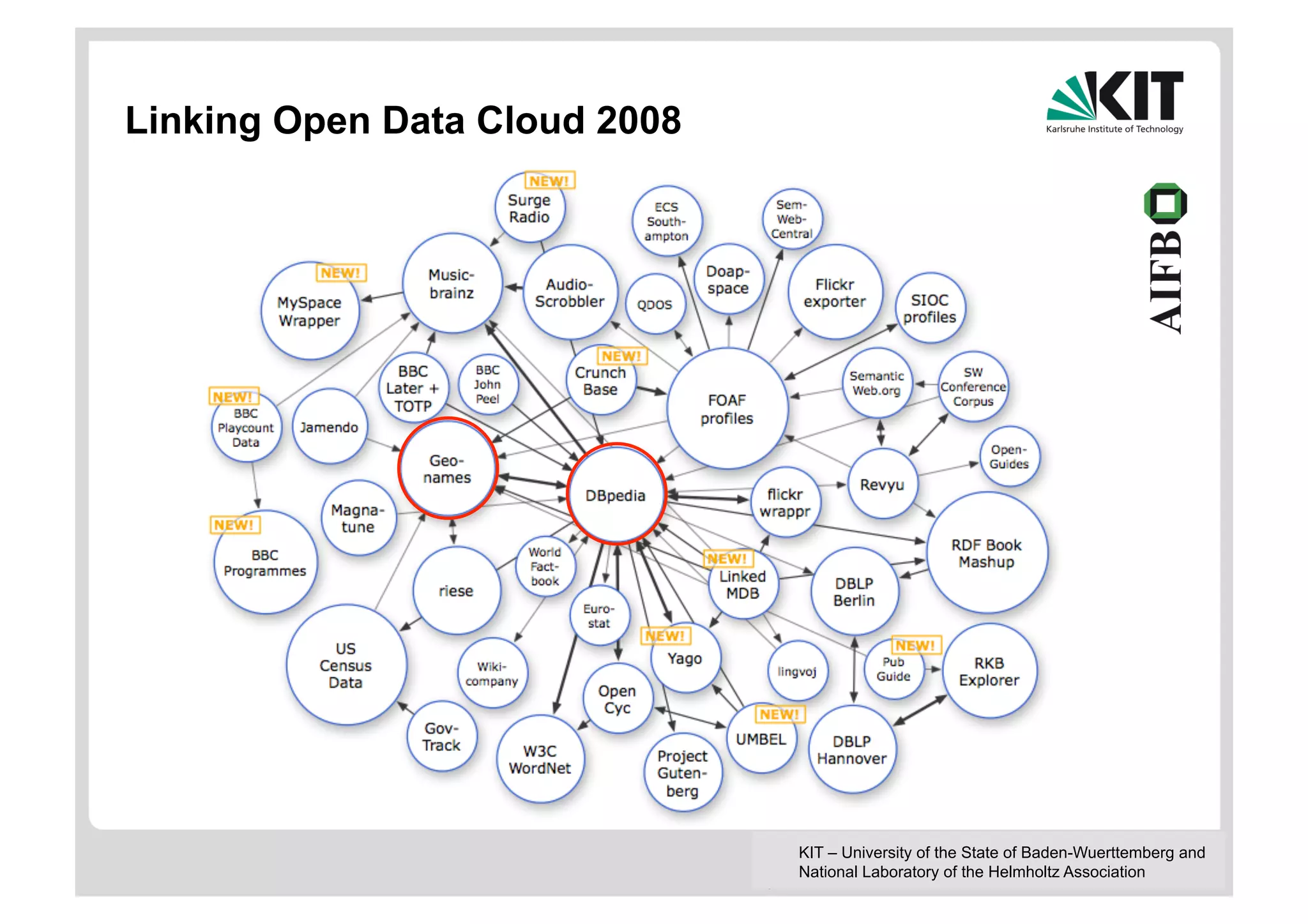

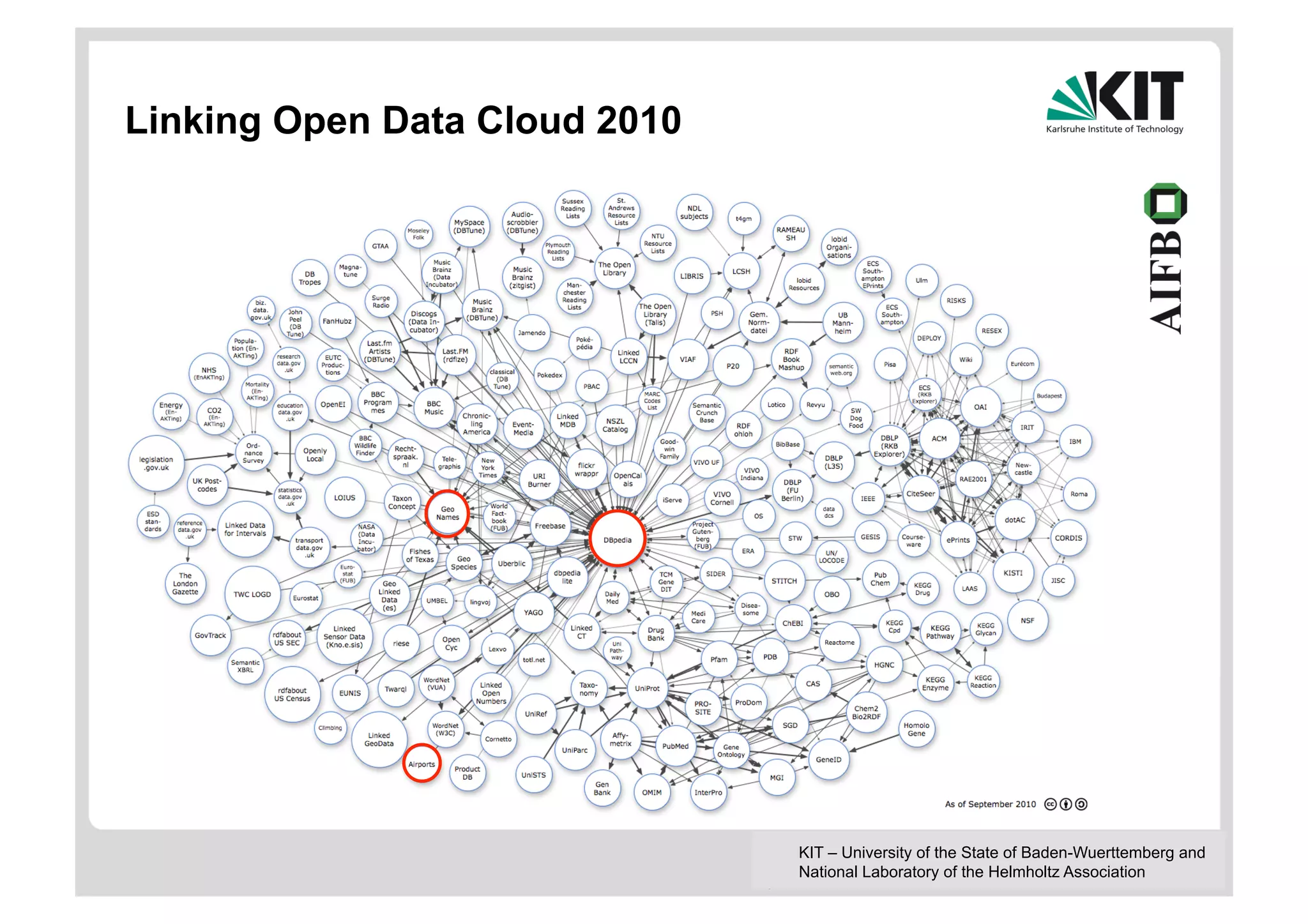




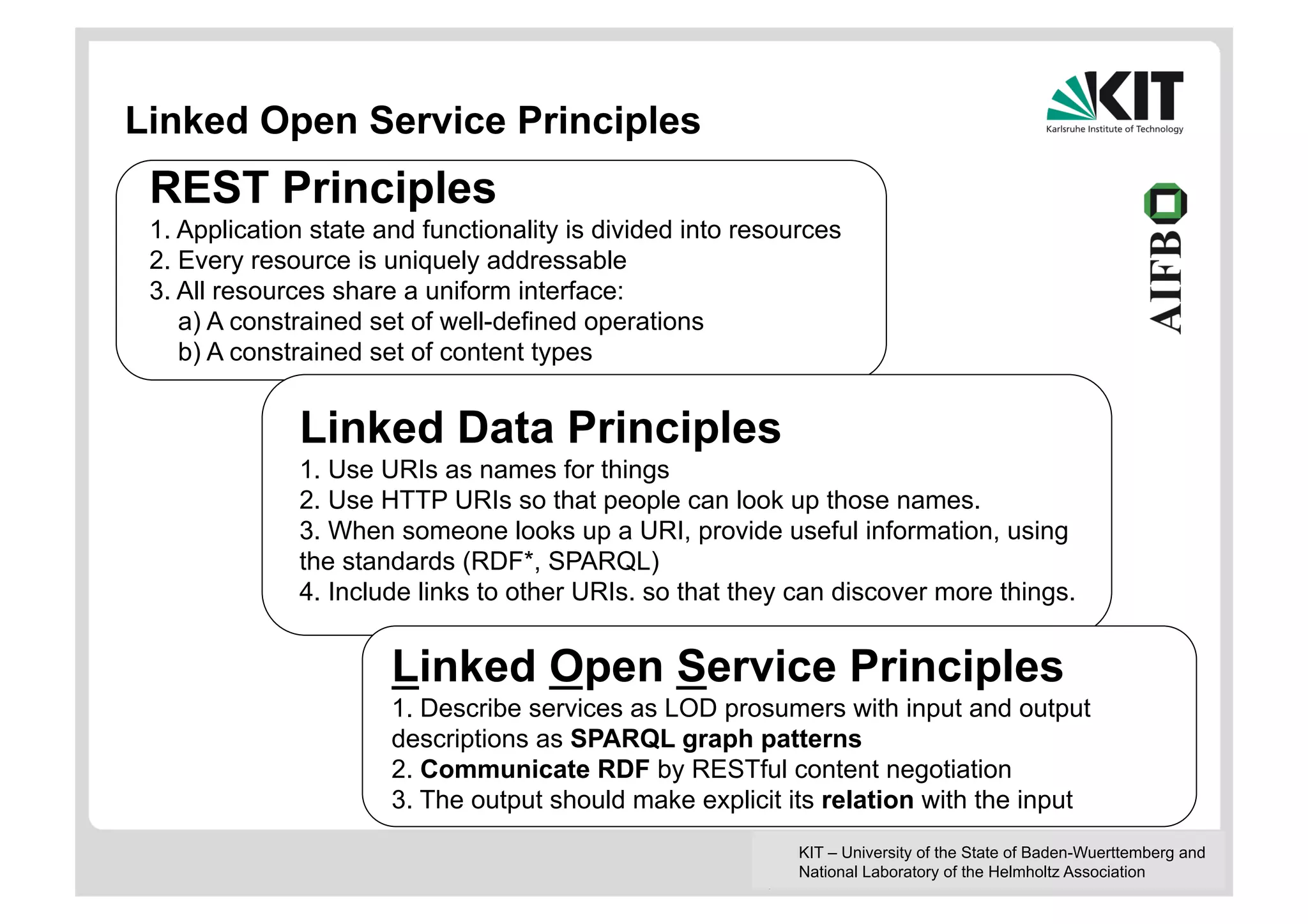
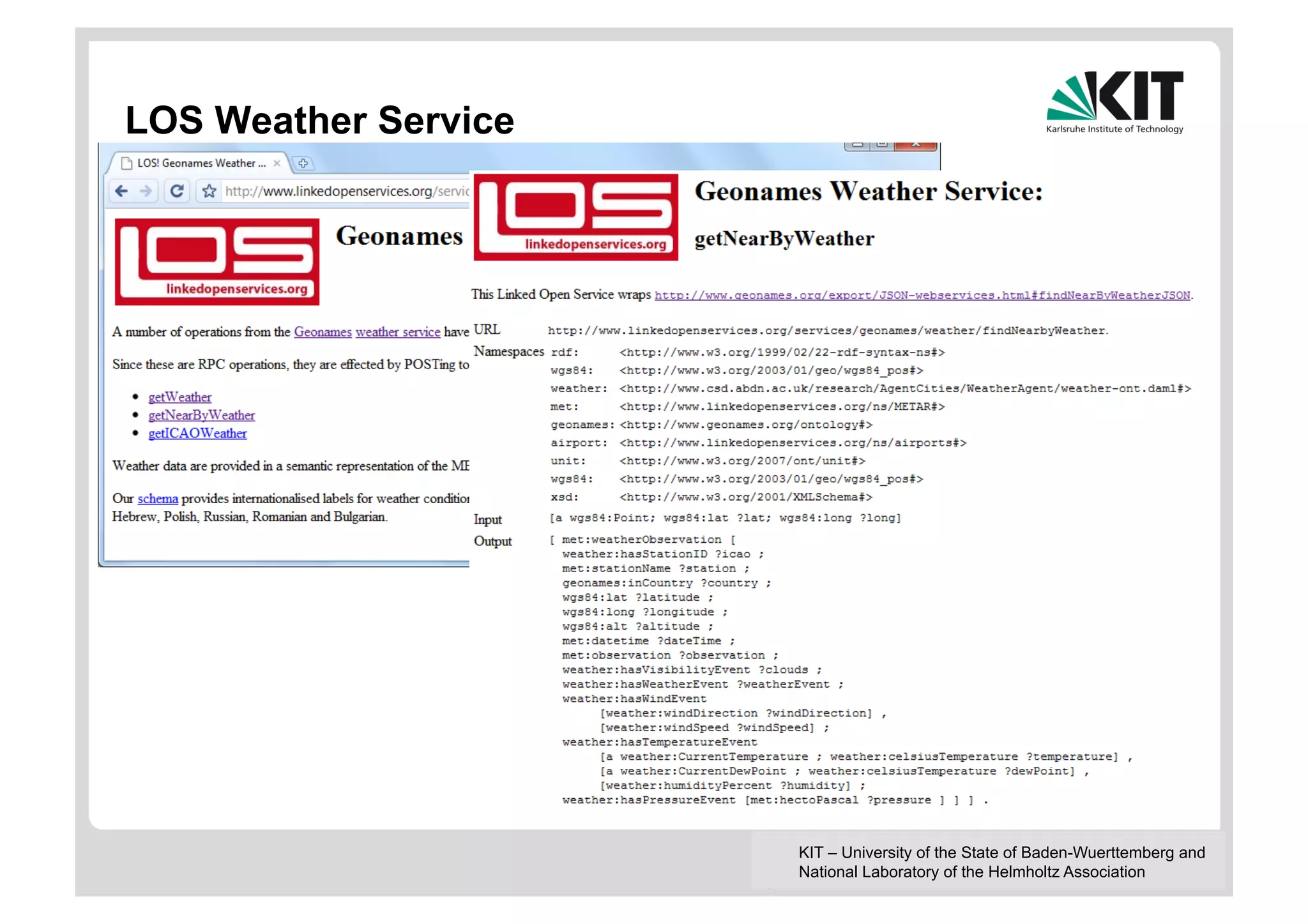
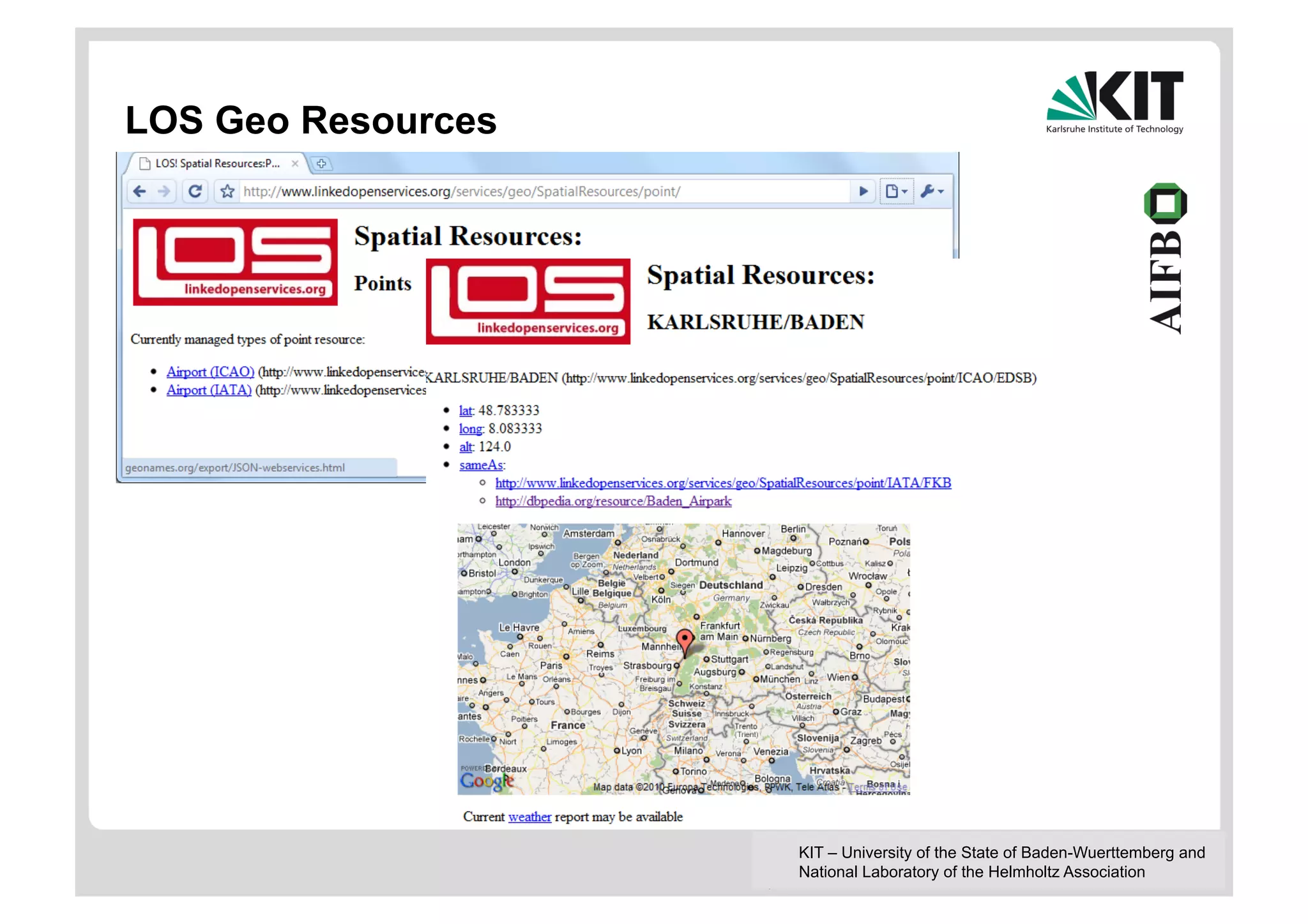

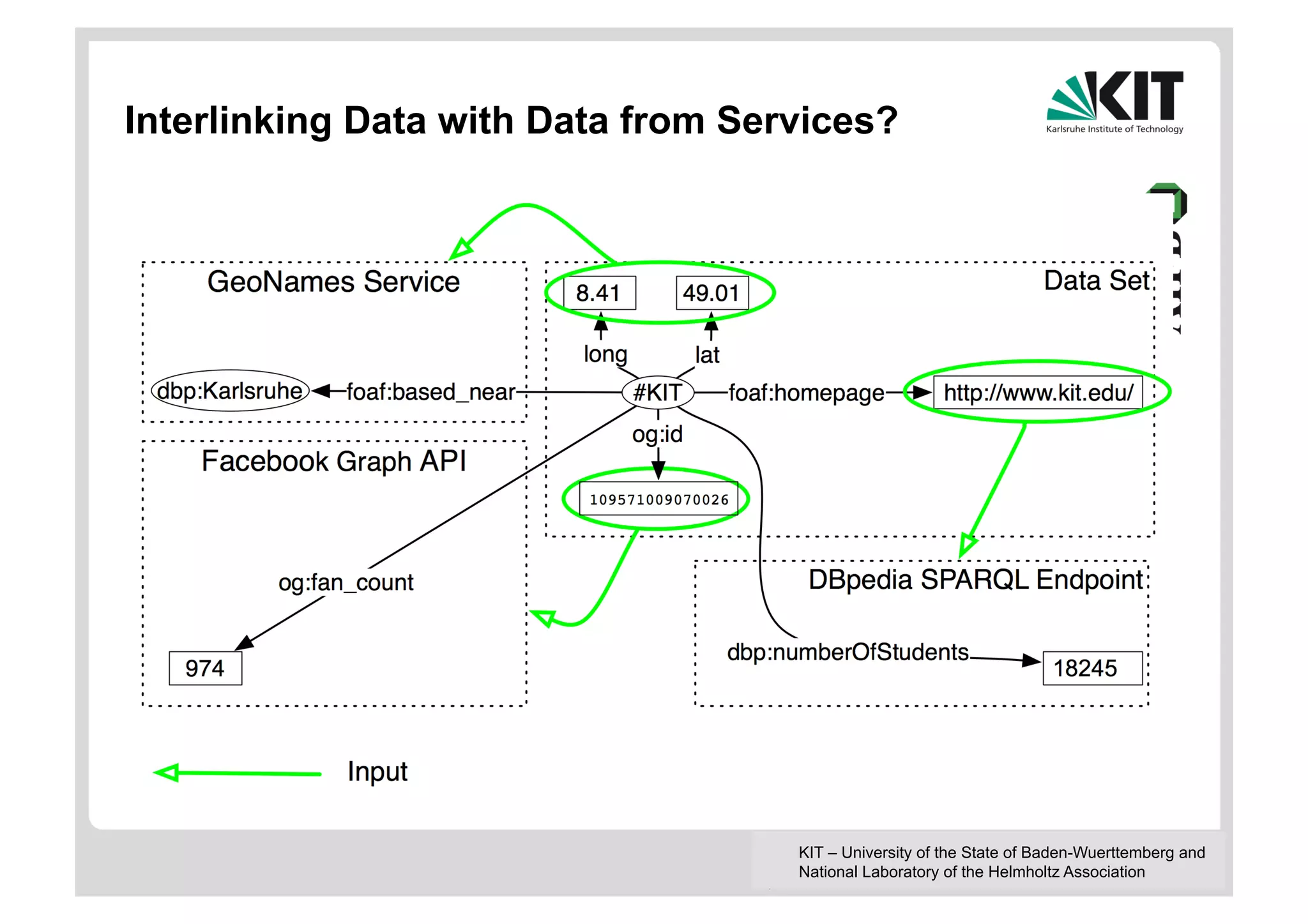
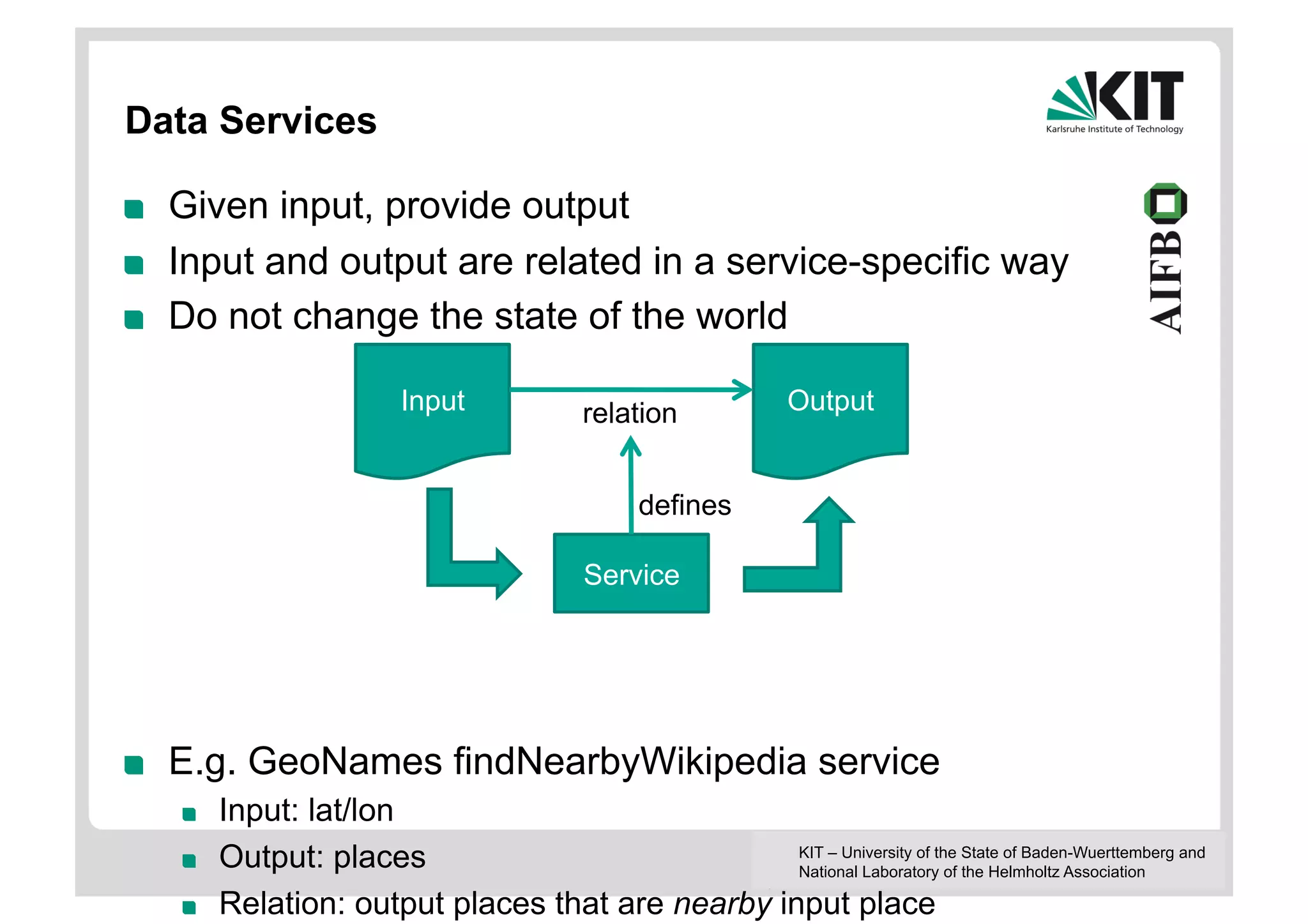

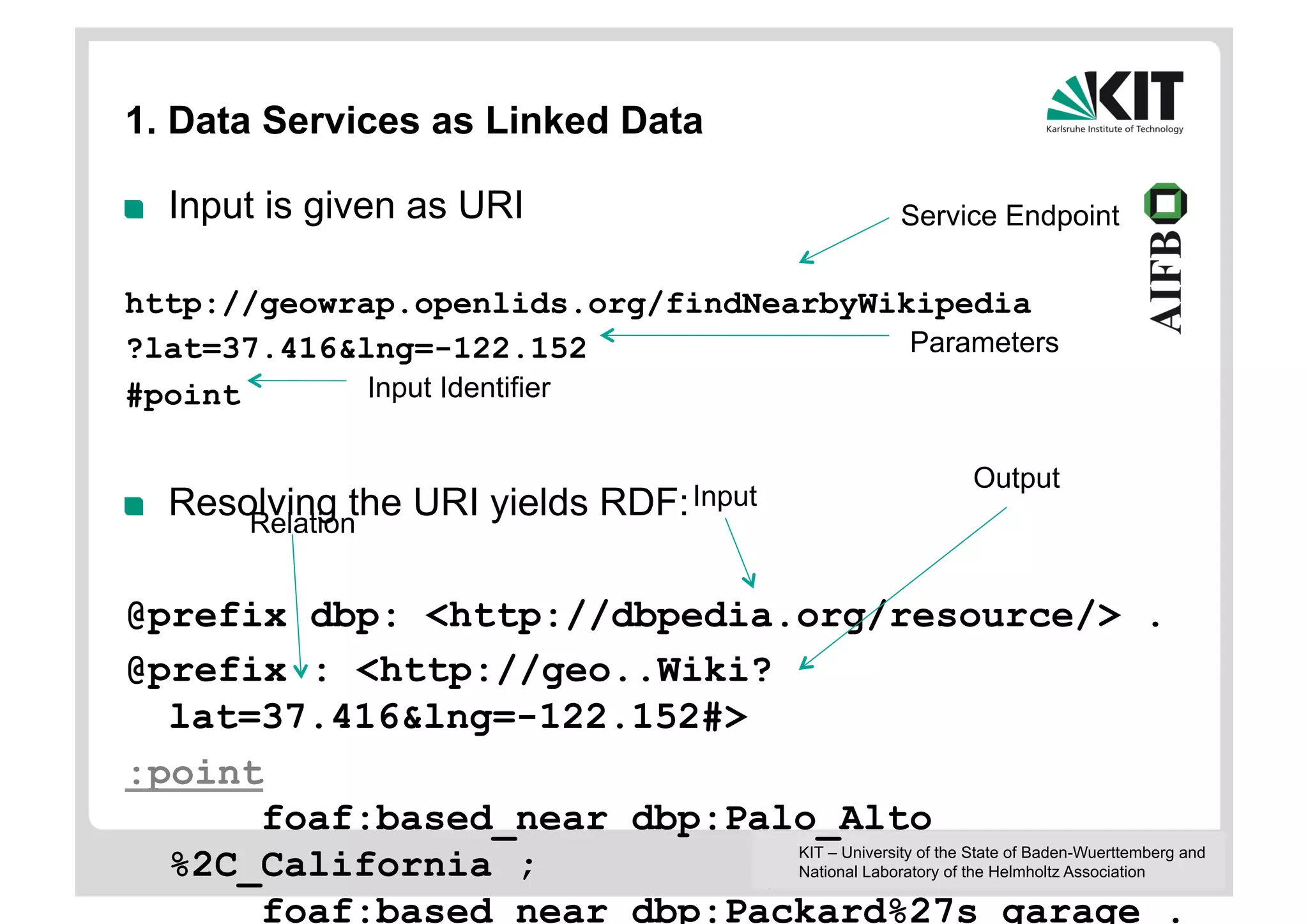

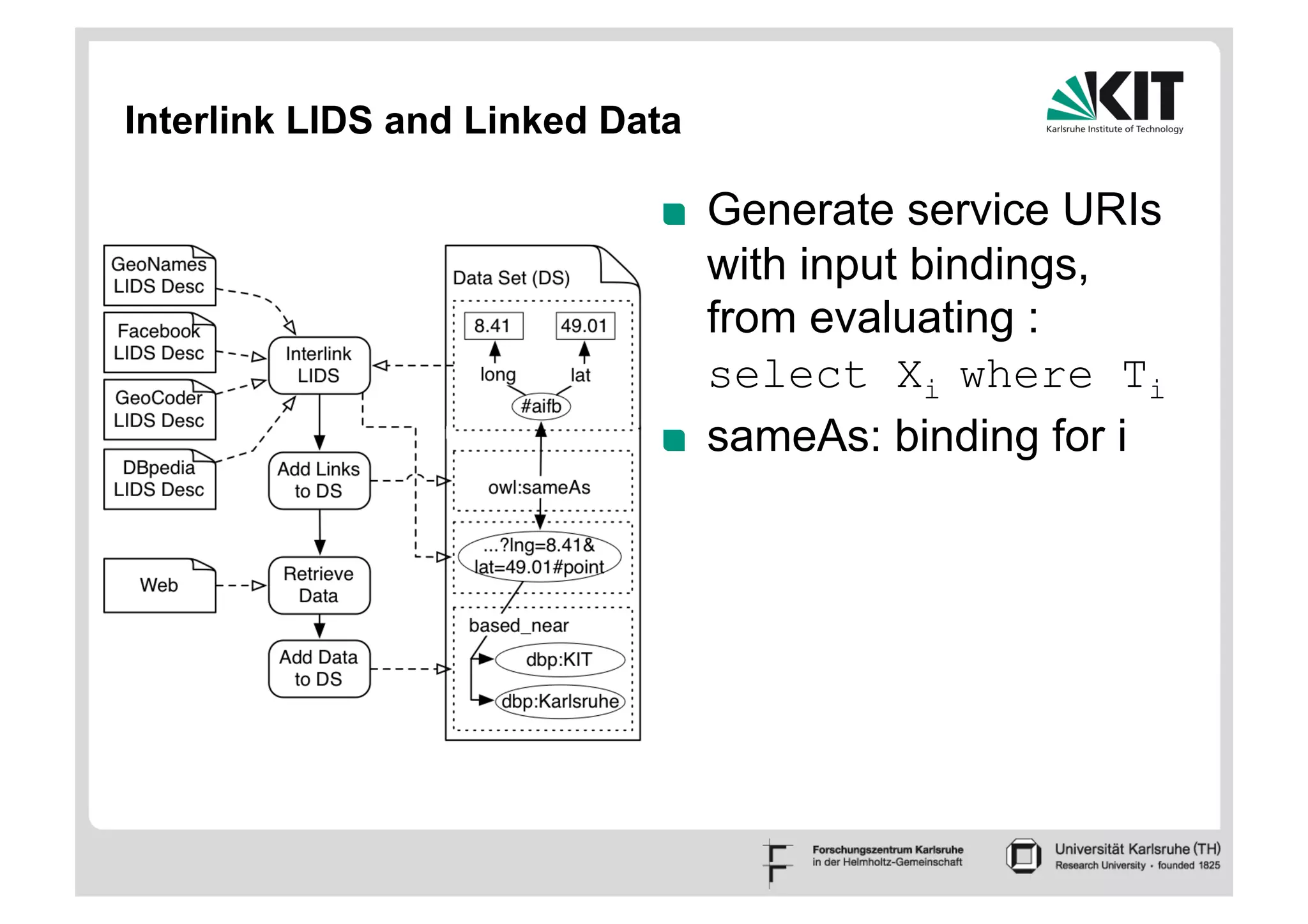

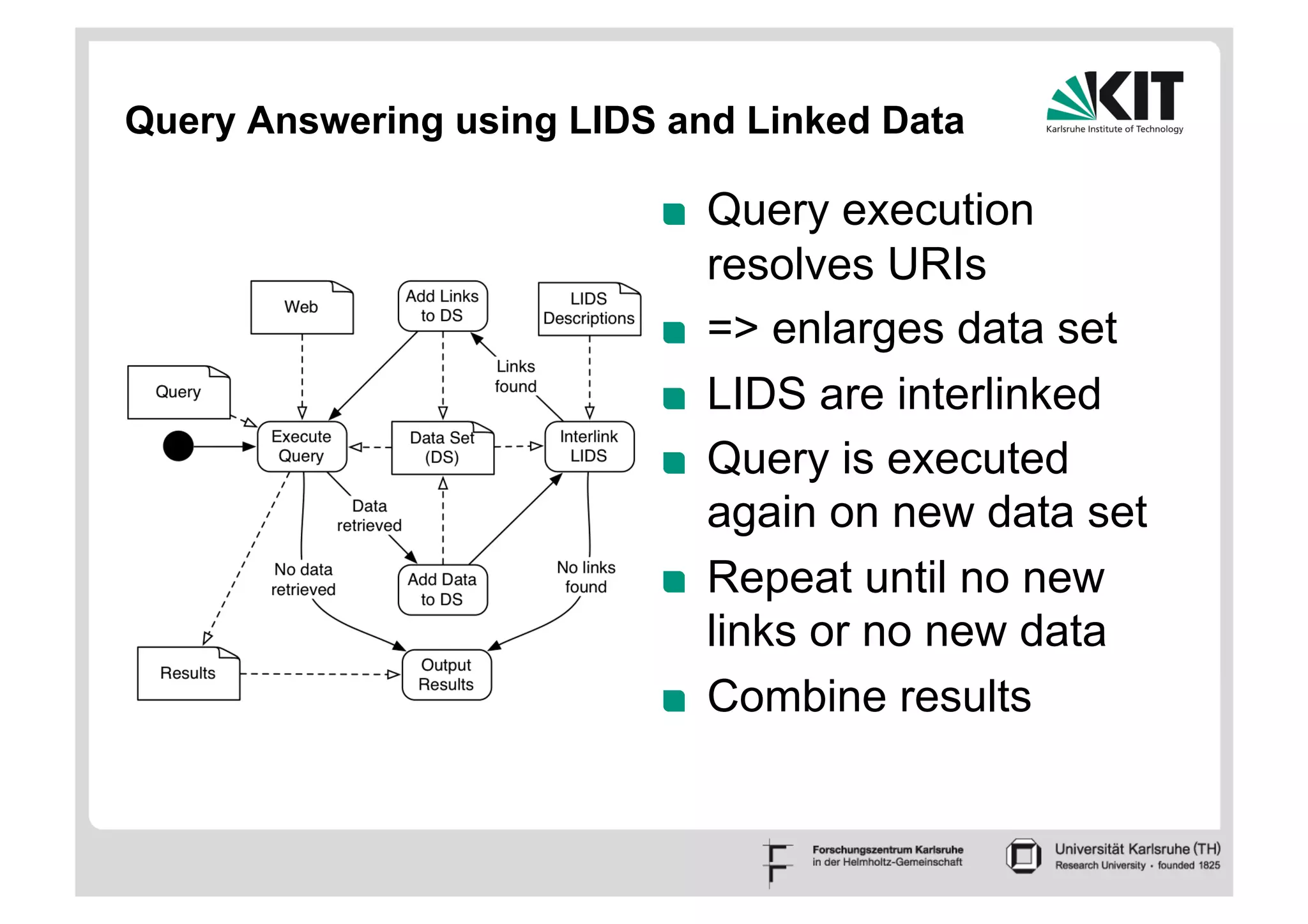



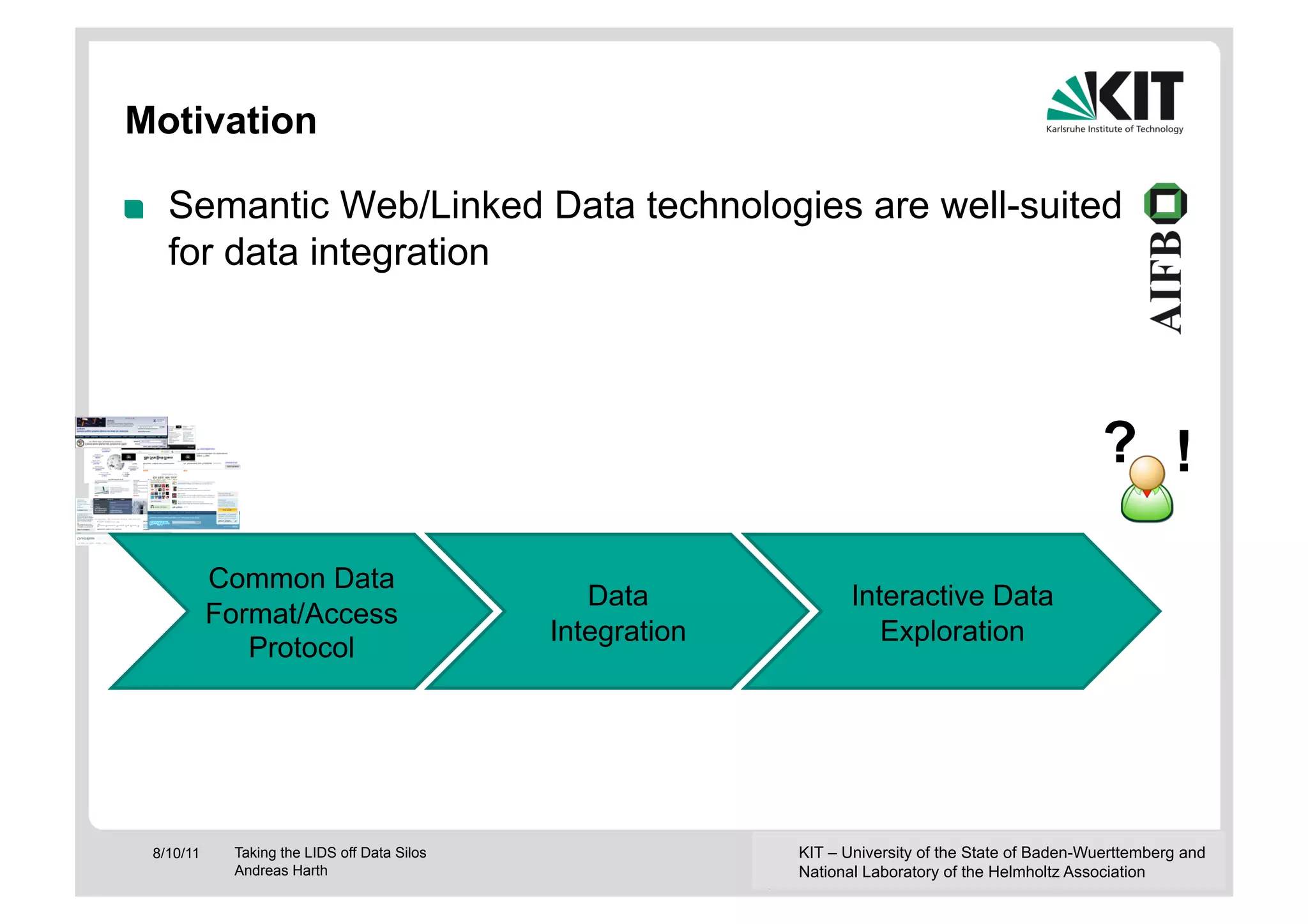
The document discusses linked data and services, emphasizing the principles of utilizing URIs for identification, HTTP URIs for data retrieval, and the provision of structured data in RDF format. It covers query processing methods for linked data, including distributed and materialization-based approaches, and outlines the integration of services with linked data through Linked Data Services (LIDs) and Linked Open Services (LOS). Additionally, it highlights the importance of machine-readable descriptions for data services and showcases examples of data querying and interlinking processes.


























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

















