Download to read offline





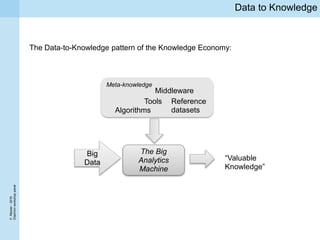
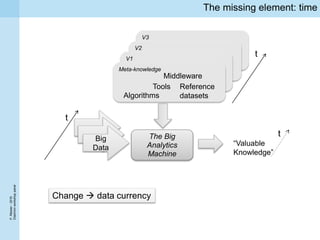

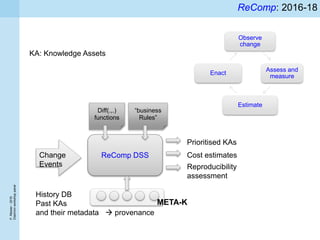
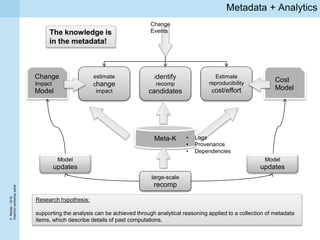

1) Traditional approaches to ensuring data quality such as quality assurance and curation face challenges from big data's volume, velocity, and variety characteristics. 2) It is difficult to determine general thresholds for when data quality issues can be ignored as the importance varies between different analytics algorithms. 3) The ReComp decision support system aims to use metadata about past analytics tasks to determine when knowledge needs to be refreshed due to changes in big data or models.







































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)















