Downloaded 53 times
















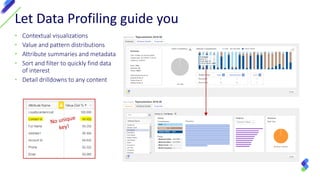

















The document discusses the importance of data profiling as the initial step to ensuring high-quality big data, highlighting the challenges posed by poor data quality, which can hinder decision-making, AI/ML applications, and corporate reputations. It details five key steps for effective data profiling, including understanding analysis goals, identifying relevant data, recognizing data types and issues, building useful rules, and ensuring clear communication regarding data quality. Ultimately, it emphasizes that data quality assessment is vital in a landscape increasingly reliant on accurate data for successful business outcomes.























































































