Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
michiaki ito
PPTX, PDF
38,570 views
機械学習を用いた異常検知入門
oscセミナー発表資料です。誤字は気にしないでください。 口頭で説明を足したところがあるため、曖昧な説明となっている箇所があったりします、ごめんなさい。
Technology
◦
Read more
59
Save
Share
Embed
Embed presentation
Download
Downloaded 252 times
1
/ 83
2
/ 83
3
/ 83
4
/ 83
5
/ 83
6
/ 83
7
/ 83
8
/ 83
9
/ 83
10
/ 83
11
/ 83
12
/ 83
13
/ 83
14
/ 83
15
/ 83
16
/ 83
17
/ 83
18
/ 83
19
/ 83
20
/ 83
21
/ 83
22
/ 83
23
/ 83
24
/ 83
25
/ 83
26
/ 83
27
/ 83
28
/ 83
29
/ 83
30
/ 83
31
/ 83
32
/ 83
33
/ 83
34
/ 83
35
/ 83
36
/ 83
37
/ 83
38
/ 83
39
/ 83
40
/ 83
41
/ 83
42
/ 83
43
/ 83
44
/ 83
45
/ 83
46
/ 83
47
/ 83
48
/ 83
49
/ 83
50
/ 83
51
/ 83
52
/ 83
53
/ 83
54
/ 83
55
/ 83
56
/ 83
57
/ 83
58
/ 83
59
/ 83
60
/ 83
61
/ 83
62
/ 83
63
/ 83
64
/ 83
65
/ 83
66
/ 83
67
/ 83
68
/ 83
69
/ 83
70
/ 83
71
/ 83
72
/ 83
73
/ 83
74
/ 83
75
/ 83
76
/ 83
77
/ 83
78
/ 83
79
/ 83
80
/ 83
81
/ 83
82
/ 83
83
/ 83
More Related Content
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PDF
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
PDF
4 データ間の距離と類似度
by
Seiichi Uchida
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
PDF
DQNからRainbowまで 〜深層強化学習の最新動向〜
by
Jun Okumura
PPTX
マルチモーダル深層学習の研究動向
by
Koichiro Mori
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
4 データ間の距離と類似度
by
Seiichi Uchida
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
DQNからRainbowまで 〜深層強化学習の最新動向〜
by
Jun Okumura
マルチモーダル深層学習の研究動向
by
Koichiro Mori
What's hot
PPTX
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
PDF
相関と因果について考える:統計的因果推論、その(不)可能性の中心
by
takehikoihayashi
PDF
EMアルゴリズム
by
Sotetsu KOYAMADA(小山田創哲)
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PDF
A summary on “On choosing and bounding probability metrics”
by
Kota Matsui
PDF
LDA入門
by
正志 坪坂
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
PDF
Kaggleのテクニック
by
Yasunori Ozaki
PDF
“機械学習の説明”の信頼性
by
Satoshi Hara
PDF
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
PPTX
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021)
by
Deep Learning JP
PDF
数学で解き明かす深層学習の原理
by
Taiji Suzuki
PDF
時系列問題に対するCNNの有用性検証
by
Masaharu Kinoshita
PDF
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
PPTX
画像処理AIを用いた異常検知
by
Hideo Terada
PDF
PRML学習者から入る深層生成モデル入門
by
tmtm otm
PDF
データ解析10 因子分析の基礎
by
Hirotaka Hachiya
PDF
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
by
Deep Learning JP
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
相関と因果について考える:統計的因果推論、その(不)可能性の中心
by
takehikoihayashi
EMアルゴリズム
by
Sotetsu KOYAMADA(小山田創哲)
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
A summary on “On choosing and bounding probability metrics”
by
Kota Matsui
LDA入門
by
正志 坪坂
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
Kaggleのテクニック
by
Yasunori Ozaki
“機械学習の説明”の信頼性
by
Satoshi Hara
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021)
by
Deep Learning JP
数学で解き明かす深層学習の原理
by
Taiji Suzuki
時系列問題に対するCNNの有用性検証
by
Masaharu Kinoshita
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
画像処理AIを用いた異常検知
by
Hideo Terada
PRML学習者から入る深層生成モデル入門
by
tmtm otm
データ解析10 因子分析の基礎
by
Hirotaka Hachiya
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
by
Deep Learning JP
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
Viewers also liked
PDF
FIT2012招待講演「異常検知技術のビジネス応用最前線」
by
Shohei Hido
PDF
Jubatus Casual Talks #2 異常検知入門
by
Shohei Hido
PDF
時系列分析による異常検知入門
by
Yohei Sato
PDF
外れ値
by
Shintaro Fukushima
PDF
Anomaly detection in deep learning
by
Adam Gibson
PDF
学位論文の書き方メモ (Tips for writing thesis)
by
Nobuyuki Umetani
PDF
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平
by
Preferred Networks
PPTX
【Zansa】物理学はWebデータ分析に使えるか
by
Zansa
PPTX
Sano web広告最適化20131018v3
by
Masakazu Sano
PDF
機械学習によるリモートネットワークの異常検知
by
cloretsblack
PDF
異常検知と変化検知 9章 部分空間法による変化点検知
by
hagino 3000
PDF
Wireshark だけに頼らない! パケット解析ツールの紹介
by
morihisa
PDF
Strata Beijing 2017: Jumpy, a python interface for nd4j
by
Adam Gibson
PDF
Tokyo r15 異常検知入門
by
Yohei Sato
PDF
20140213 web×マス広告の統合分析第3部_公開用
by
Cyberagent
PDF
[R勉強会][データマイニング] R言語による時系列分析
by
Koichi Hamada
PDF
KDD2014_study
by
正志 坪坂
PDF
Kobe.r勉強会資料
by
kobexr
PDF
IoTでAzureのサービス利用~専門知識なしで始める超入門~
by
Kousuke Takada
PDF
Kansai Azure Azure Overview & Update 20140926
by
Ayako Omori
FIT2012招待講演「異常検知技術のビジネス応用最前線」
by
Shohei Hido
Jubatus Casual Talks #2 異常検知入門
by
Shohei Hido
時系列分析による異常検知入門
by
Yohei Sato
外れ値
by
Shintaro Fukushima
Anomaly detection in deep learning
by
Adam Gibson
学位論文の書き方メモ (Tips for writing thesis)
by
Nobuyuki Umetani
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平
by
Preferred Networks
【Zansa】物理学はWebデータ分析に使えるか
by
Zansa
Sano web広告最適化20131018v3
by
Masakazu Sano
機械学習によるリモートネットワークの異常検知
by
cloretsblack
異常検知と変化検知 9章 部分空間法による変化点検知
by
hagino 3000
Wireshark だけに頼らない! パケット解析ツールの紹介
by
morihisa
Strata Beijing 2017: Jumpy, a python interface for nd4j
by
Adam Gibson
Tokyo r15 異常検知入門
by
Yohei Sato
20140213 web×マス広告の統合分析第3部_公開用
by
Cyberagent
[R勉強会][データマイニング] R言語による時系列分析
by
Koichi Hamada
KDD2014_study
by
正志 坪坂
Kobe.r勉強会資料
by
kobexr
IoTでAzureのサービス利用~専門知識なしで始める超入門~
by
Kousuke Takada
Kansai Azure Azure Overview & Update 20140926
by
Ayako Omori
Similar to 機械学習を用いた異常検知入門
PDF
『機械学習による故障予測・異常検知 事例紹介とデータ分析プロジェクト推進ポイント』
by
The Japan DataScientist Society
PDF
機械学習 入門
by
Hayato Maki
PDF
R実践 機械学習による異常検知 01
by
akira_11
PDF
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V k-1
by
Shunsuke Nakamura
PDF
bigdata2012ml okanohara
by
Preferred Networks
PDF
Anomaly detection survey
by
ぱんいち すみもと
PDF
20180807_全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
PDF
再考: お買い得物件を機械学習で見つける方法
by
智志 片桐
PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで
by
Shunsuke Nakamura
PPTX
MLaPP輪講 Chapter 1
by
ryuhmd
PPTX
2020/11/19 Global AI on Tour - Toyama プログラマーのための機械学習入門
by
Daiyu Hatakeyama
PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V7
by
Shunsuke Nakamura
PDF
ユークリッド距離以外の距離で教師無しクラスタリング
by
Maruyama Tetsutaro
PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで Vm 1
by
Shunsuke Nakamura
PDF
異常検知 - 何を探すかよく分かっていないものを見つける方法
by
MapR Technologies Japan
PPTX
機械学習の基礎
by
Ken Kumagai
PDF
2013 JOI春合宿 講義6 機械学習入門
by
Hiroshi Yamashita
PDF
機械学習の理論と実践
by
Preferred Networks
PDF
Pythonによる機械学習入門 ~Deep Learningに挑戦~
by
Yasutomo Kawanishi
PDF
機械学習とコンピュータビジョン入門
by
Kinki University
『機械学習による故障予測・異常検知 事例紹介とデータ分析プロジェクト推進ポイント』
by
The Japan DataScientist Society
機械学習 入門
by
Hayato Maki
R実践 機械学習による異常検知 01
by
akira_11
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V k-1
by
Shunsuke Nakamura
bigdata2012ml okanohara
by
Preferred Networks
Anomaly detection survey
by
ぱんいち すみもと
20180807_全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
再考: お買い得物件を機械学習で見つける方法
by
智志 片桐
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで
by
Shunsuke Nakamura
MLaPP輪講 Chapter 1
by
ryuhmd
2020/11/19 Global AI on Tour - Toyama プログラマーのための機械学習入門
by
Daiyu Hatakeyama
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V7
by
Shunsuke Nakamura
ユークリッド距離以外の距離で教師無しクラスタリング
by
Maruyama Tetsutaro
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで Vm 1
by
Shunsuke Nakamura
異常検知 - 何を探すかよく分かっていないものを見つける方法
by
MapR Technologies Japan
機械学習の基礎
by
Ken Kumagai
2013 JOI春合宿 講義6 機械学習入門
by
Hiroshi Yamashita
機械学習の理論と実践
by
Preferred Networks
Pythonによる機械学習入門 ~Deep Learningに挑戦~
by
Yasutomo Kawanishi
機械学習とコンピュータビジョン入門
by
Kinki University
More from michiaki ito
PPTX
Introduction of Xgboost
by
michiaki ito
PPTX
Character Level Convolutional Neural Networkによる悪性文字列検知手法
by
michiaki ito
PPTX
機械学習×セキュリティ
by
michiaki ito
PPTX
迷惑メールフィルタの作り方
by
michiaki ito
PPTX
トラコン問題解説
by
michiaki ito
PPTX
12/28Kogcoder
by
michiaki ito
PPTX
グループワーク3-A
by
michiaki ito
PPTX
サイドチャネル攻撃講義成果報告
by
michiaki ito
Introduction of Xgboost
by
michiaki ito
Character Level Convolutional Neural Networkによる悪性文字列検知手法
by
michiaki ito
機械学習×セキュリティ
by
michiaki ito
迷惑メールフィルタの作り方
by
michiaki ito
トラコン問題解説
by
michiaki ito
12/28Kogcoder
by
michiaki ito
グループワーク3-A
by
michiaki ito
サイドチャネル攻撃講義成果報告
by
michiaki ito
機械学習を用いた異常検知入門
1.
機械学習を用いた 異常検知入門 セキュリティキャンプ2015全国大会終了生 伊東 道明
2.
自己紹介 • 伊東 道明 •
法政大学 理工学部 3年 • Cpaw 代表 • ICTSC 運営 • セキュリティキャンプ2015修了生 • 某社でお仕事のお手伝い中 2
3.
自己紹介 • 分野:ML/インフラ/セキュリティなど • エディタ:emacs/sublimetext •
言語:python • 最近やってること:SDN/Webサーバー開発 • 趣味:自転車始めました 3
4.
セキュリティキャンプの紹介 • IPAが主催しているセキュリティ合宿 • タダでご飯が食べられる! •
業界の有名人に会える! • もちろん楽しい講義もたくさん! • 22歳以下の学生は是非! 4
5.
Cpawの紹介 • IT団体 • 面白そうなことをお金の限りやる •
LT大会、CTF、競プロなども • 主に工学院大学、法政大学で活動 • 202教室で「走るIoT自動販売機」や 「CpawCTFサイト」などを展示中 5
6.
アジェンダ 1. 機械学習について 2. セキュリティについて 3.
K-meansを使った異常検知 4. Spectral clusteringの提案 5. Deep learningの提案 6. まとめ 6
7.
7 機械学習について
8.
機械学習とは • 人間が自然に行っている学習能力を、コ ンピュータで実現しようとする技術。 • 様々なデータをコンピュータに反復学習 させ、データに潜在的なパターンを見つ け出す。 8
9.
機械学習の主な目的 • 未来予測 • クラス分類 •
クラスタリング • などなど… 9
10.
1.未来予測 • 今までのデータから、未来のデータの値 を予測する。 • 線形回帰やランダムフォレストなど。 10
11.
未来予測の例 • 来客者数の予測 • 機械故障率の予測 •
売上高や株価の予測 11
12.
2.クラス分類 • データを幾つかの結果に分類する。 • SVM、ニューラルネットワークなど。 12
13.
クラス分類の例 • 手書き文字認識 • 植物病害診断 •
Webページのジャンル分類 13
14.
3.クラスタリング • 大量のデータを、任意のクラスタに分け る。 • K-means法、Ward法など。 14
15.
クラスタリングの例 • 広告のクリック数情報によるユーザの 傾向分析 − アドテクに応用可能 •
レコメンドシステム 15
16.
16 異常検知について
17.
異常検知とは • データの中で異常なデータを検出する。 17
18.
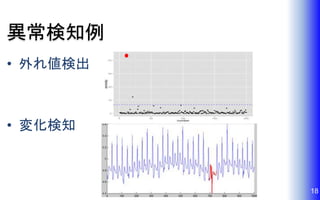
異常検知例 • 外れ値検出 • 変化検知 18
19.
異常検知の既存手法例 • K-meansによる異常検知 − IDSなど •
単純ベイズ法による異常検知 − 迷惑メールフィルタなど 19
20.
20 セキュリティについて
21.
セキュリティの重要性 • 近年、IoT化などが進み、セキュリティの 重要性が高まっている。 • 攻撃手法が日々進化してきており、防御 が難しくなりつつある。 21
22.
機械学習を用いた防御手法 • シグネチャによるパターンマッチングな どの対策では対策が追いつかず不十分な ときも… • 機械学習を用いた対策が有効? 22
23.
機械学習を用いる利点(例) • ICMPパケットに長い文字列をくっつけて 送るとシェルを奪える脆弱性が見つかっ たとする。 23
24.
機械学習を用いる利点(例) • シグネチャ型などの防御手法では異常を 検知できず、攻撃を受けてしまう。 • 機械学習を用いた防御手法なら、未知の 攻撃でも異常と判断し、防ぐことができ る可能性がある。 24
25.
ここまでのまとめ • 機械学習が様々な分野で活躍している。 • サイバー攻撃の攻撃力が年々増している。 •
セキュリティに機械学習を活用すること で、防御力が上がる可能性がある。 25
26.
26 ここから具体例
27.
27 K-meansを用いて 異常を検知する
28.
28 K-meansについて
29.
K-means • とても単純なクラスタリング手法 • 日本語ではK平均法と呼ぶ 29
30.
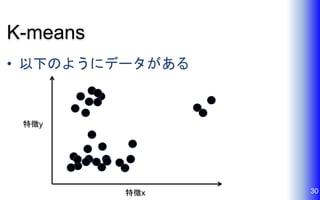
K-means • 以下のようにデータがある 30特徴x 特徴y
31.
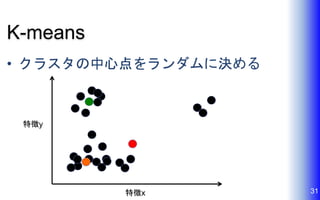
K-means • クラスタの中心点をランダムに決める 31特徴x 特徴y
32.
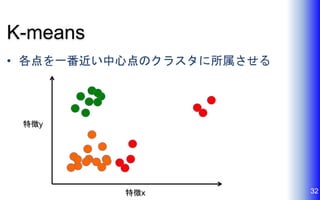
K-means • 各点を一番近い中心点のクラスタに所属させる 32特徴x 特徴y
33.
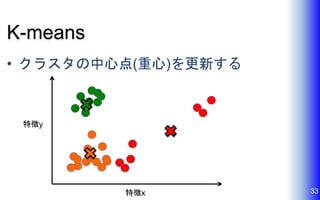
K-means • クラスタの中心点(重心)を更新する 33特徴x 特徴y
34.
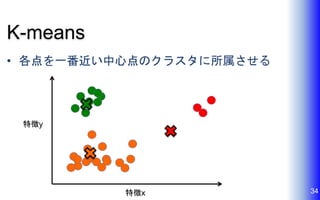
K-means • 各点を一番近い中心点のクラスタに所属させる 34特徴x 特徴y
35.
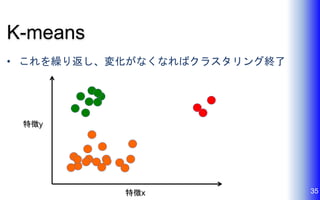
K-means • これを繰り返し、変化がなくなればクラスタリング終了 35特徴x 特徴y
36.
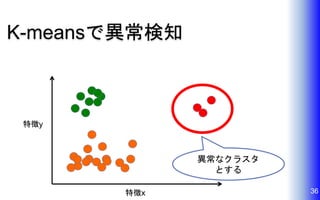
K-meansで異常検知 36特徴x 特徴y 異常なクラスタ とする
37.
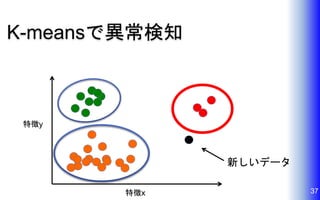
K-meansで異常検知 37特徴x 特徴y 新しいデータ
38.
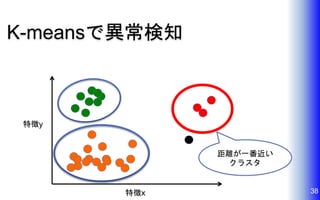
K-meansで異常検知 38特徴x 特徴y 距離が一番近い クラスタ
39.
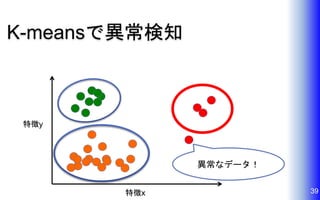
K-meansで異常検知 39特徴x 特徴y 異常なデータ!
40.
40 実際にやってみた
41.
K-meansによる攻撃検知 • K-meansによる異常検知で攻撃パケット を検知してみた。 • 使用したデータセット: kddcup99
dataset − 22種類の攻撃パケット+通常パケットのデータセット − データ数は約50万 41
42.
K-meansによる攻撃検知 1. パケットデータに前処理をかける。 2. K-meansによりクラスタリングする。 3.
精度を求める。 42
43.
学習データの前処理 • それぞれの特徴は0か1の2値であったり、 4桁以上の大きな値である場合もある。 − ポート番号やフラグの値など •
そのまま学習した場合、K-meansをかけ るときに各次元の距離尺度が異なる。 43
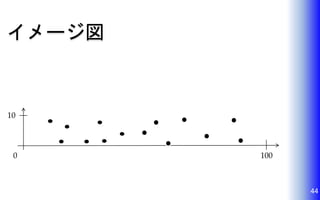
44.
イメージ図 44 10 0 100
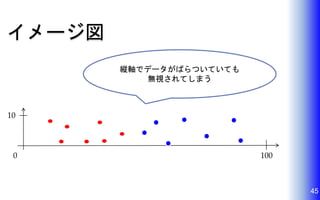
45.
イメージ図 45 10 0 100 縦軸でデータがばらついていても 無視されてしまう
46.
学習データの前処理 • 距離尺度を一定にするため、学習データ への前処理が必要不可欠。 • 正規化、Normalizing •
今回は、各特徴の偏差値を出した。 46
47.
Normalization手順① • 特徴xの平均μを以下の式で求める。 47
48.
Normalization手順② • 特徴xの標準偏差σを以下の式で求める。 48
49.
Normalization手順③ • 特徴xの各データの偏差値Tを以下の式で 求める。 49
50.
学習データの前処理 • 標準偏差が0の特徴が2つ現れた。 • すべての要素が0であったため、学習デー タから外した。 50
51.
データの学習 • Pythonにて実装。 • 前処理のコードと学習時のコードは以下 に置いてあります。 https://github.com/palloc/Clustering-samples 51
52.
学習結果 前処理を行わずにK-meansによる攻撃 パケットの検知をした結果: • Accuracy(精度) =
71.059% • False-positive(誤検知) = 6.021% • False-negative(見逃し) = 22.92% 52
53.
学習結果 前処理を行い、K-meansによる攻撃パケッ トの検知をした結果: • Accuracy(精度) =
80.295% • False-positive(誤検知) = 19.364% • False-negative(見逃し) = 0.34% 53
54.
精度について • Accuracy − 全体の精度。高いほど良い。 •
False positive − 正常なパケットを異常とする。 − 低いほど実運用しやすい。 • Flase negative − 異常な(攻撃)パケットを正常とする。 − 低くないと使い物にならない。 54
55.
学習結果 • 攻撃パケットの見逃し率が0.34%ととても 良い結果を得られた。 • だが、実運用で用いるには誤検知率が 19%とやや高く、改善したい。 55
56.
なぜ誤検知率が高いのか • K-meansは、線形分離可能な問題に対し ては強いが、線形分離不可能なものに関 してはあまり強くない。 56
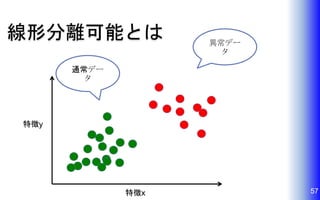
57.
線形分離可能とは 57 異常デー タ 特徴x 特徴y 通常デー タ
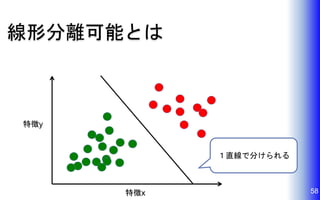
58.
線形分離可能とは 58特徴x 特徴y 1直線で分けられる
59.
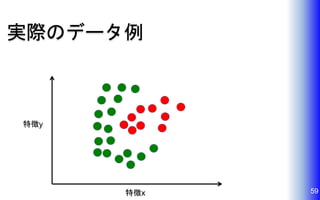
実際のデータ例 59特徴x 特徴y
60.
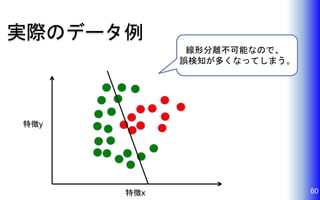
実際のデータ例 60特徴x 特徴y 線形分離不可能なので、 誤検知が多くなってしまう。
61.
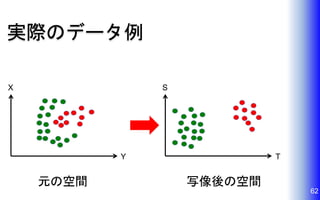
線形分離不可能なら? • 線形分離可能な空間に写像する。 • K-means以外の手法を考える。 61
62.
実際のデータ例 62 X Y S T 元の空間 写像後の空間
63.
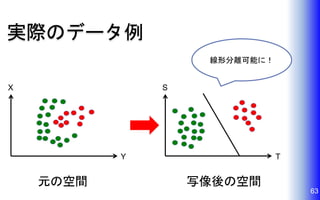
実際のデータ例 63 X Y S T 元の空間 写像後の空間 線形分離可能に!
64.
今回写像に用いる手法 • Spectral Clustering 64
65.
Spectral Clustering • トポロジ的アプローチを取るクラスタ リング手法。 •
今回は最もベースとなるアルゴリズム のみを紹介。 ※数学要素が強いので、意味については省略 65
66.
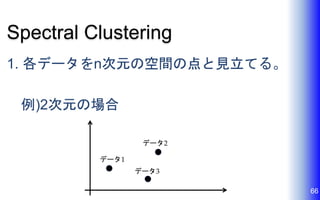
Spectral Clustering 1. 各データをn次元の空間の点と見立てる。 例)2次元の場合 66 データ1 データ2 データ3
67.
Spectral Clustering 2. 各データのユークリッド距離を行列W とする。 67
68.
Spectral Clustering 3. Wの行ごとの和を求め、対角成分にした 行列(他の要素は0)をDとする。 68
69.
Spectral Clustering 4. graph-Laplacianと呼ばれる行列Lを、 以下のように求める。 69
70.
Spectral Clustering 5. Lの固有ベクトルViをクラスタ数mだけ 求める。(固有ベクトルの求め方は省略) 70 …
71.
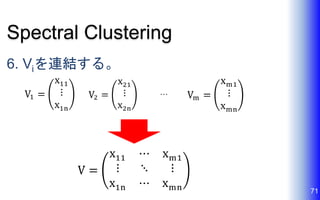
Spectral Clustering 6. Viを連結する。 71 …
72.
Spectral Clustering 7. 行ごとに一つのデータの特徴とみなし、 クラスタリングを行う。 72 これがデータ1 の特徴
73.
Spectral Clustering • 特徴として、次元数がクラスタ数mに圧縮 されていることが分かる。 •
精度あがりそうじゃない? 73
74.
線形分離不可能なら? • 線形分離可能な空間に写像する。 • クラスタリング以外の手法を考える。 74
75.
クラスタリング以外の手法 ディープラーニング流行ってるし ディープラーニングやろうぜ! by某友人 75
76.
Deep learningの検討 • 日本語では深層学習。 •
「ニューラルネットワーク」と呼ばれる 人間の脳の仕組みをコンピュータで再現 するモデルを用いた機械学習のこと。 76
77.
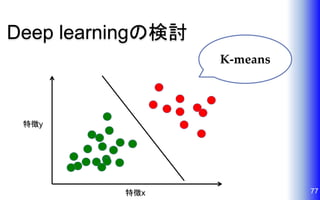
Deep learningの検討 77特徴x 特徴y K-means
78.
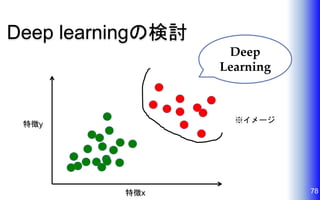
Deep learningの検討 78特徴x 特徴y Deep Learning ※イメージ
79.
Deep learningの検討 • 時間がないので詳しいアルゴリズムの 説明は省略。 •
Pythonによる深層学習入門記事を書いて いるので参考にしてください。 http://palloc.hateblo.jp/entry/2016/08/02/213847 79
80.
Deep learningの検討 • 異常検知に用いる際の懸念点 −
精度がでても、処理がブラックボックスなため結果 の意味を持たせることが難しい。 − 環境ごとに最適なモデルを作るのにとても時間が掛 かるため、ハードルが高め。 − 過学習などが懸念される 80
81.
他の手法 • サポートベクターマシン • 近傍法 •
などなど多数… 81
82.
まとめ • K-meansで割と実用的な精度が出た。 • Spectral
Clusteringを用いると別空間へ 写像するのでさらに精度が上がりそう。 • Deep learningを使うには越えるべき壁が いくつかある。 • 他にもたくさん異常検知手法がある。 82
83.
参考文献(面白いです) • A Tutorial
on Spectral Clustering http://www.cs.cmu.edu/~aarti/Class/10701/readings/Luxburg06_TR.pdf • Anomary Detection in Deep Learning http://www.slideshare.net/agibsonccc/anomaly-detection-in-deep-learning- 62473913 83
Editor's Notes
#37
本当はLabel スプレッディングなどの手法がありますがとりあえず決め打ちということで
Download










































































![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)















![[R勉強会][データマイニング] R言語による時系列分析](https://cdn.slidesharecdn.com/ss_thumbnails/r-100423232629-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)































