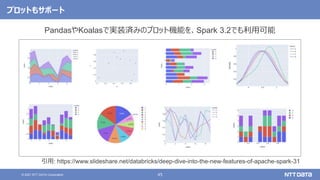
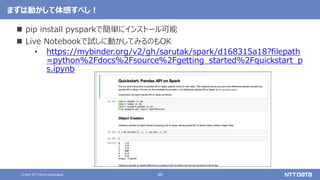
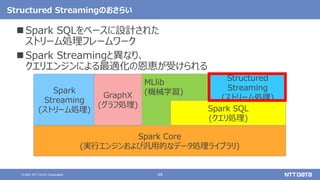
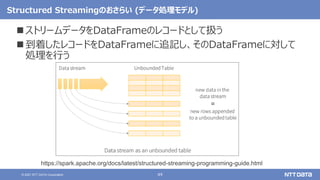
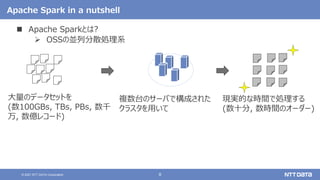
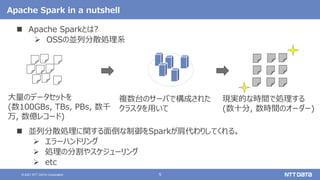
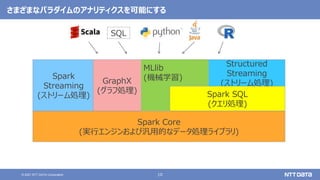
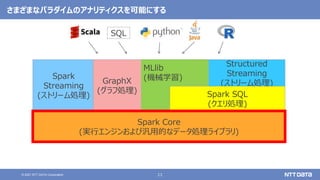
Apache Sparkの基本と最新バージョン3.2のアップデート (Open Source Conference 2021 Online/Fukuoka 発表資料) 2021年11月20日(土) NTTデータ 技術開発本部 猿田 浩輔























![43
© 2021 NTT DATA Corporation
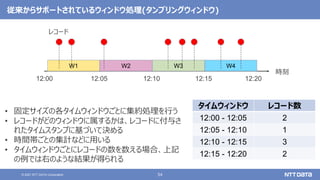
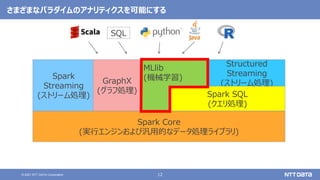
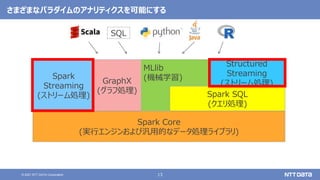
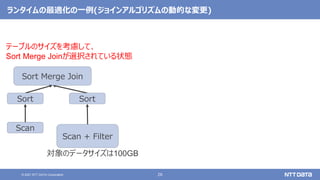
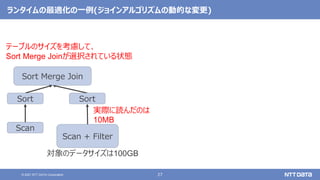
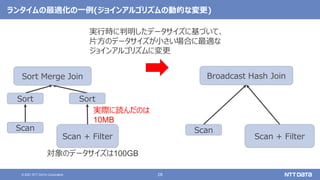
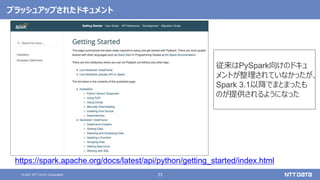
pandas API on Sparkを用いたSparkアプリケーション記述例
import pandas as pd
df = pd.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
import databricks.koalas as ks
df = ks.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
Pandas Koalas](https://image.slidesharecdn.com/oscfukuoka2021-211125022955/85/Apache-Spark-3-2-Open-Source-Conference-2021-Online-Fukuoka-43-320.jpg)
![44
© 2021 NTT DATA Corporation
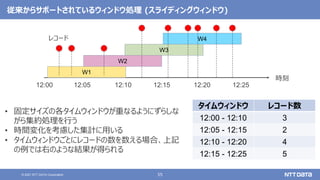
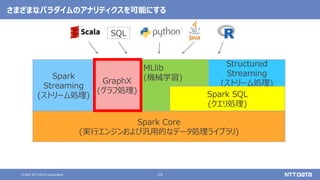
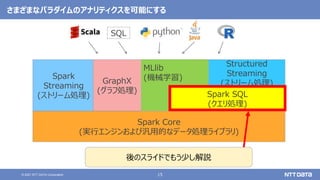
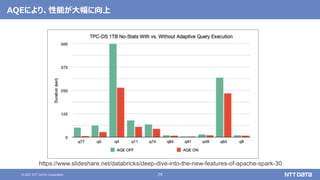
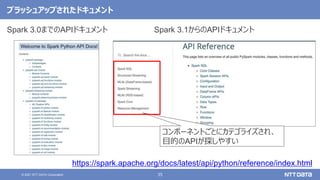
pandas API on Sparkを用いたSparkアプリケーション記述例
import pandas as pd
df = pd.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
import databricks.koalas as ks
df = ks.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
import pyspark.pandas as ps
df = ps.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
Pandas Koalas
pandas API on Spark(Spark 3.2)](https://image.slidesharecdn.com/oscfukuoka2021-211125022955/85/Apache-Spark-3-2-Open-Source-Conference-2021-Online-Fukuoka-44-320.jpg)