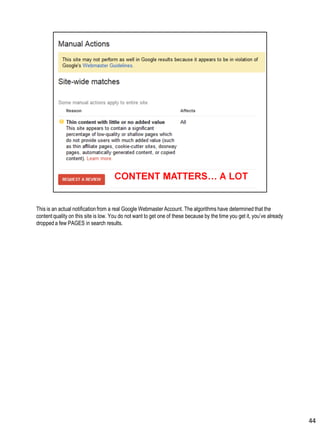
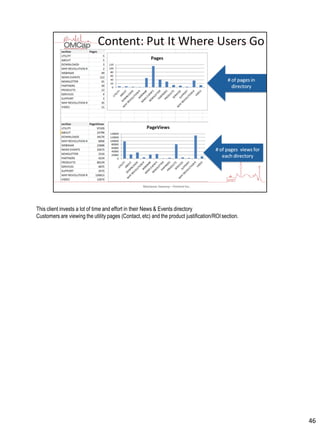
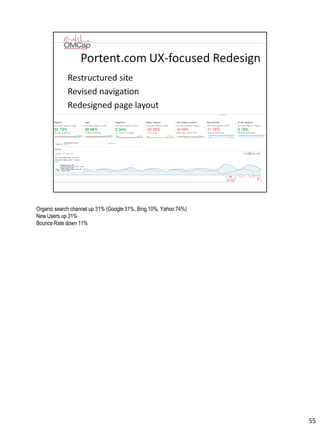
Download to read offline





![7
A spider returns information about each word on each page it crawls.
This information is stored in the index where it is compressed based on grammatical requirements such as
stemming[taking the word down to its most basic root] and stop words [common articles and others stipulated by
the company]. A complete copy of the Web page may be stored in the search engine’s cache.
This index is then inverted so that lookup is done on the basis of record contents and not the document ID.
With brute force calculation, the system pulls each record from the inverted index [mappingof words to where they
appear in document text]. This is recall or all documents in the corpus with text instances that match your the
term(s).
The “secret sauces” for each search engine are algorithms that sort order the recall results in a meaningfulfashion.
This is precision or the number of documents from recall that are relevant to your query term(s).
All search engines use a common set of values to refine precision. If the search term used in the title of the
document, in heading text, formattedin any way, or used in link text, the document is considered to be more
relevant to the query. If the query term(s) are used frequently throughout the document, the document is considered
to be more relevant.
An example the complexity involved in refinement of results is Term Frequency - Inverse Document Frequency [TF-
IDF] weighting. Here the raw term frequency (TF) of a term in a document by the term's inverse document
frequency (IDF) weight [frequency of occurrence in a particular document multipliedthe number of documents
containingthe term divided by the number of documents in the entire corpus. [caveat emptor: high-level, low-level,
level-playing-fieldmath are not my strong suits].](https://image.slidesharecdn.com/sweeny-ux-seoomcap2014v3-150201165749-conversion-gate01/85/Sweeny-ux-seo-om-cap-2014_v3-7-320.jpg)







![Quality of links more important than quantity of links
Segmentationof corpus into broad topics
Selectionof authority sources within these topic areas
Hilltopwas one of the first to introduce the concept of machine-mediated“authority” to combat the human
manipulationof results for commercial gain (using link blast services, viral distribution of misleading links. It is used
by all of the search engines in some way, shape or form.
Hilltopis:
Performed on a small subset of the corpus that best represents nature of the whole
Authorities: have lots of unaffiliatedexpert document on the same subject pointing to them
Pages are ranked according to the number of non-affiliated“experts” point to it – i.e. not in the same site or
directory
Affiliationis transitive [if A=B and B=C then A=C]
The beauty of Hilltop is that unlike PageRank, it is query-specific and reinforces the relationship between the
authority and the user’s query. You don’t have to be big or have a thousand links from auto parts sites to be an
“authority.” Google’s 2003 Florida update, rumored to contain Hilltop reasoning, resulted in a lot of sites with
extraneous links fall from their previously lofty placements as a result.
Photo: Hilltop Hohenzollern Castle in Stuttgart](https://image.slidesharecdn.com/sweeny-ux-seoomcap2014v3-150201165749-conversion-gate01/85/Sweeny-ux-seo-om-cap-2014_v3-17-320.jpg)
![Consolidationof Hypertext Induced Topic Selection [HITS] and PageRank
Pre-query calculation of factors based on subset of corpus
Context of term use in document
Context of term use in history of queries
Context of term use by user submittingquery
ComputesPR based on a set of representationaltopics [augmentsPR with content analysis]
Topic derived from the Open Source directory
Uses a set of ranking vectors: Pre-query selection of topics + at-query comparison of the similarity of query to topics
Creator now a Senior Engineer at Google
18](https://image.slidesharecdn.com/sweeny-ux-seoomcap2014v3-150201165749-conversion-gate01/85/Sweeny-ux-seo-om-cap-2014_v3-18-320.jpg)

































The document discusses the evolution of search engines and the mechanisms behind information retrieval, emphasizing the significance of text over imagery in user preferences. It outlines the processes of indexing, recall, and precision, along with the importance of personalization and user input in refining search results. Additionally, the text covers user behavior, algorithm updates, and the necessity of quality content for effective search engine optimization.




























































