Downloaded 22 times







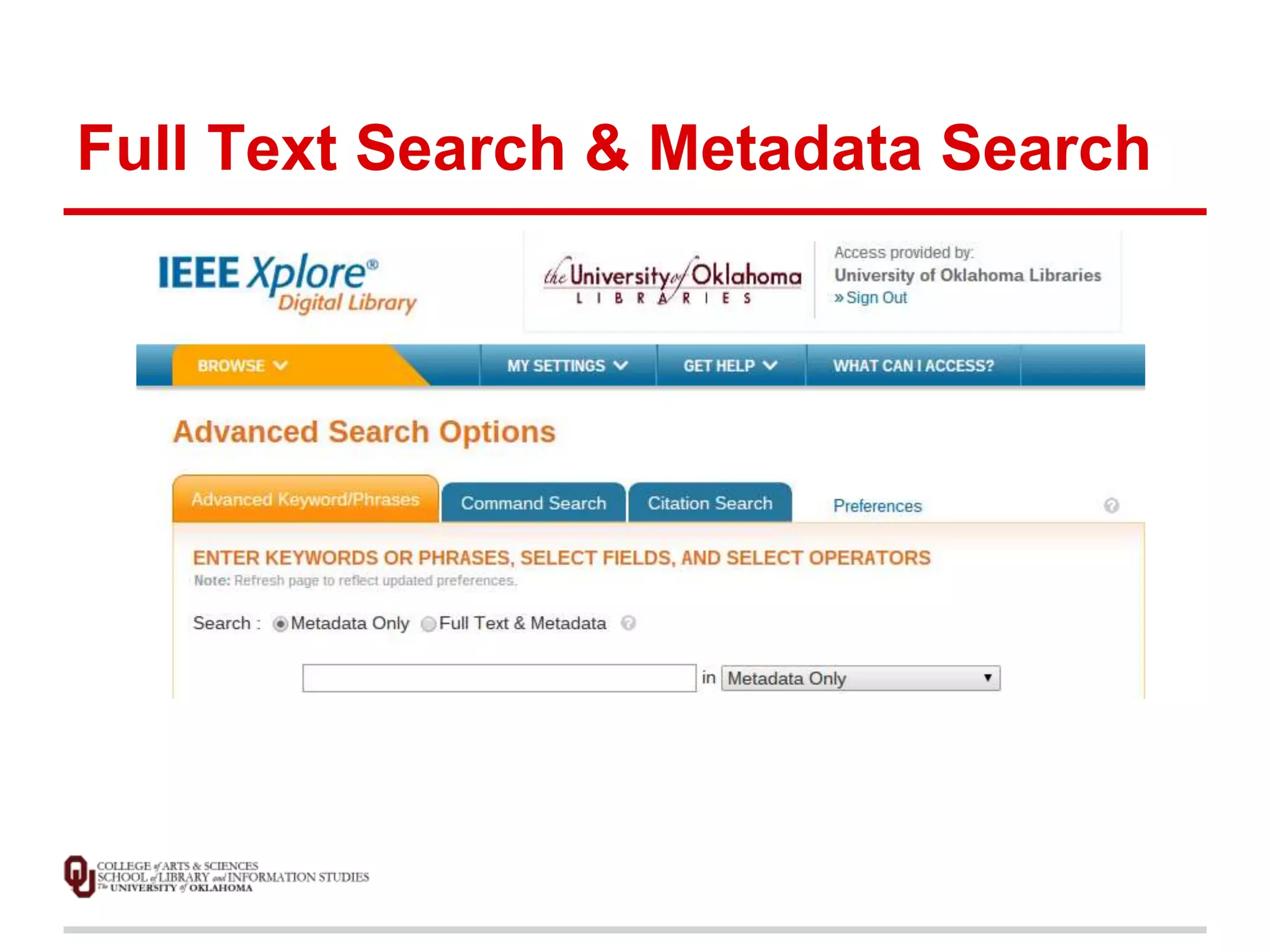




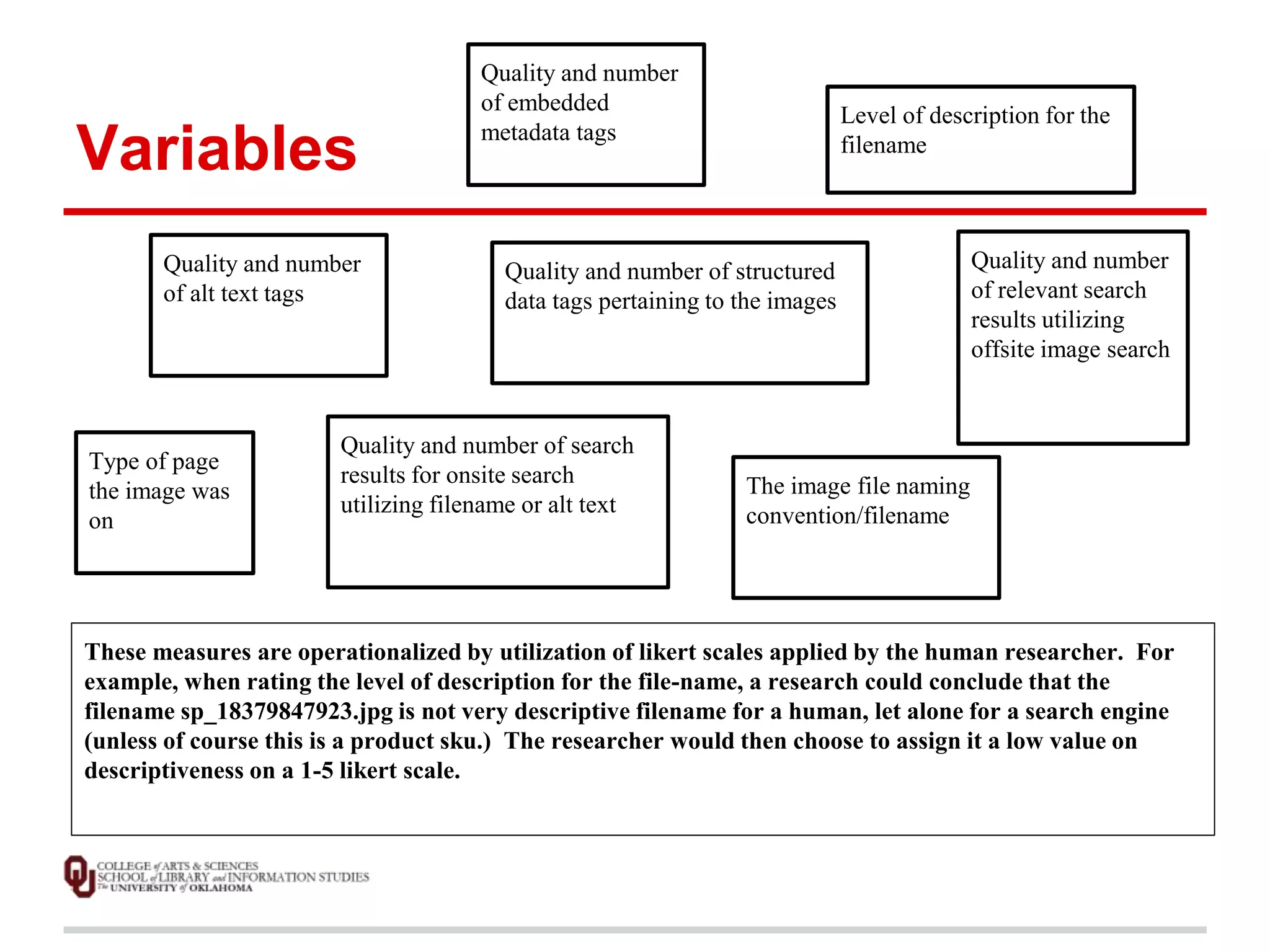


![Data Analysis Methods
● Descriptive Statistics
o Bell Curve - measures
towards a central tendency
using likert scale data
Bell Curve Image By Vierge Marie
(Own work) [Public domain], via
Wikimedia Commons
http://upload.wikimedia.org/wikipe
dia/commons/f/f6/Gaussian_Filter
.svg](https://image.slidesharecdn.com/structureddataandmetadataevaluationmethodologyfororganizationslookingtoimproveimagefindabilityonthew-141127101544-conversion-gate01/75/Structured-data-and-metadata-evaluation-methodology-for-organizations-looking-to-improve-image-findability-on-the-web-emily-kolvitz_2014-16-2048.jpg)










This research proposal outlines a methodology for evaluating an organization's use of structured data and metadata to improve the findability of images on the web. The methodology involves assessing an organization's file naming conventions, use of alt text, embedded metadata, schema.org markup and more. It also involves analyzing search engine results and structured data validation tools. The goal is to establish a baseline of an organization's current practices and identify areas for improvement to maintain online relevancy. The expected outcomes include a benchmark for an organization's structured data maturity and a roadmap for improving image findability on and off their website.























































![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)




