Download as PDF, PPTX


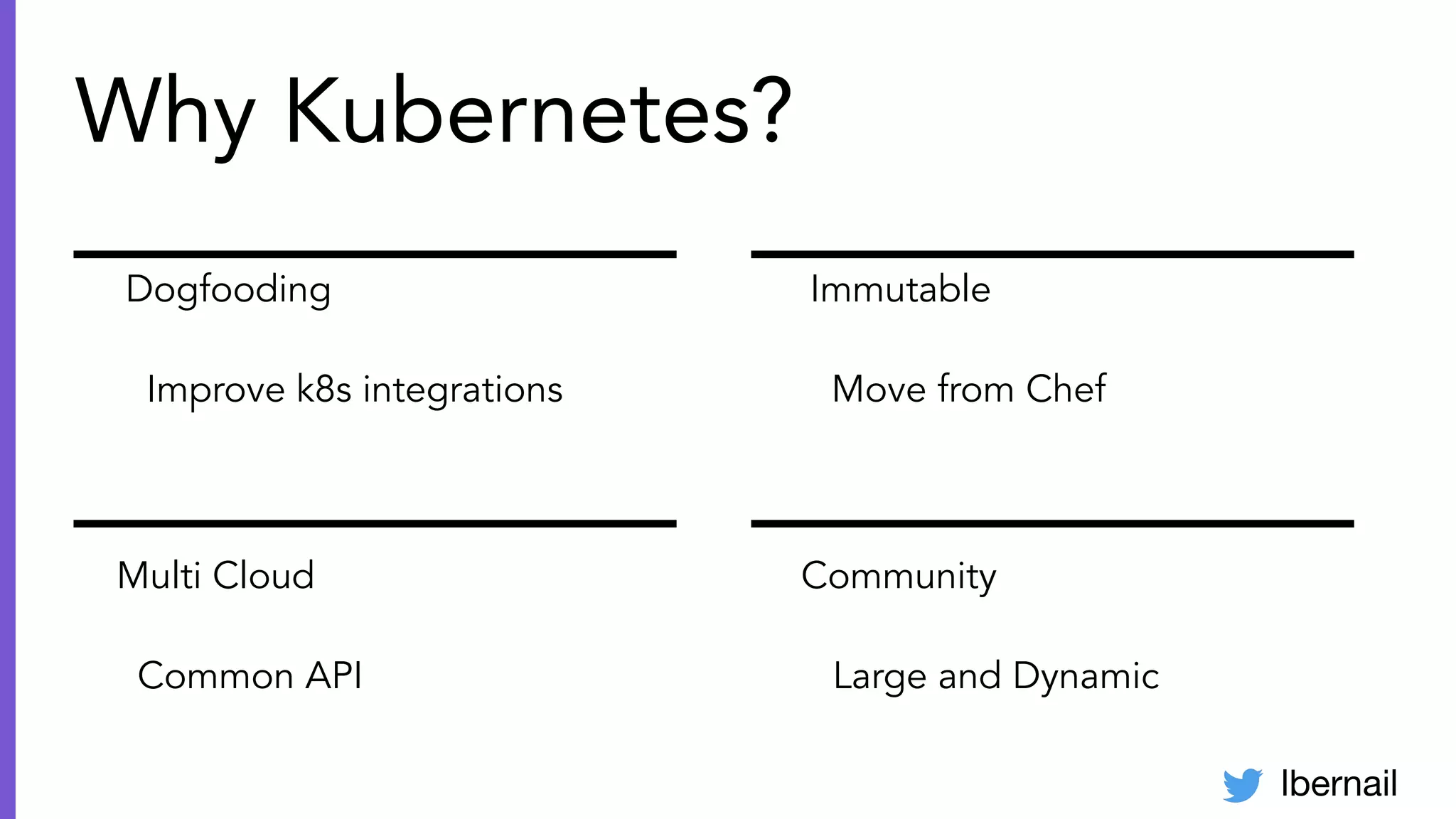






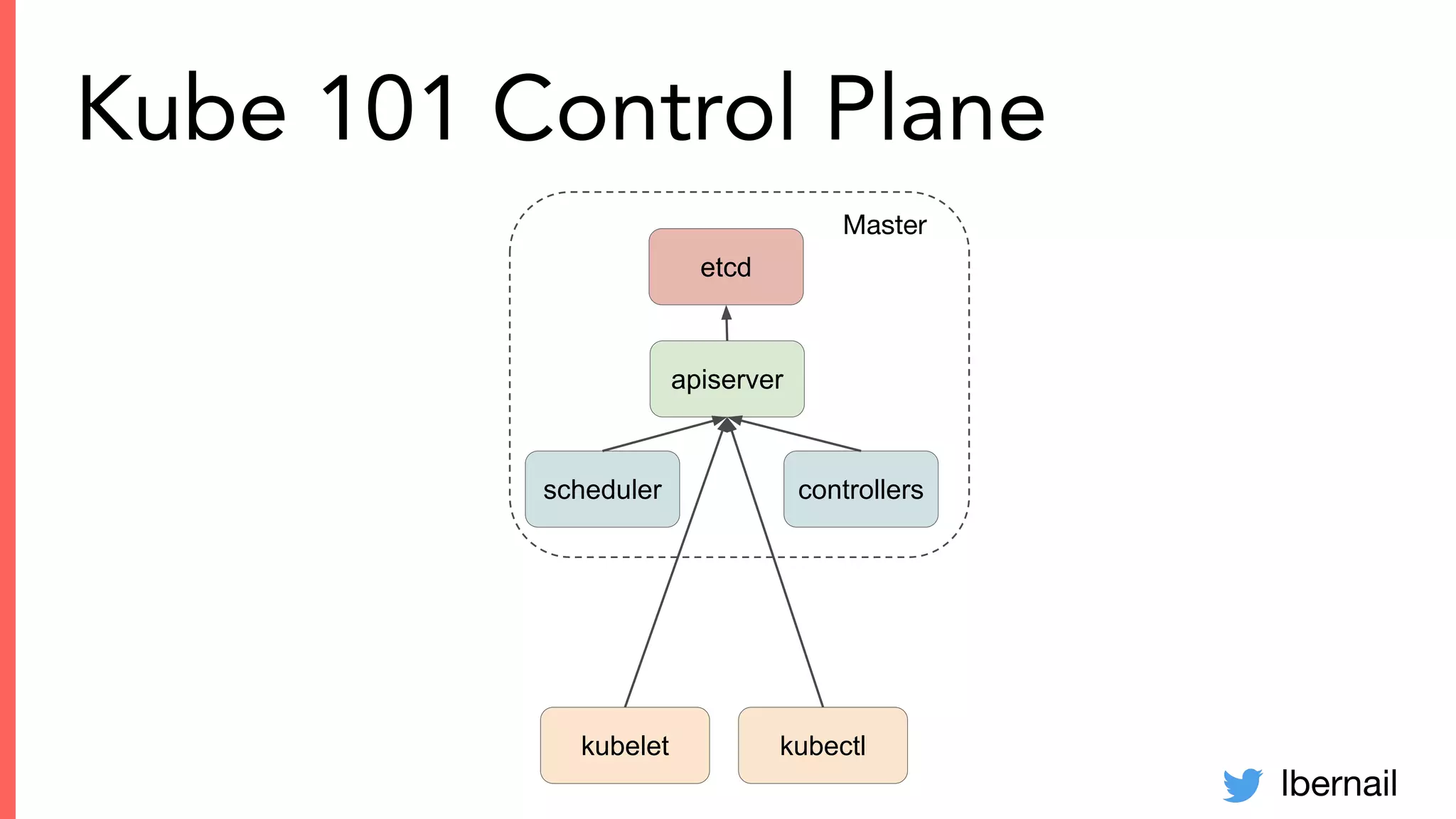
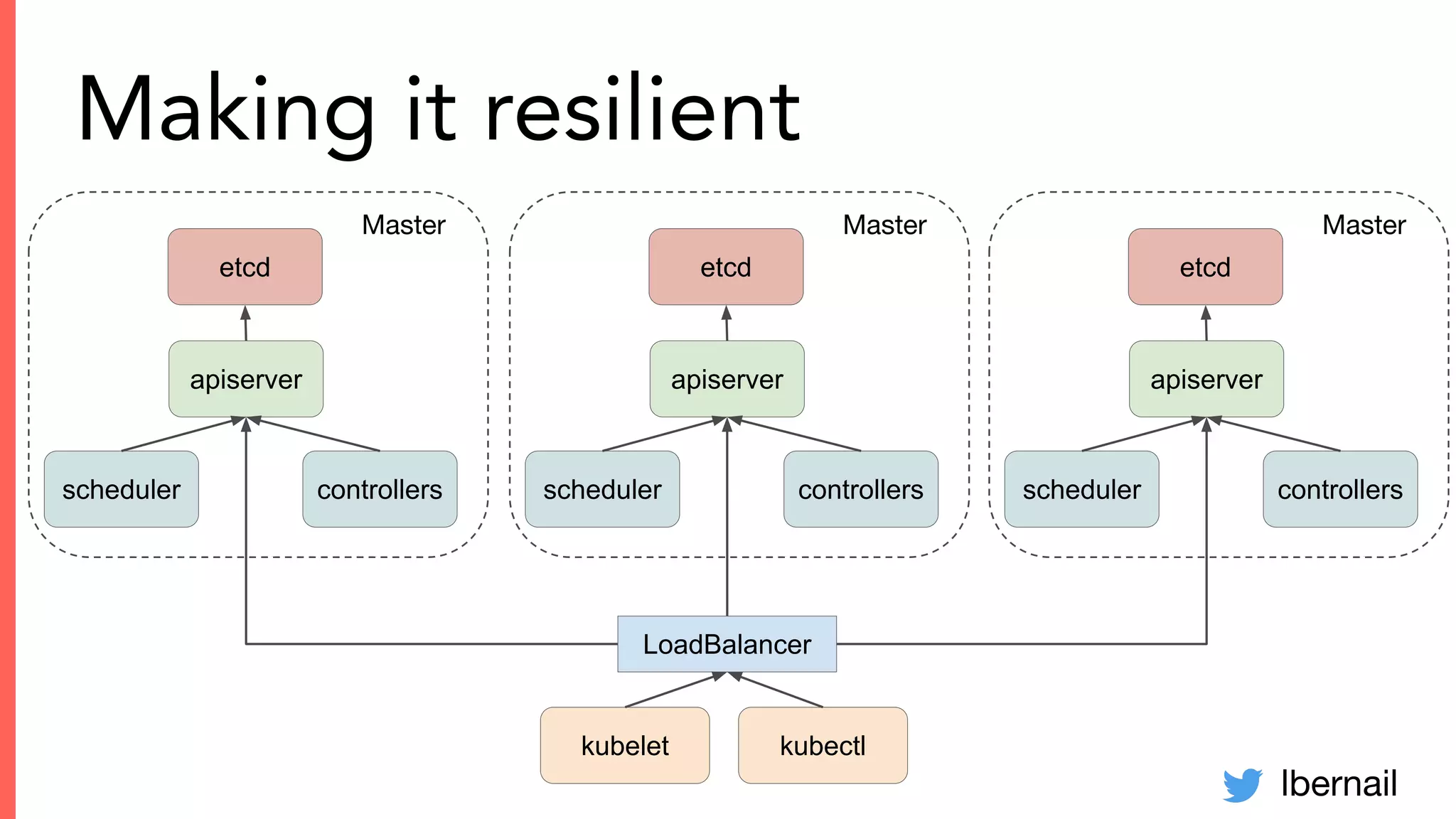
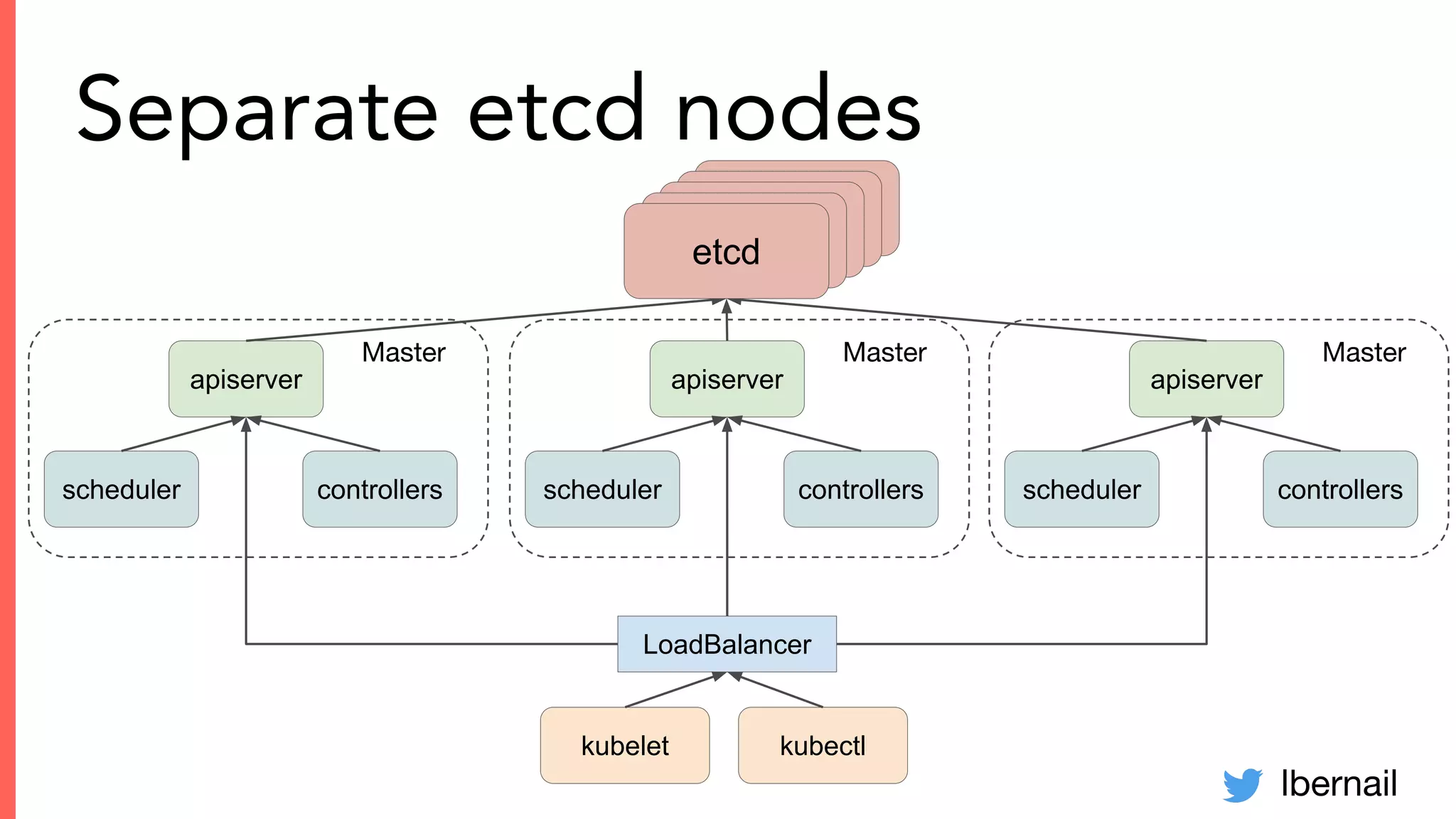
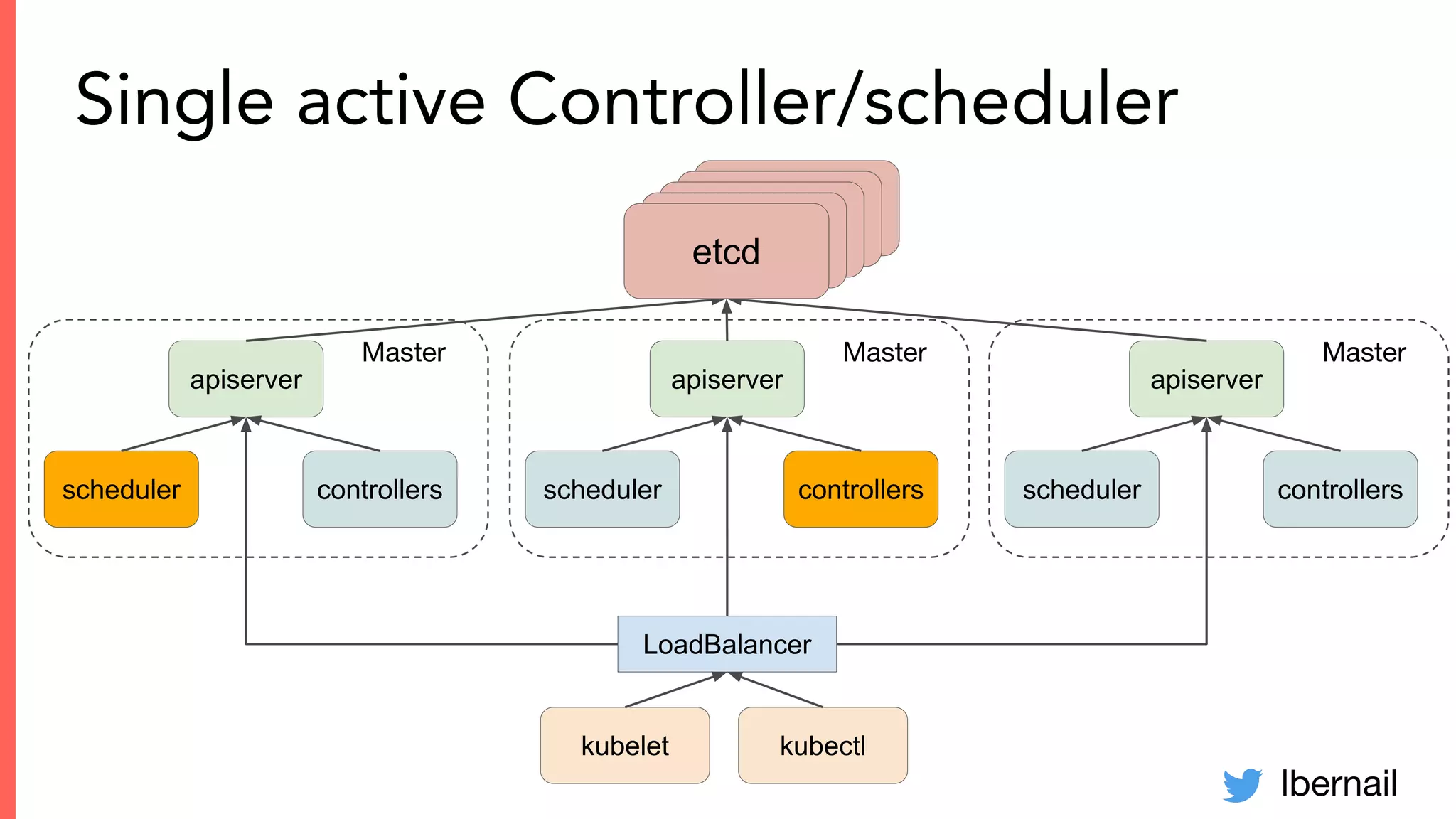
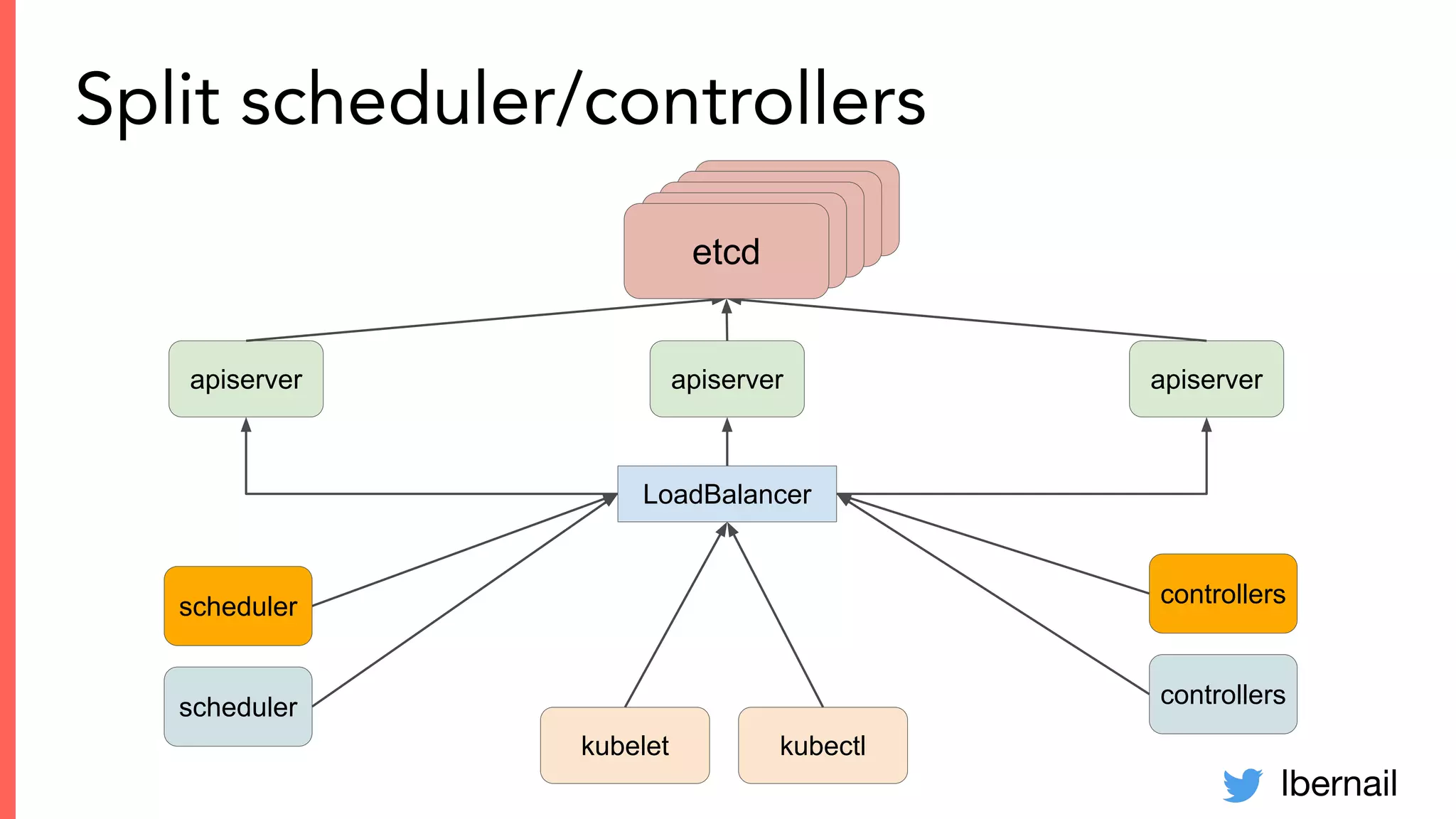





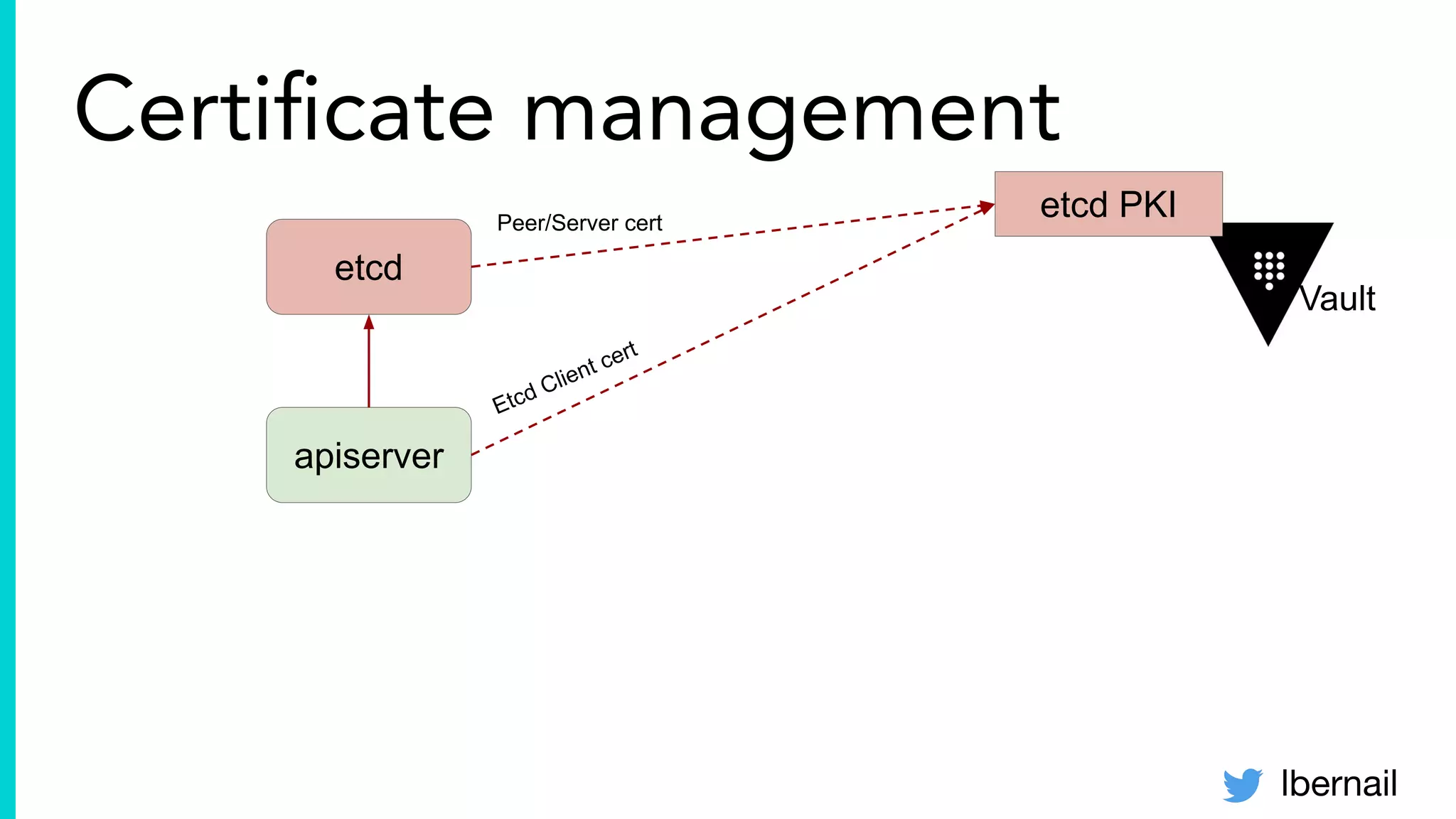
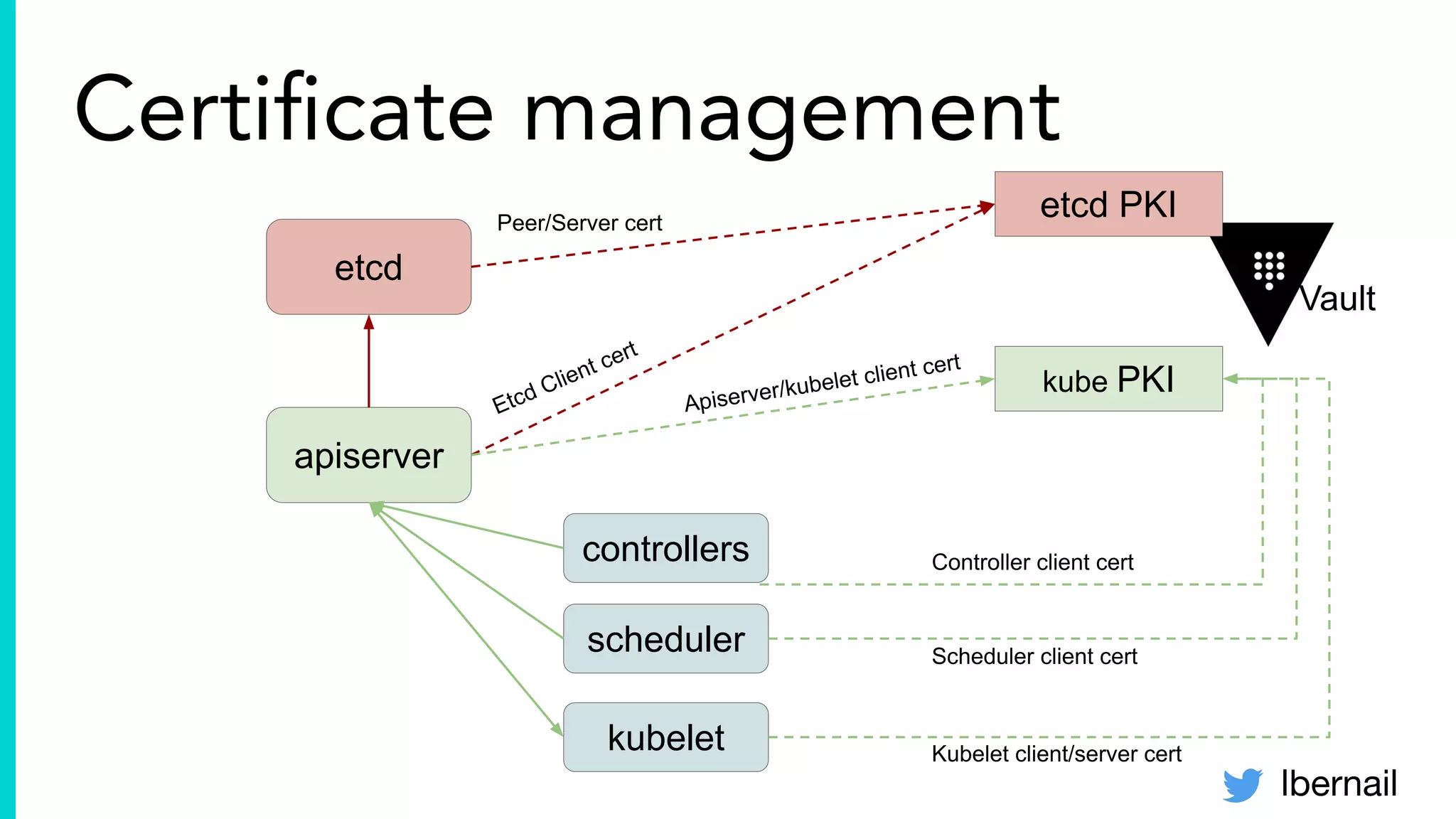
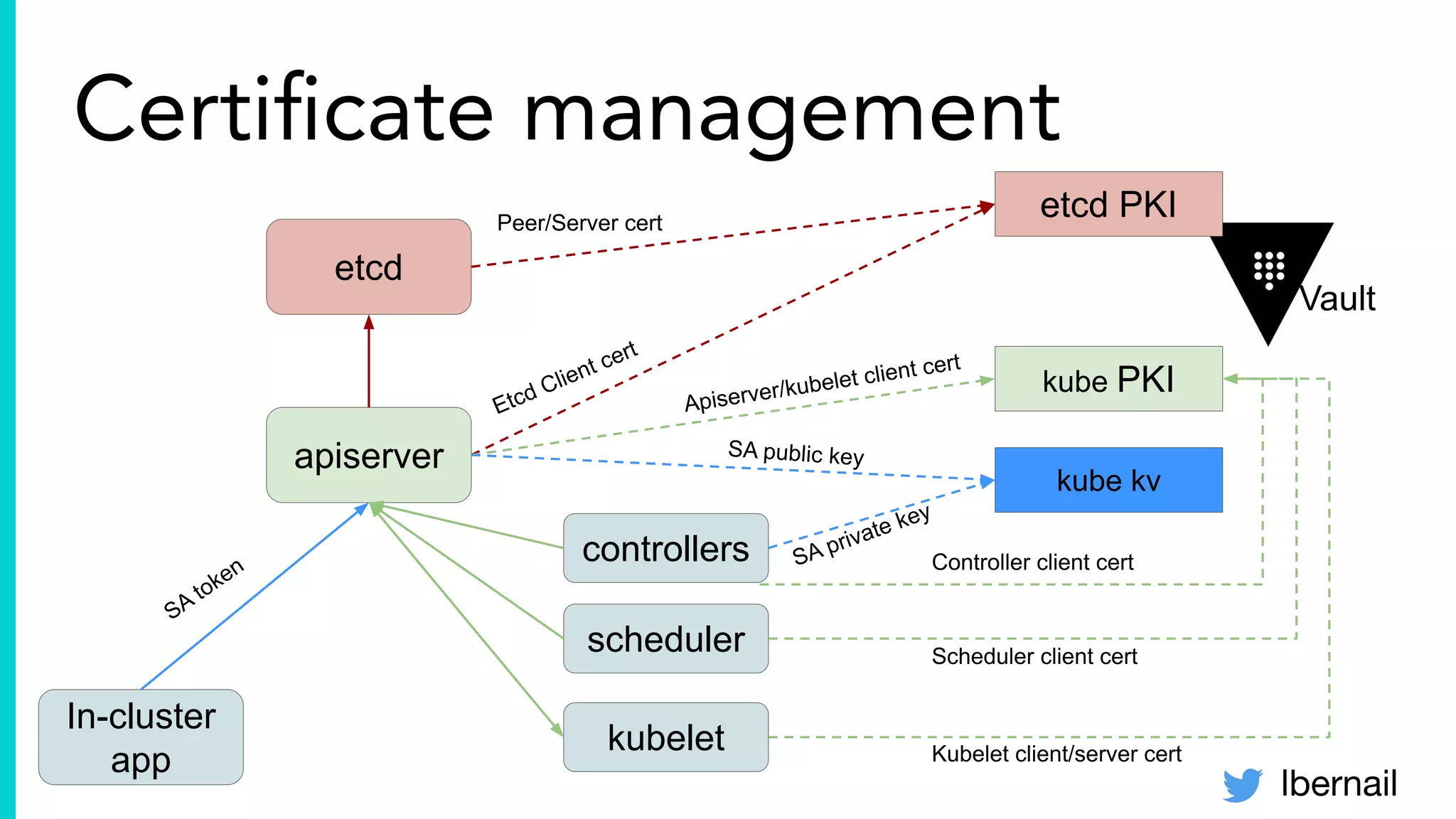
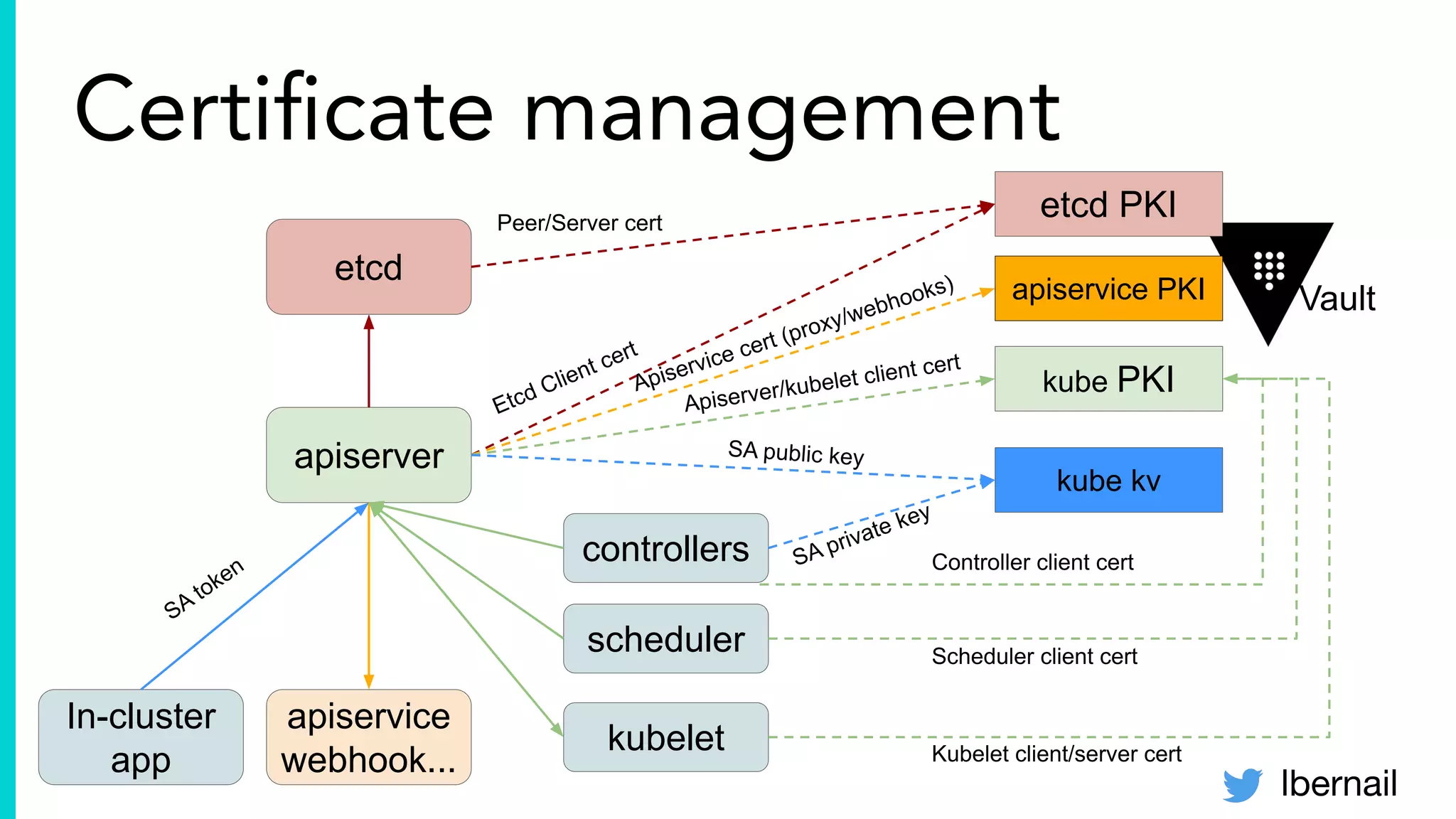
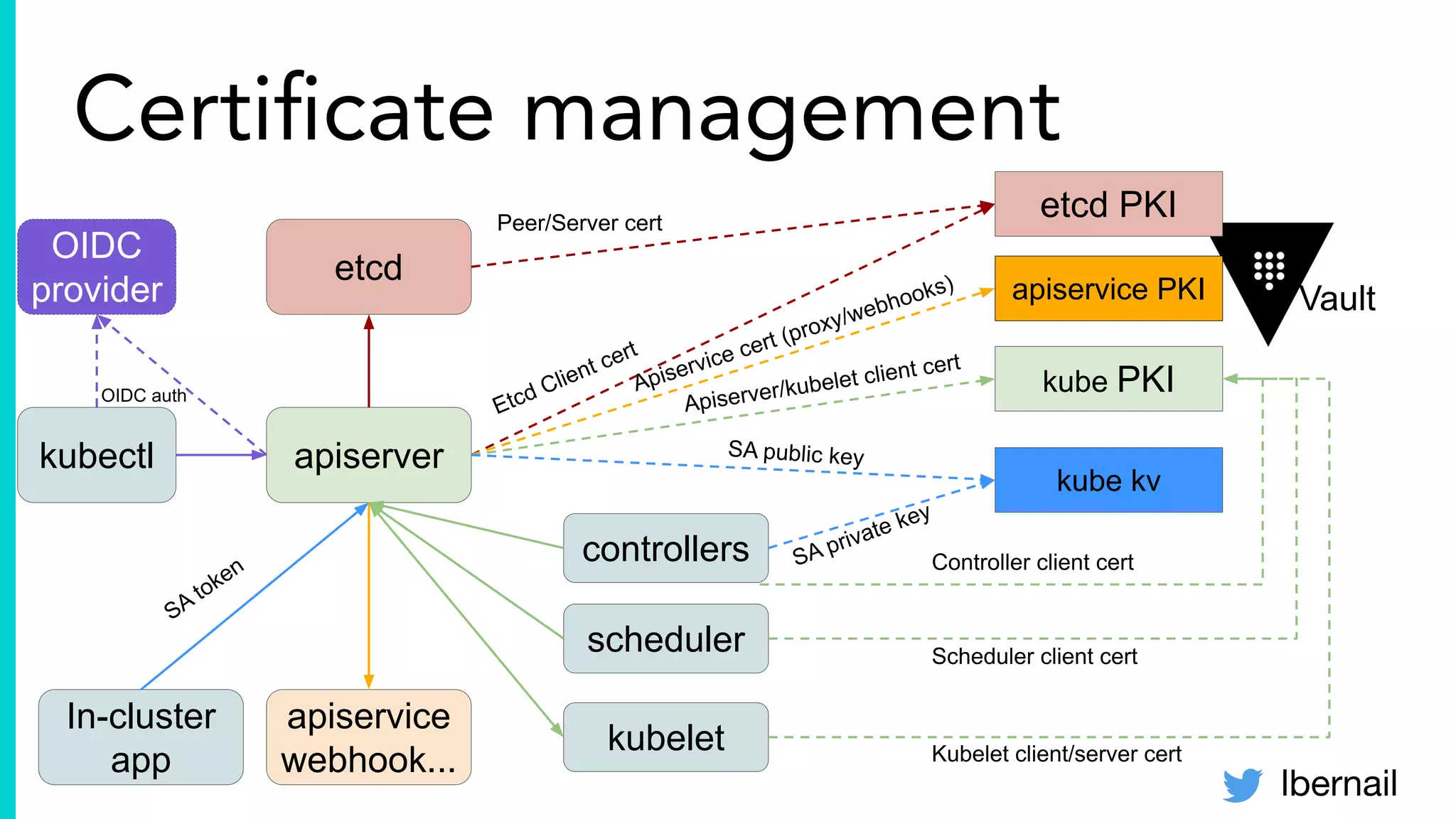

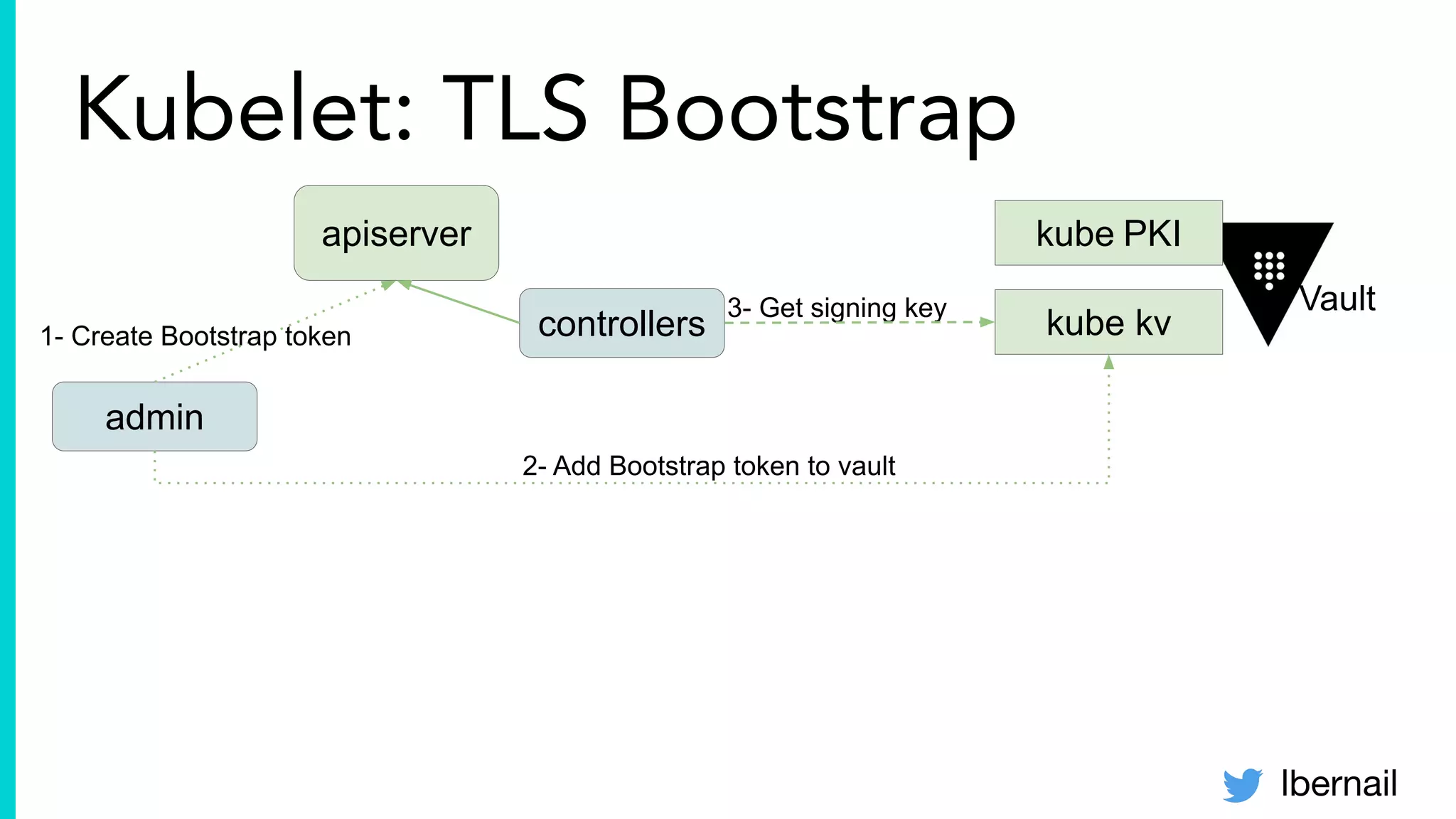
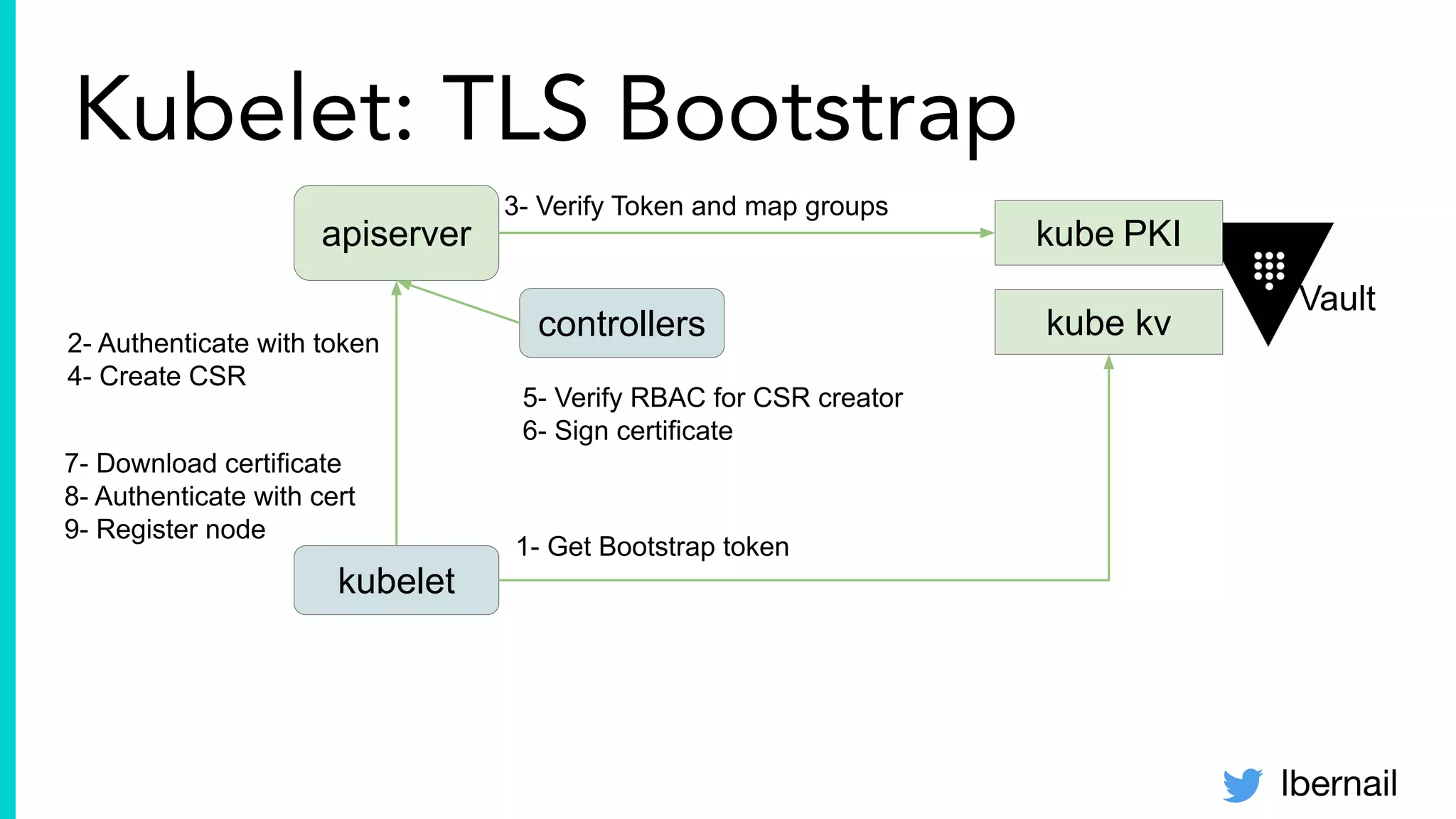
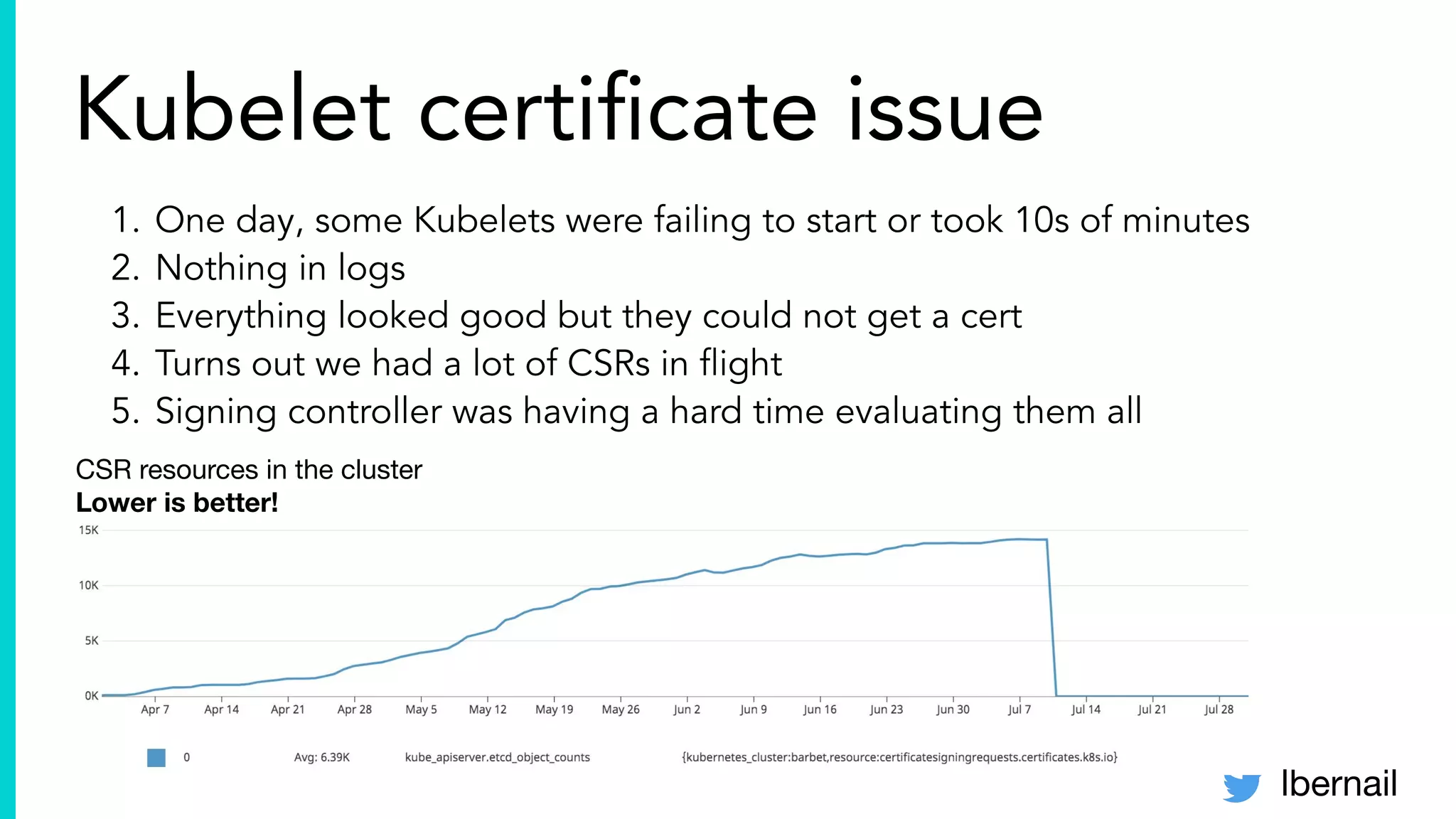


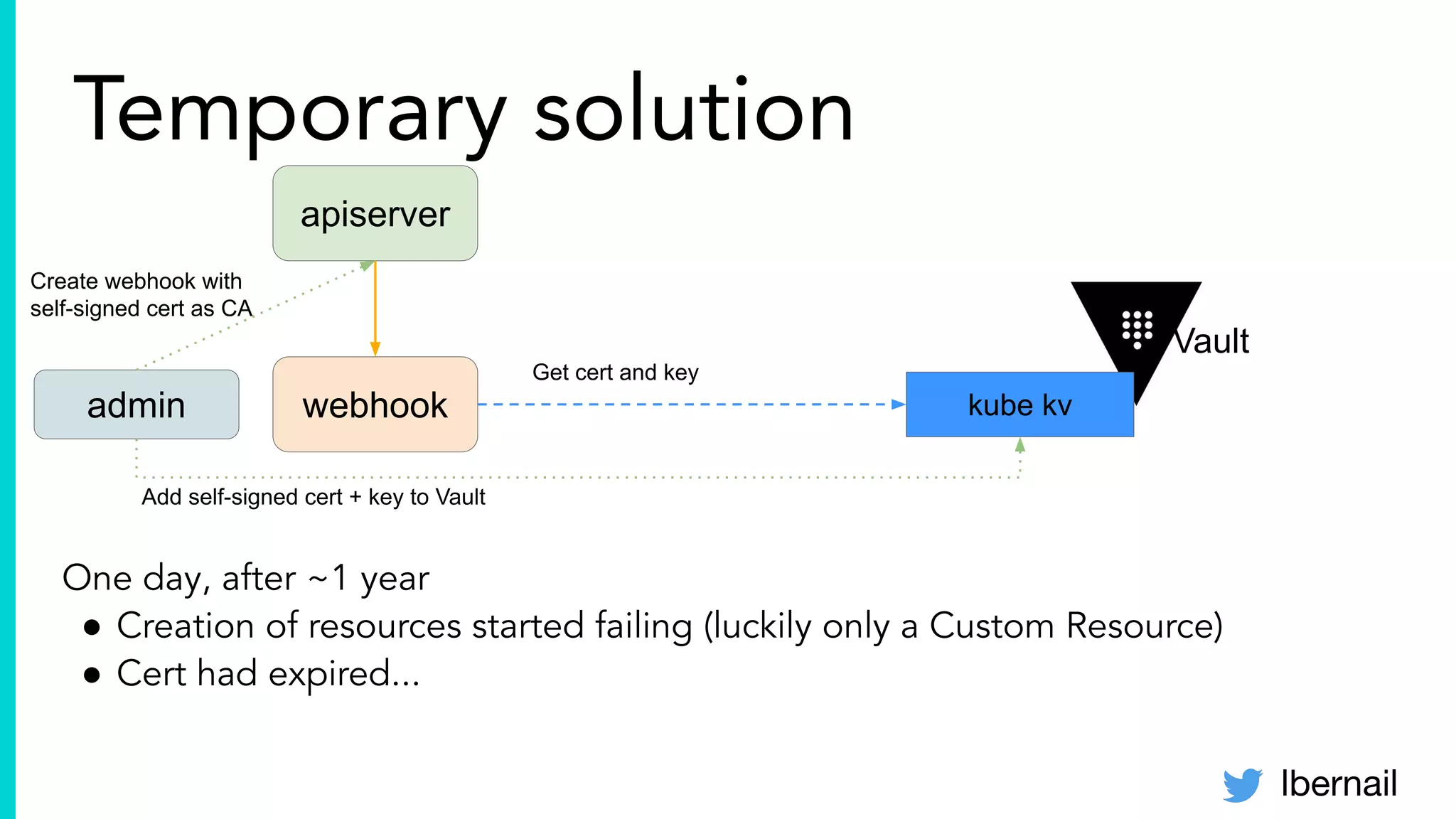



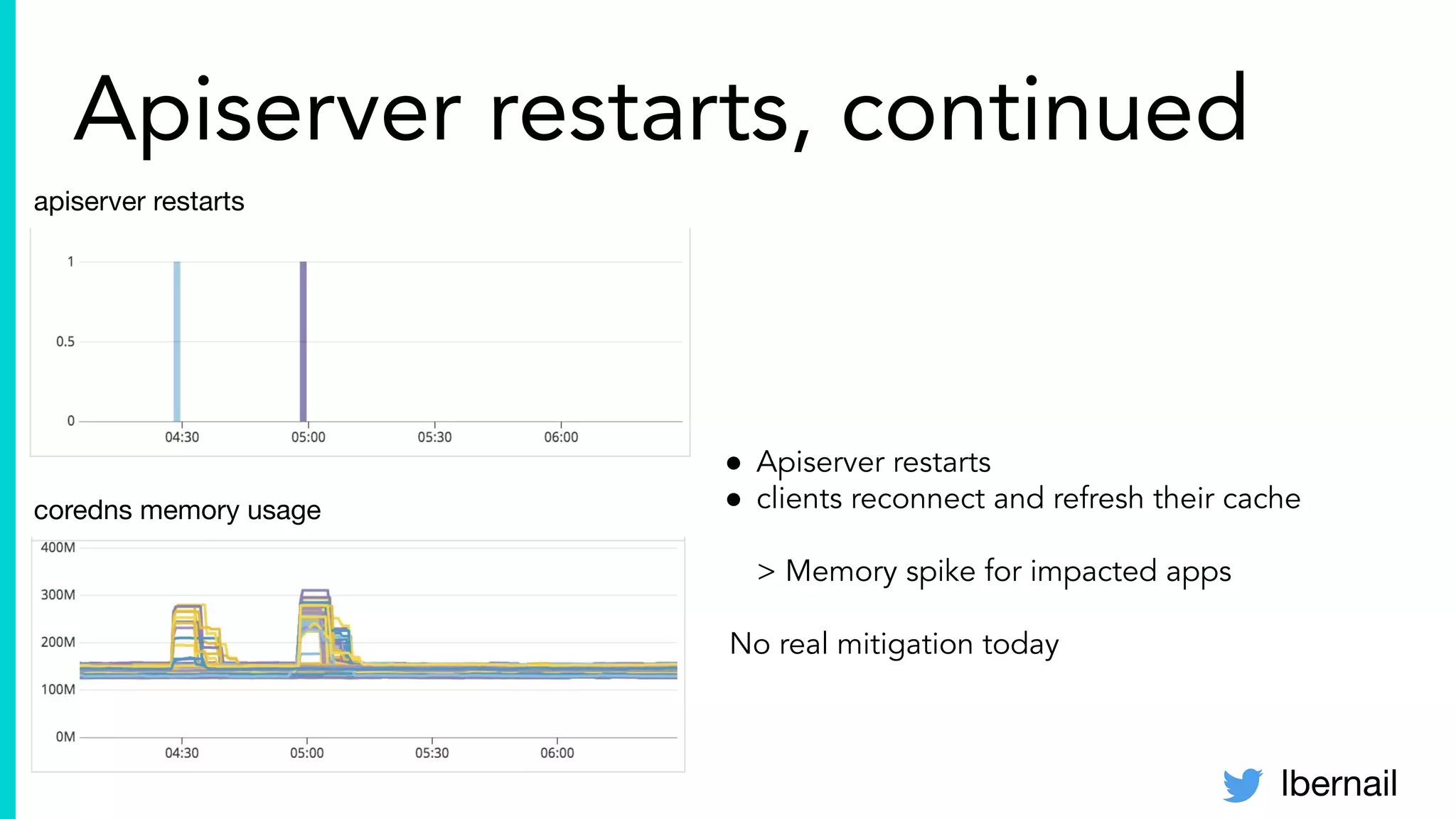
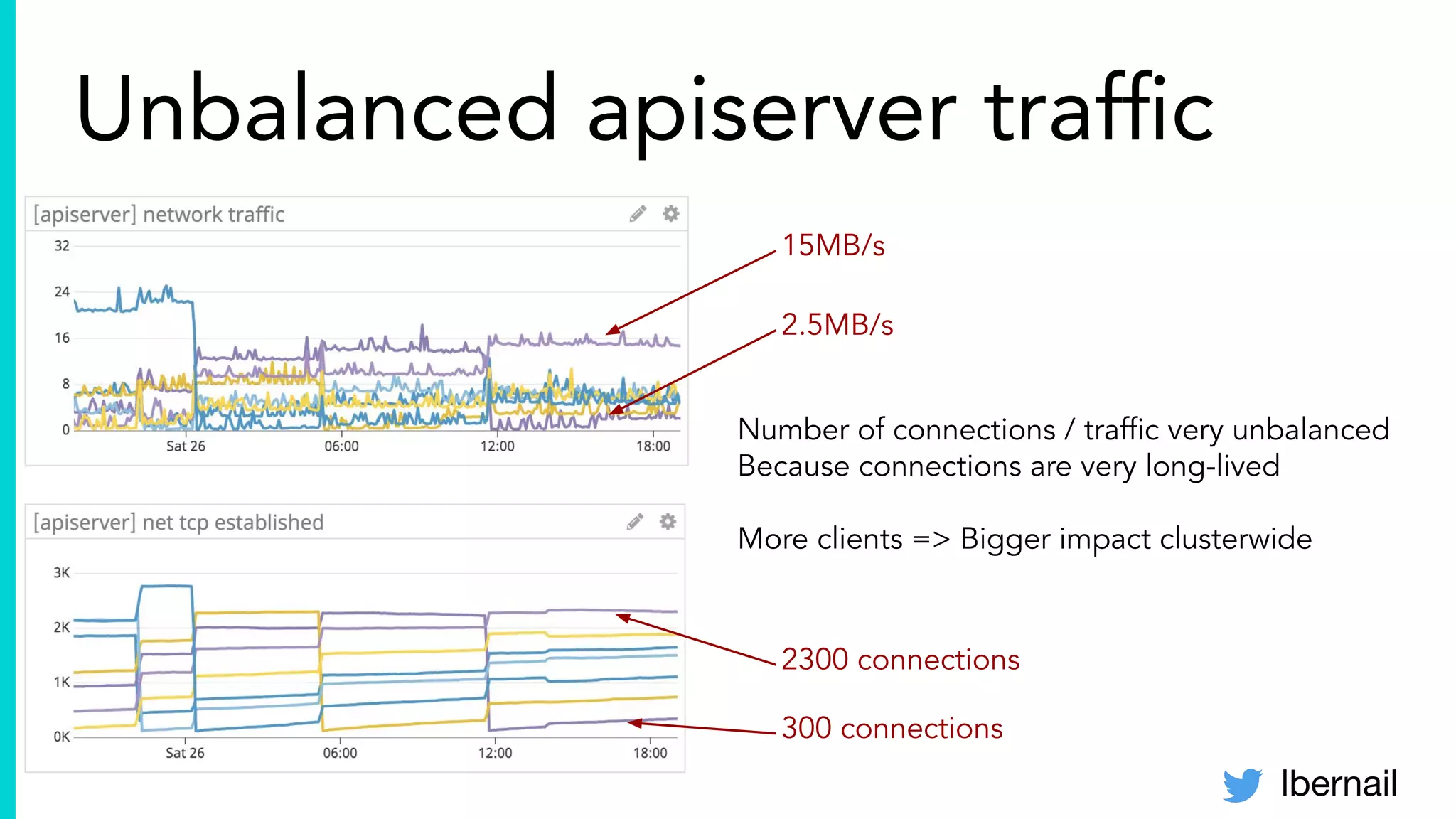



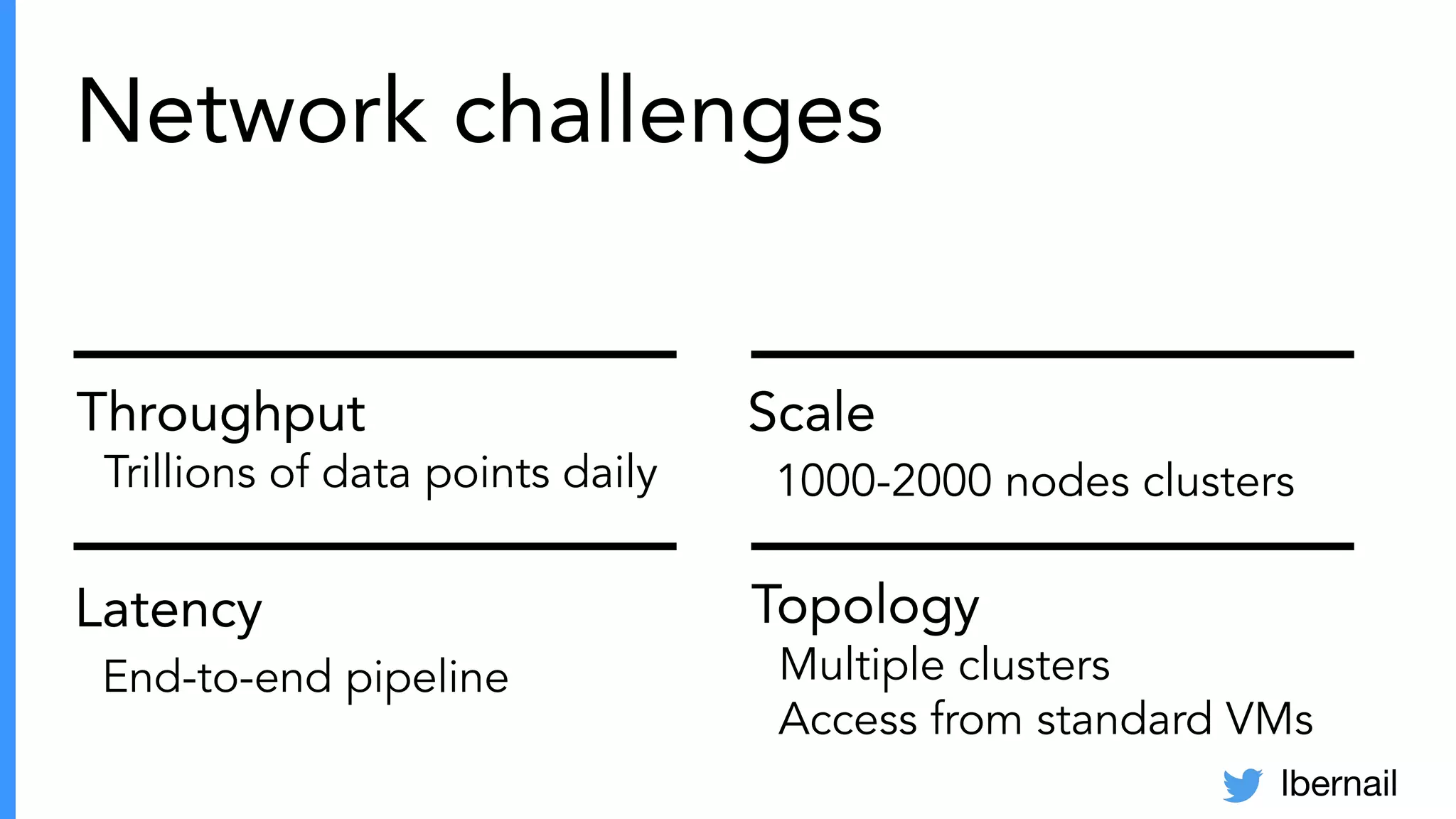





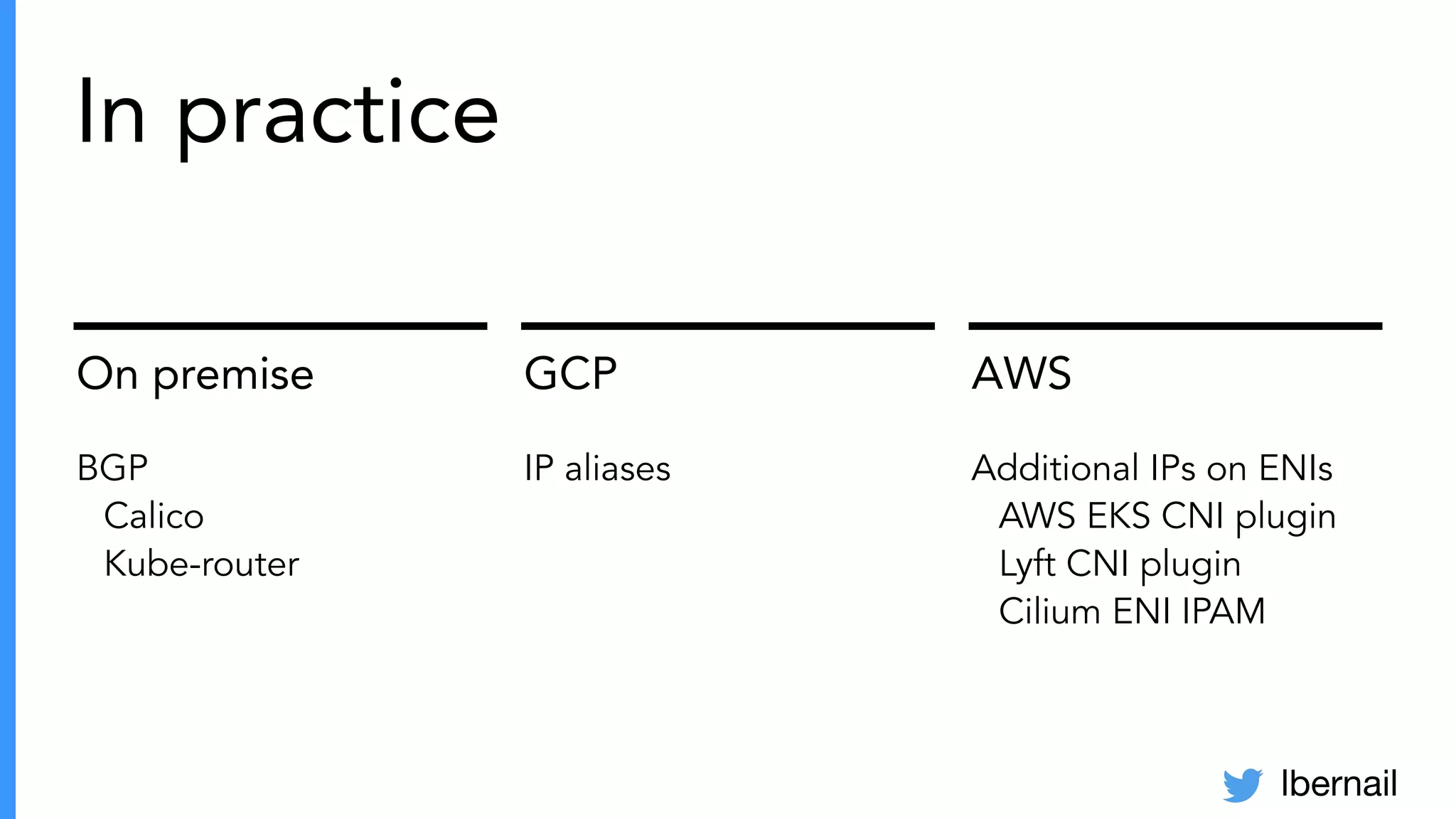
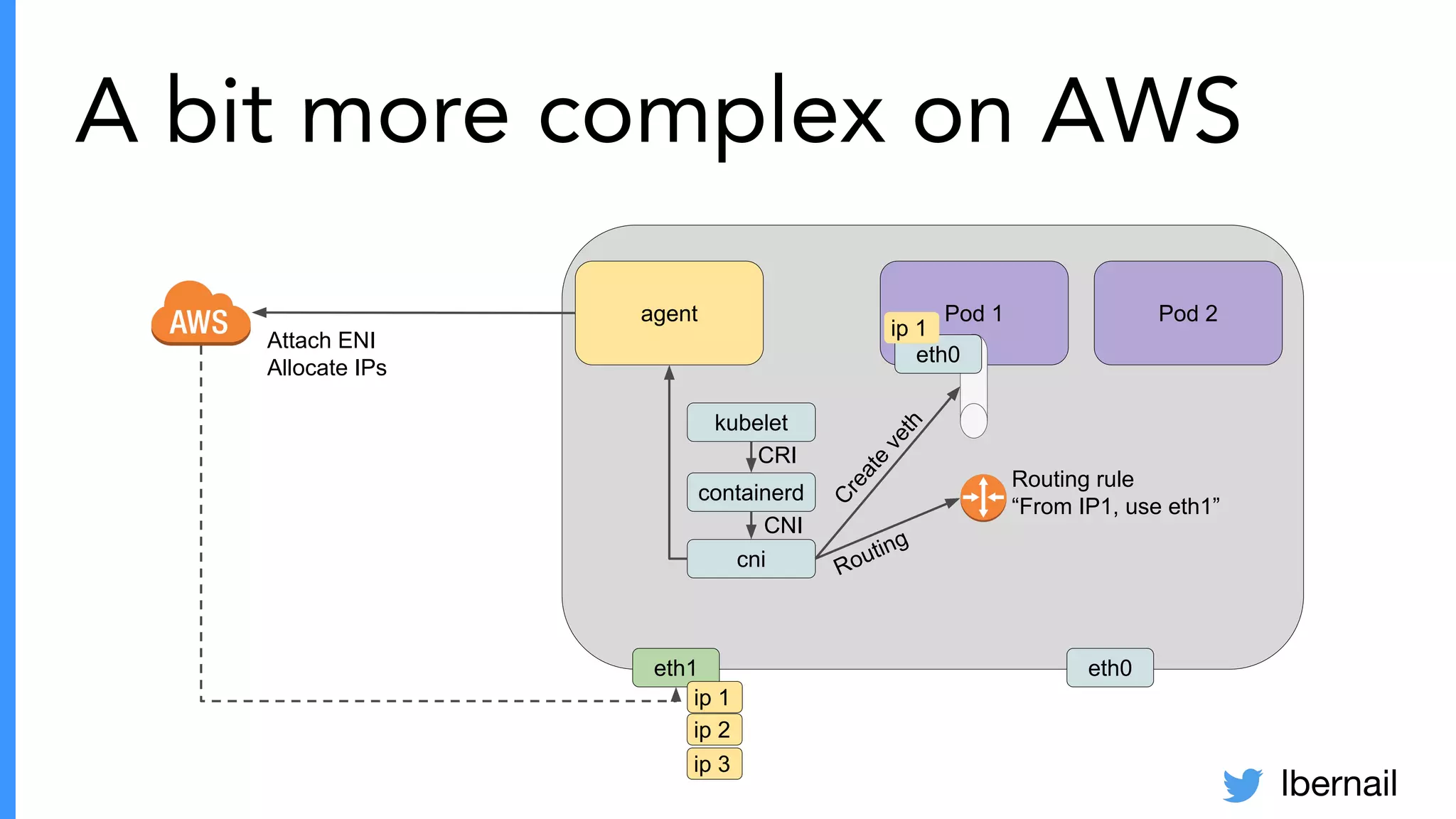



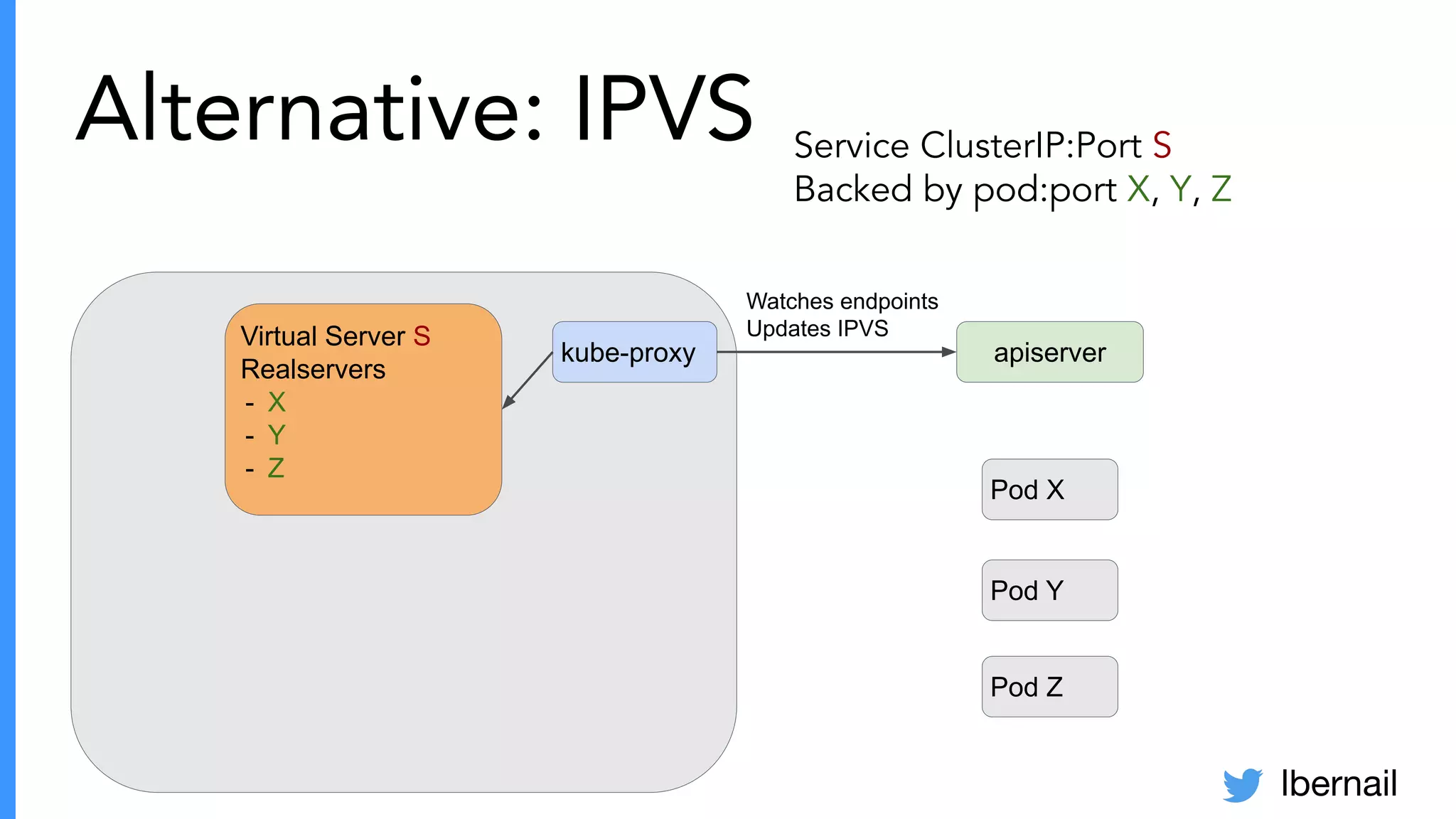
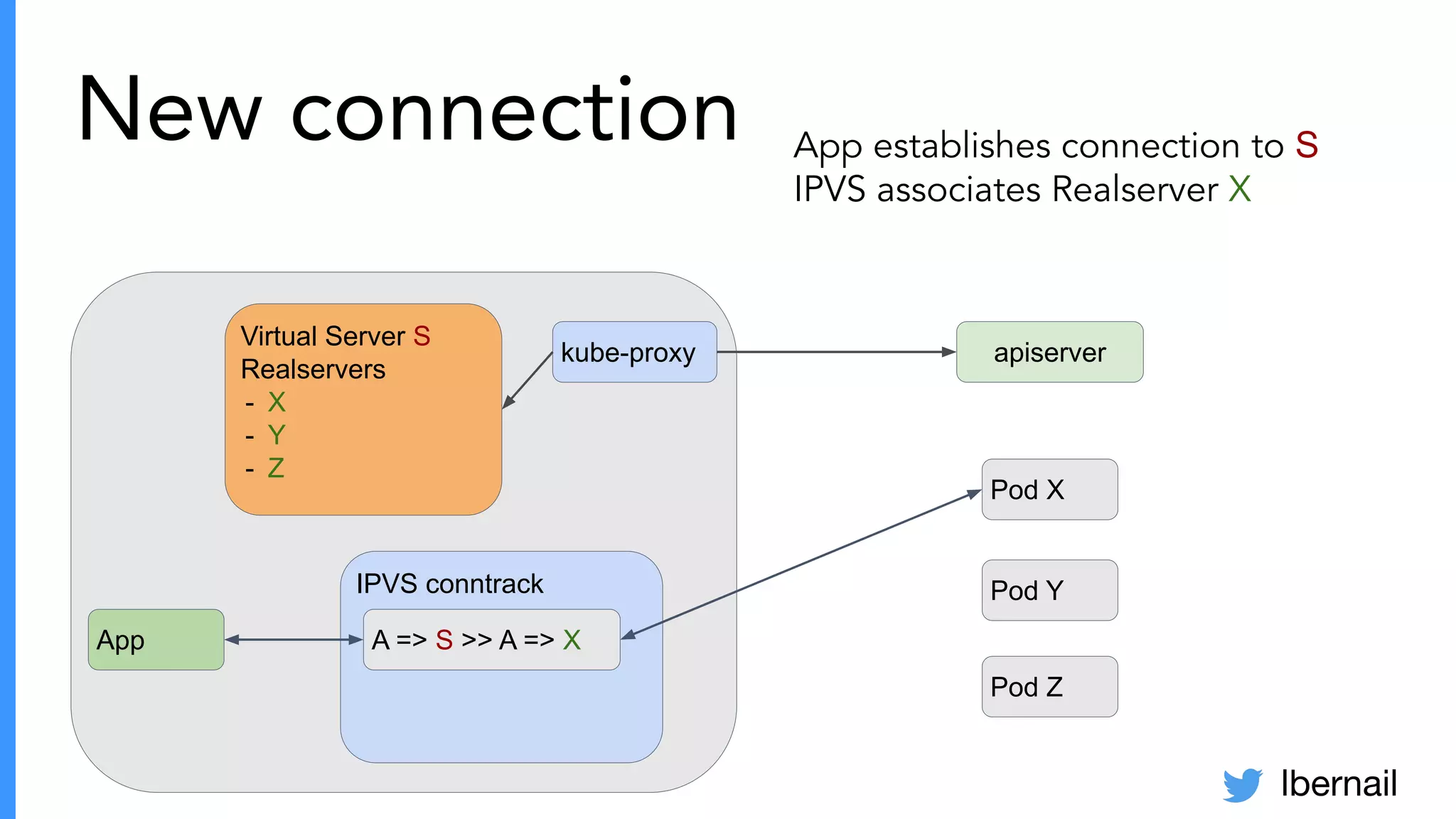
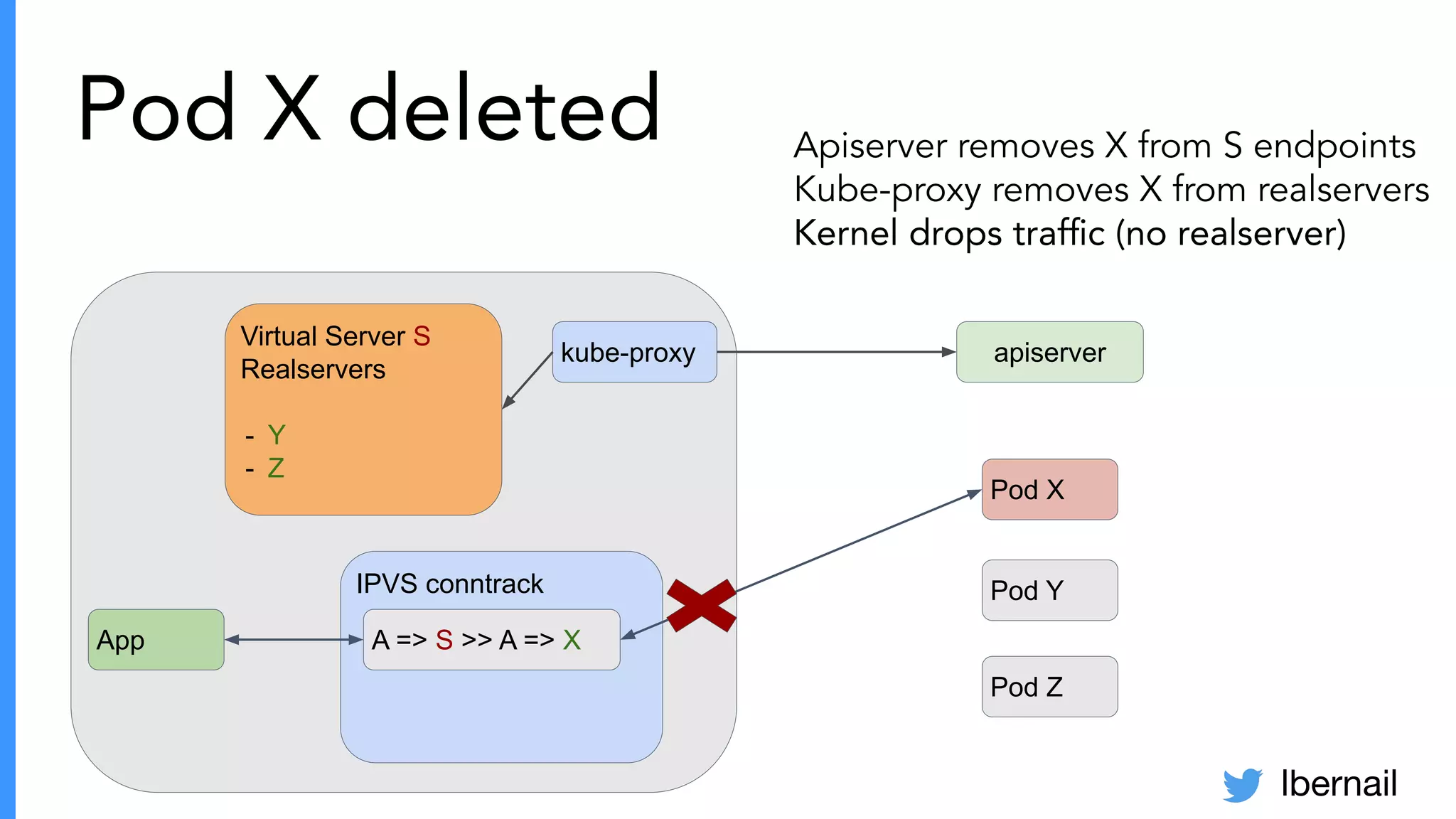
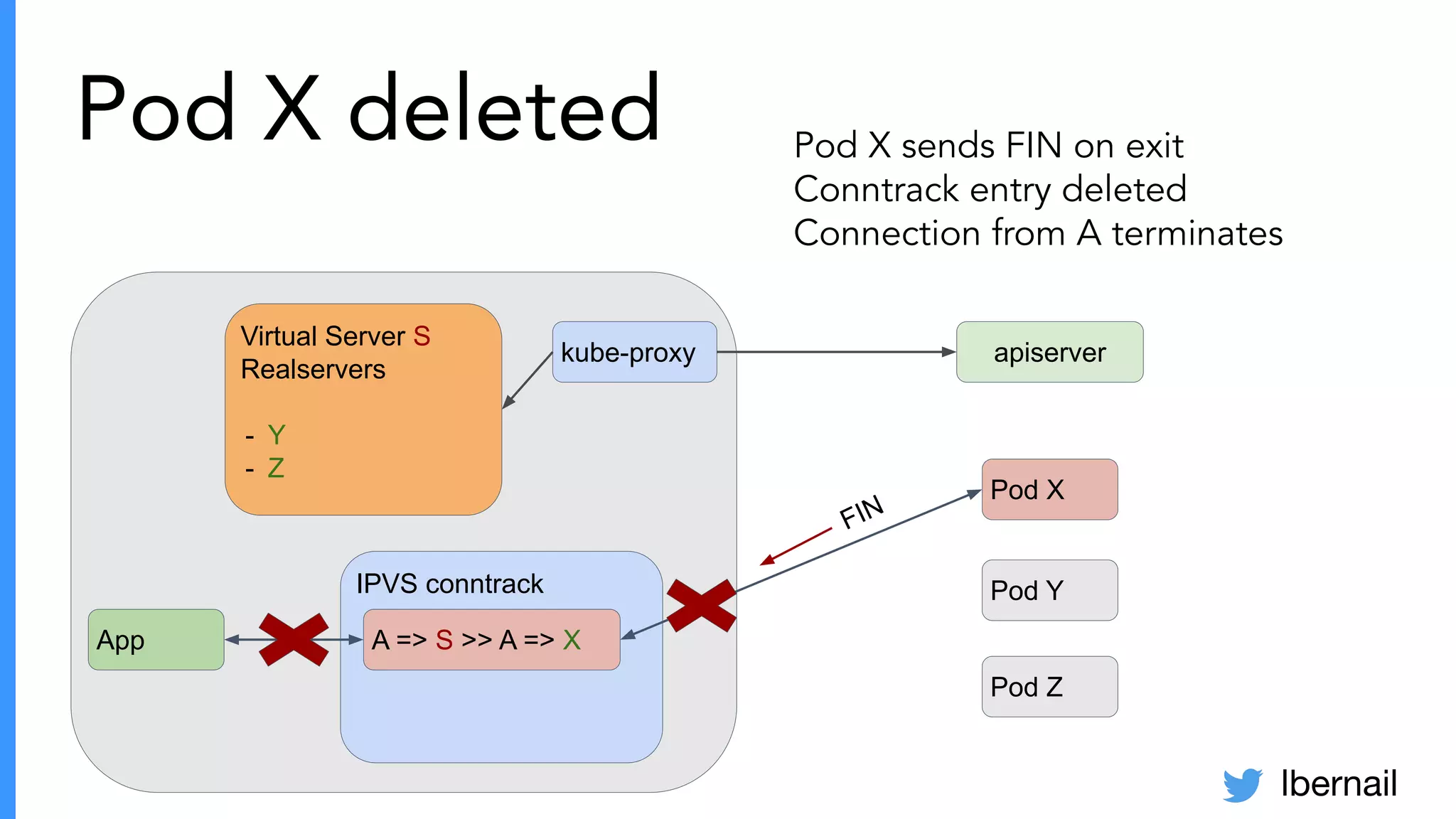
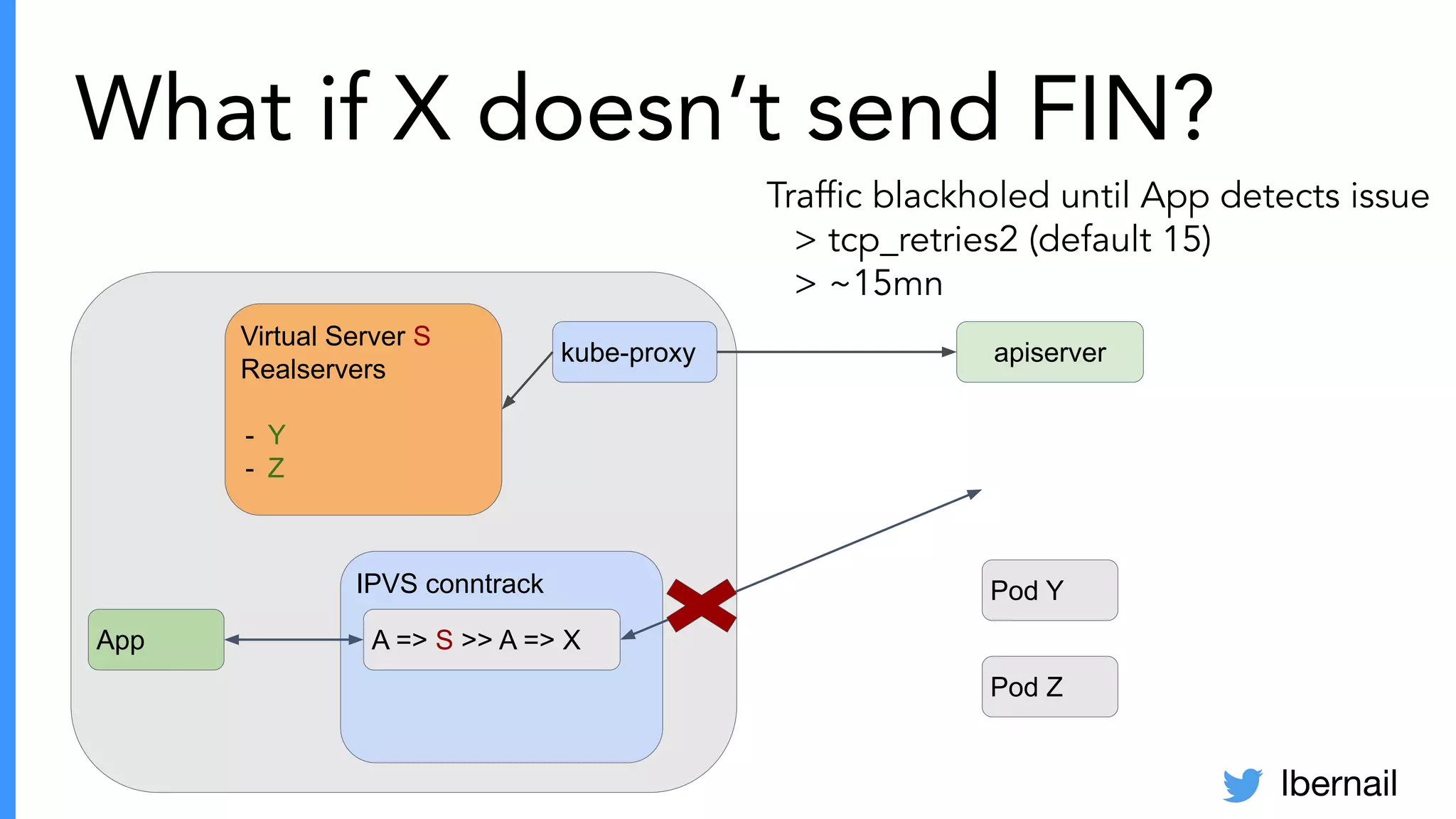
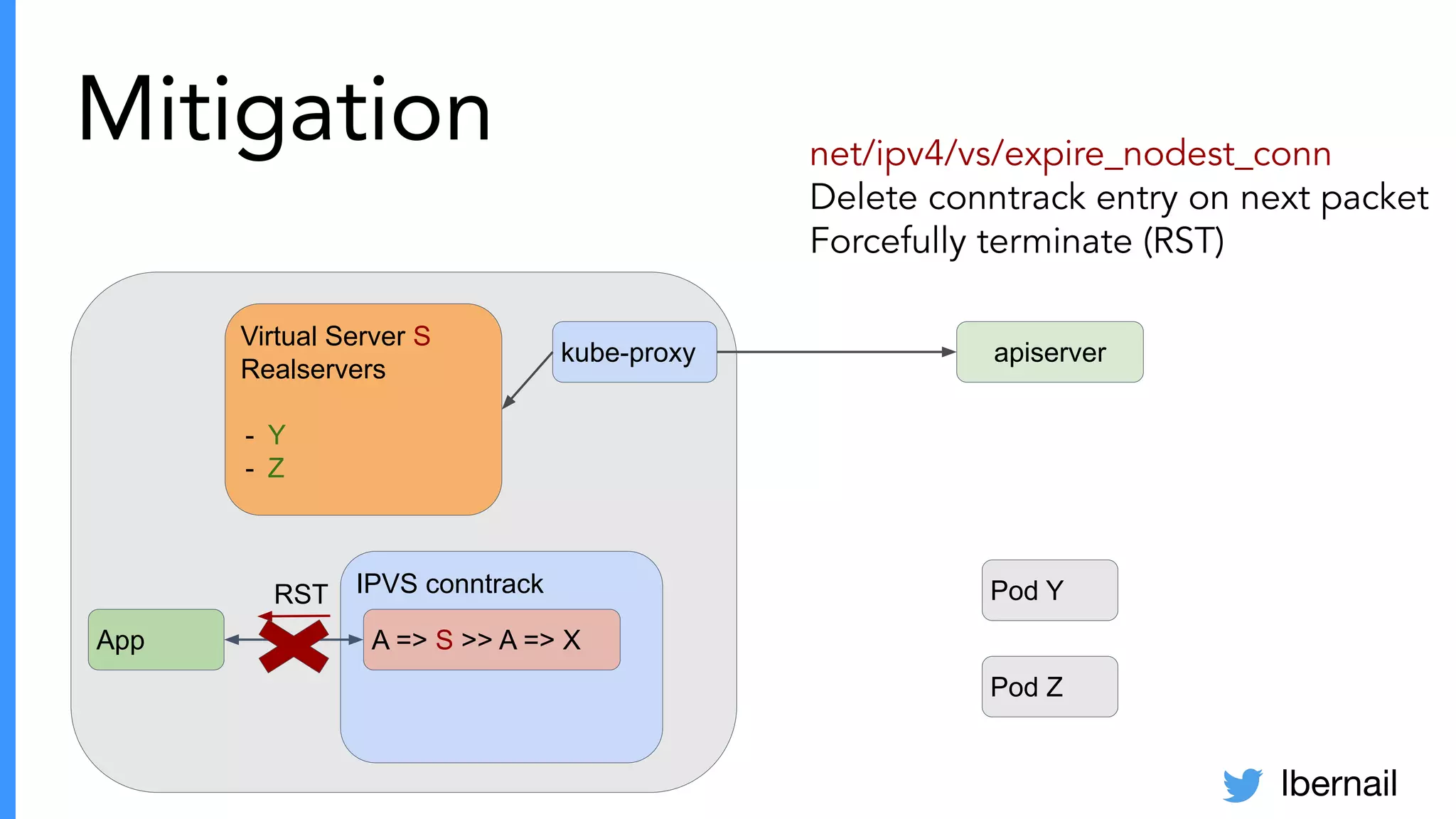

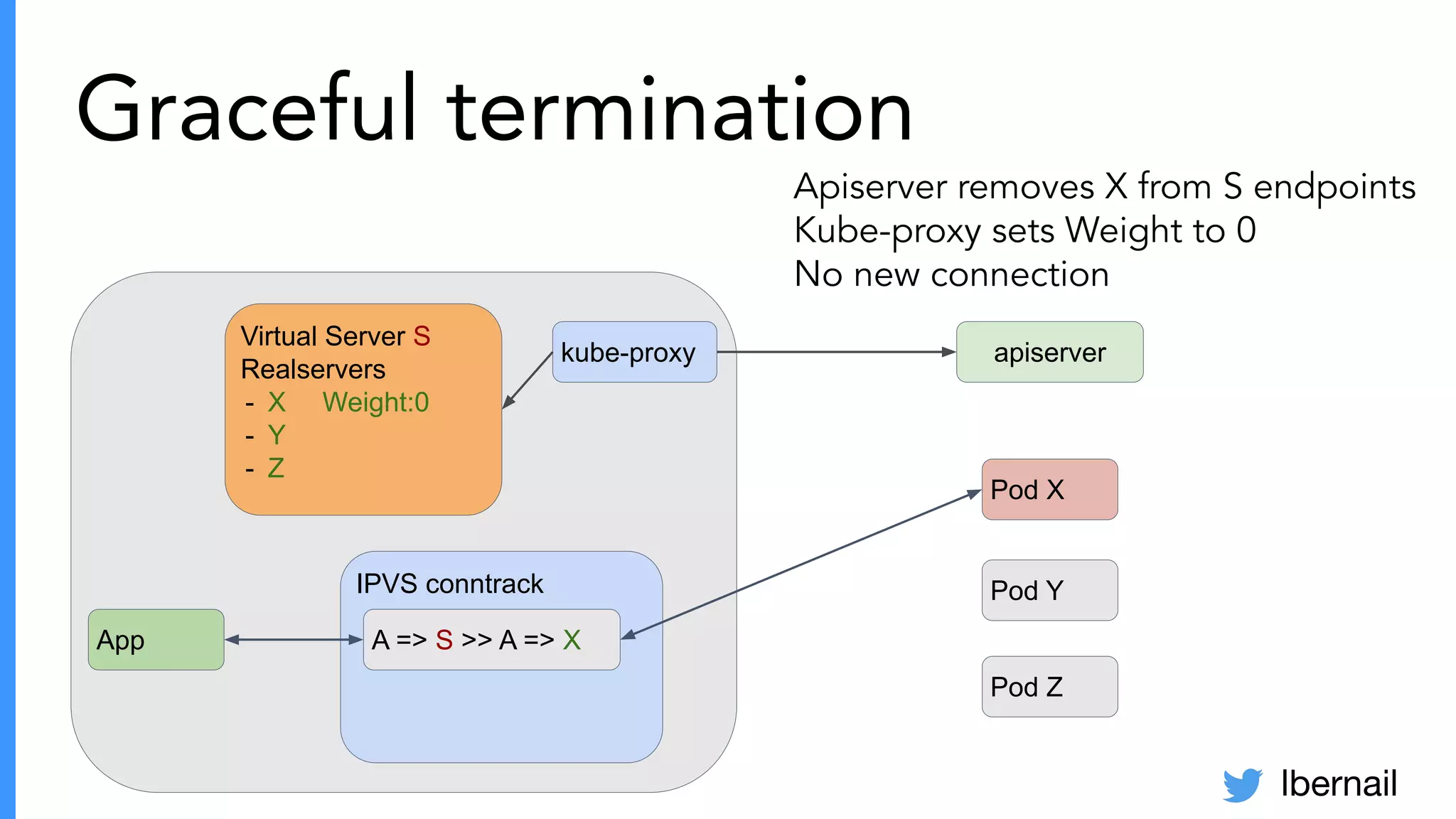
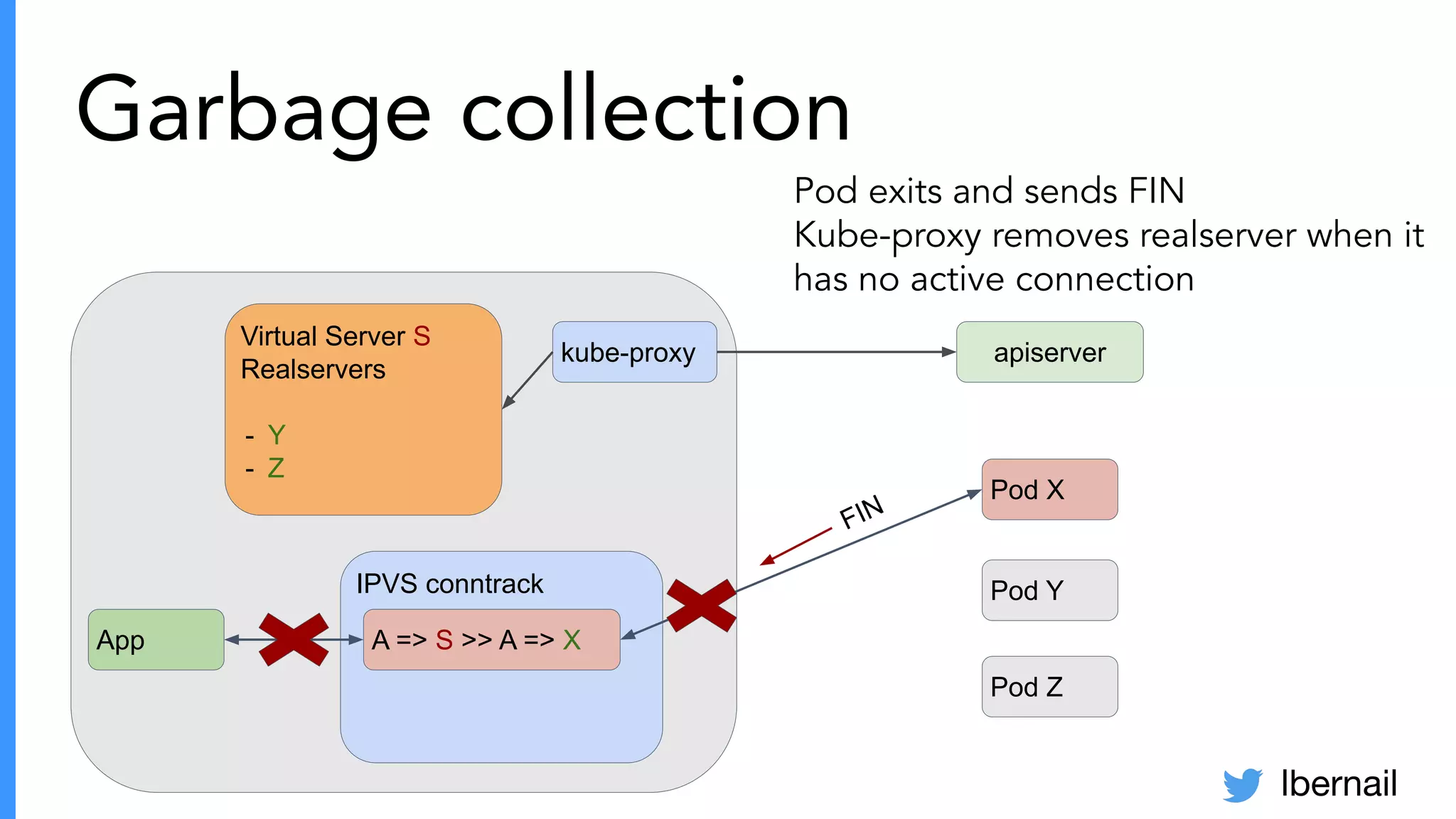



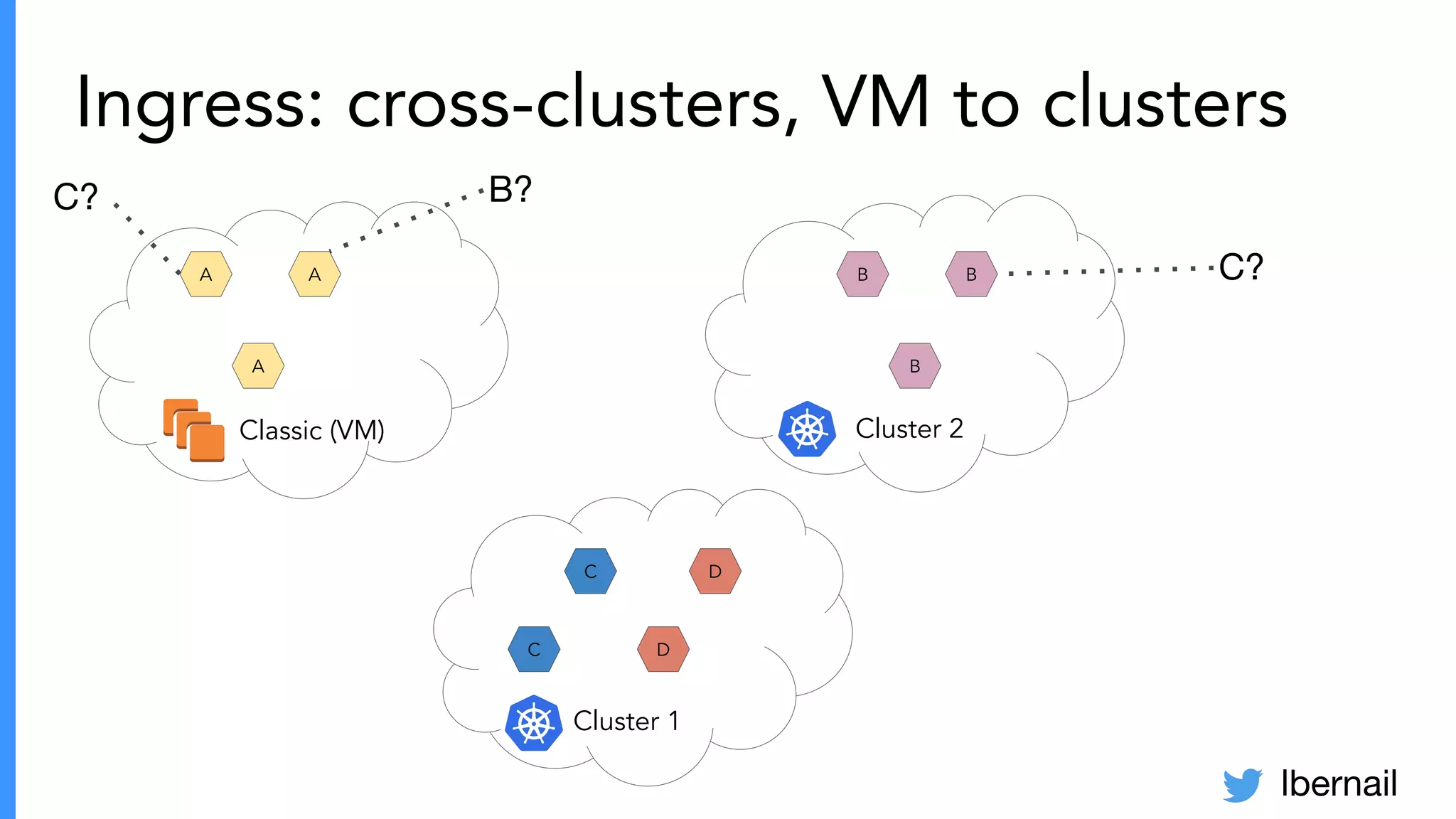
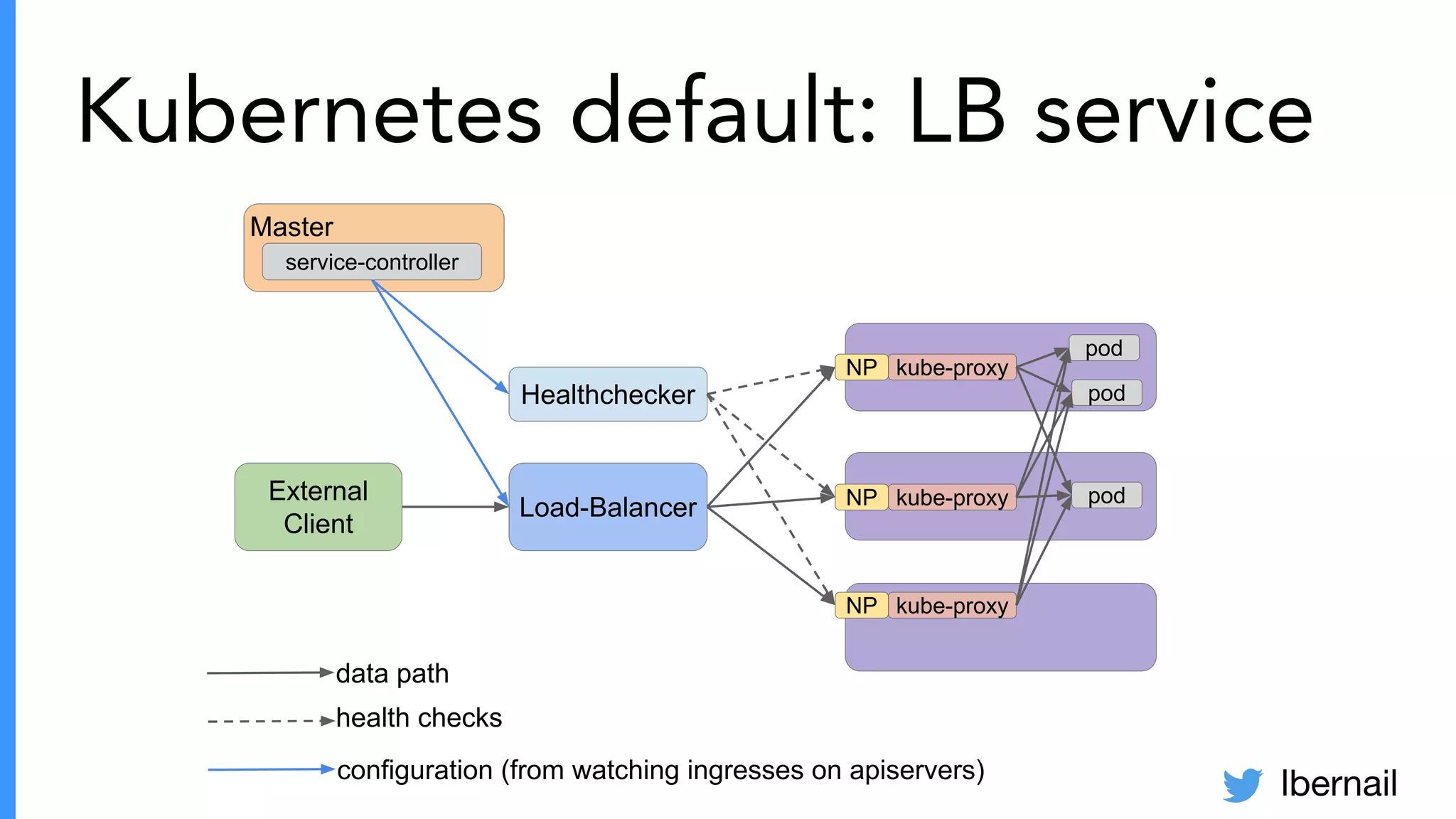
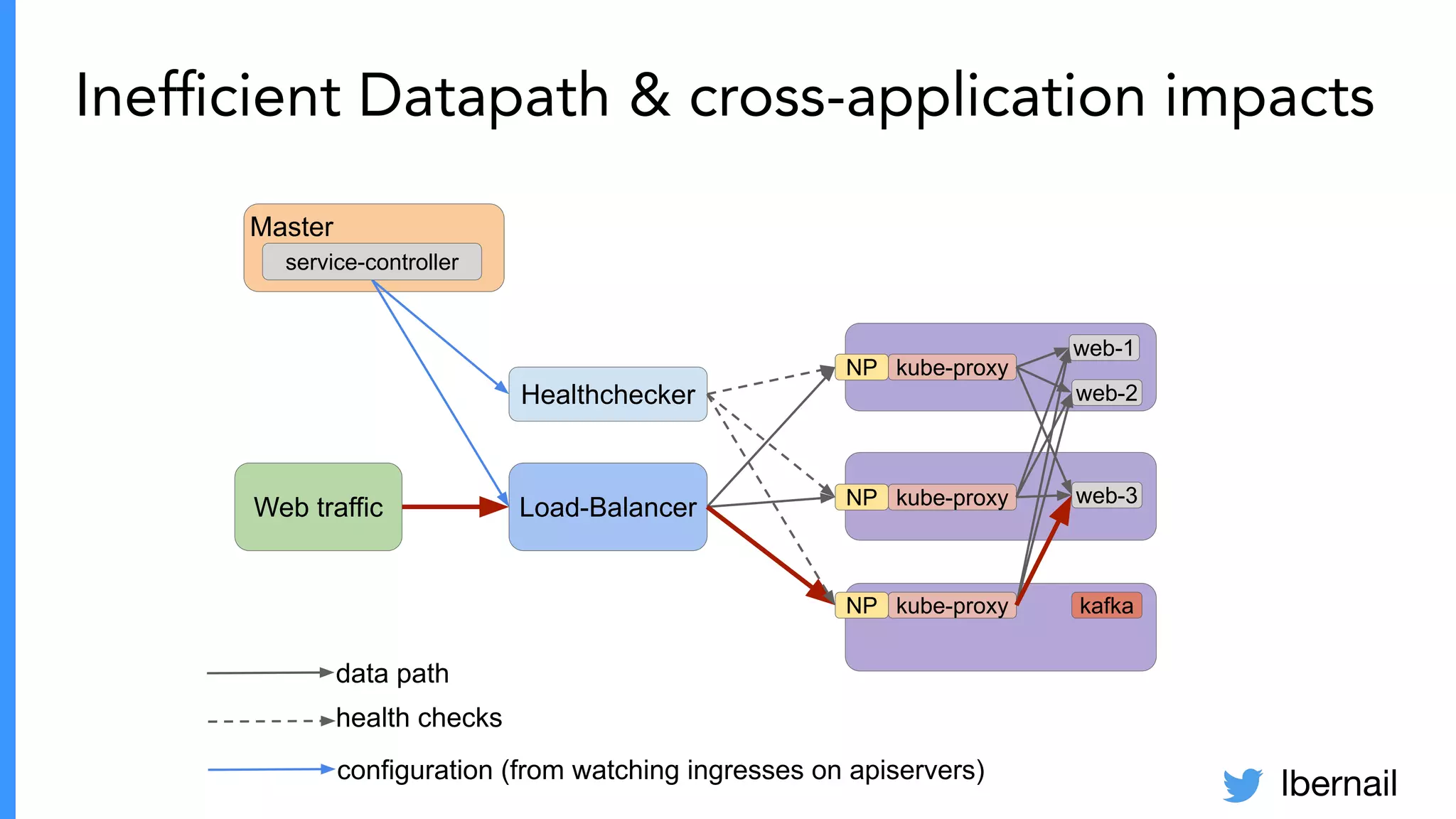
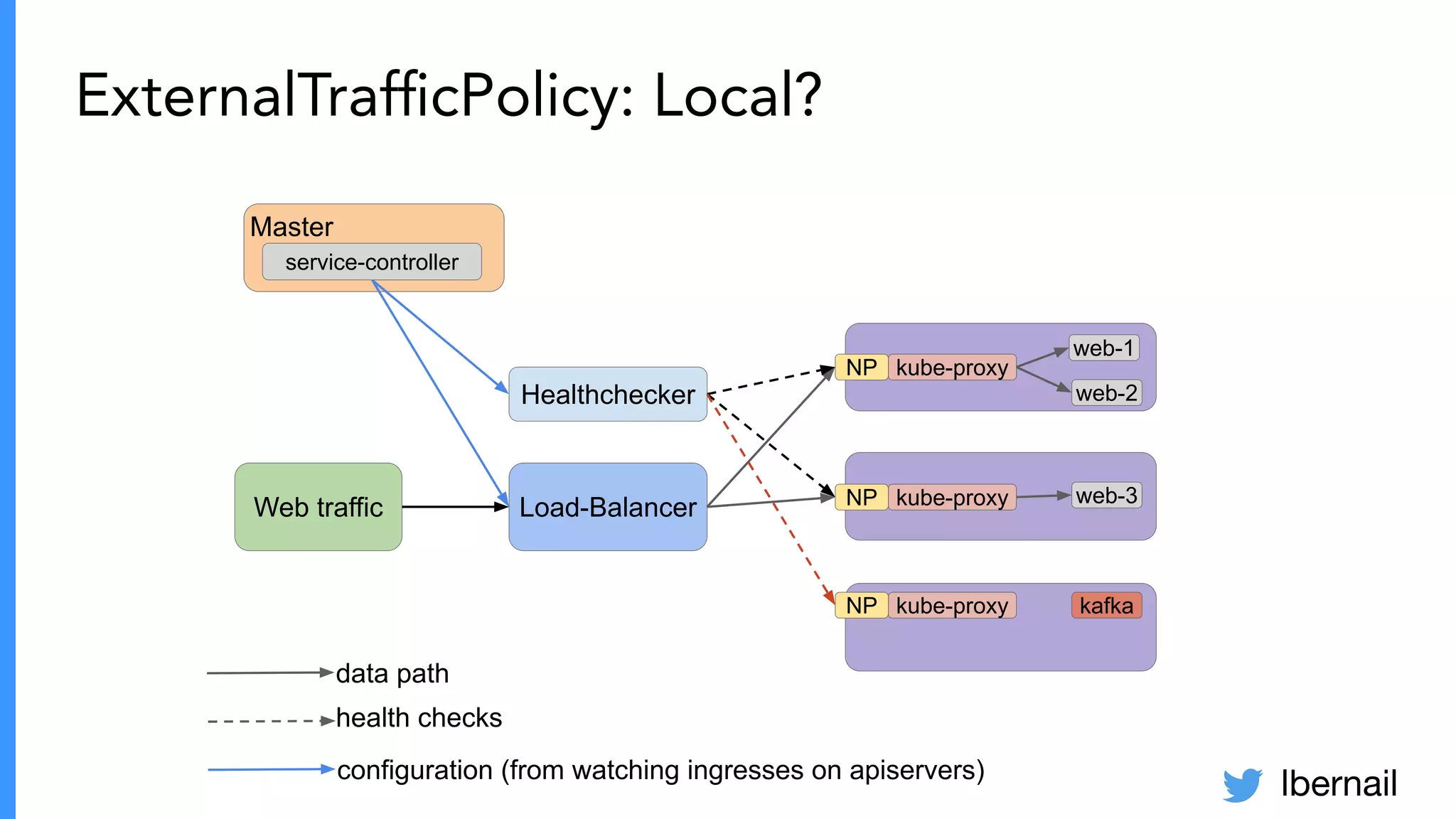
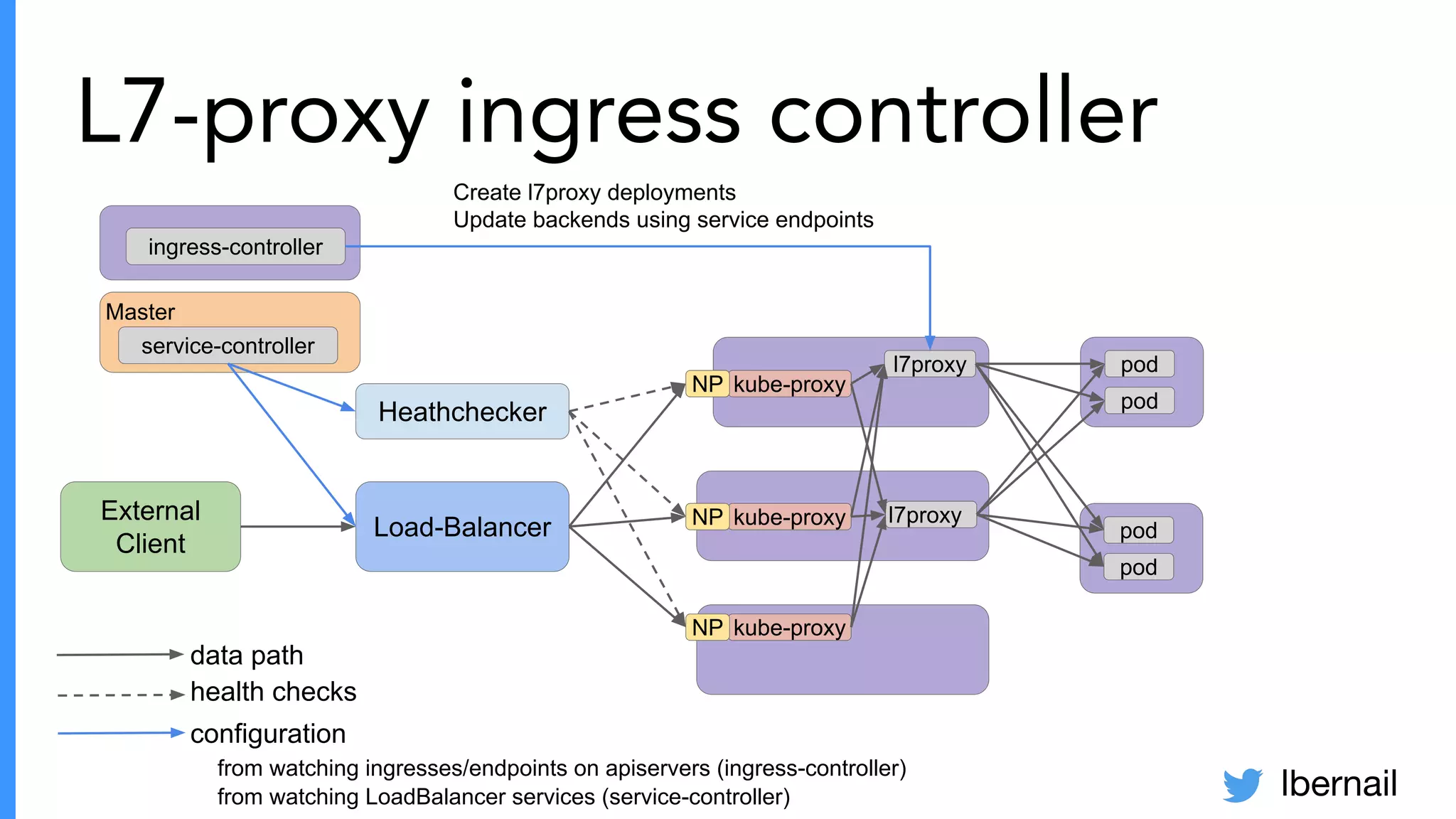

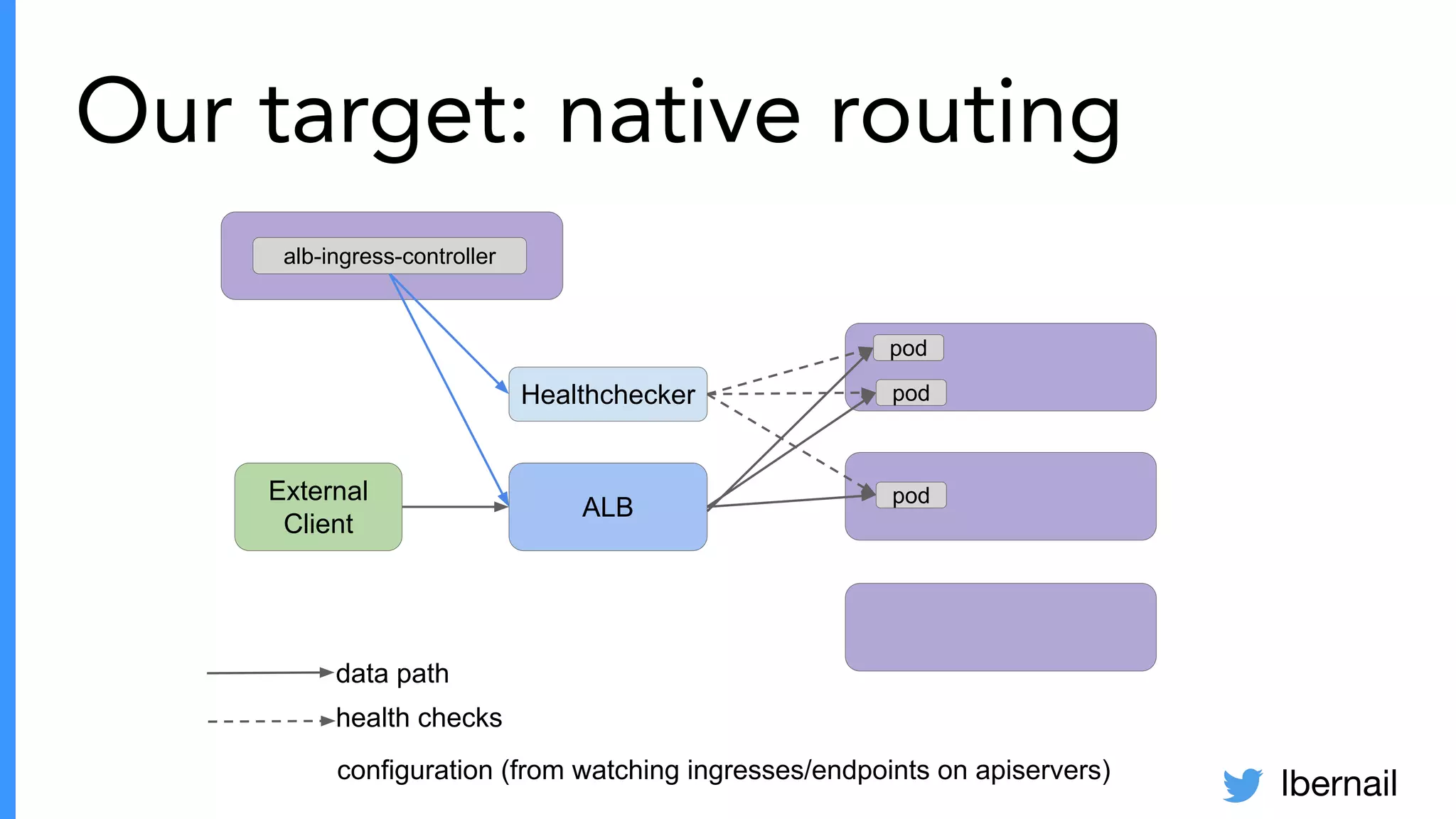

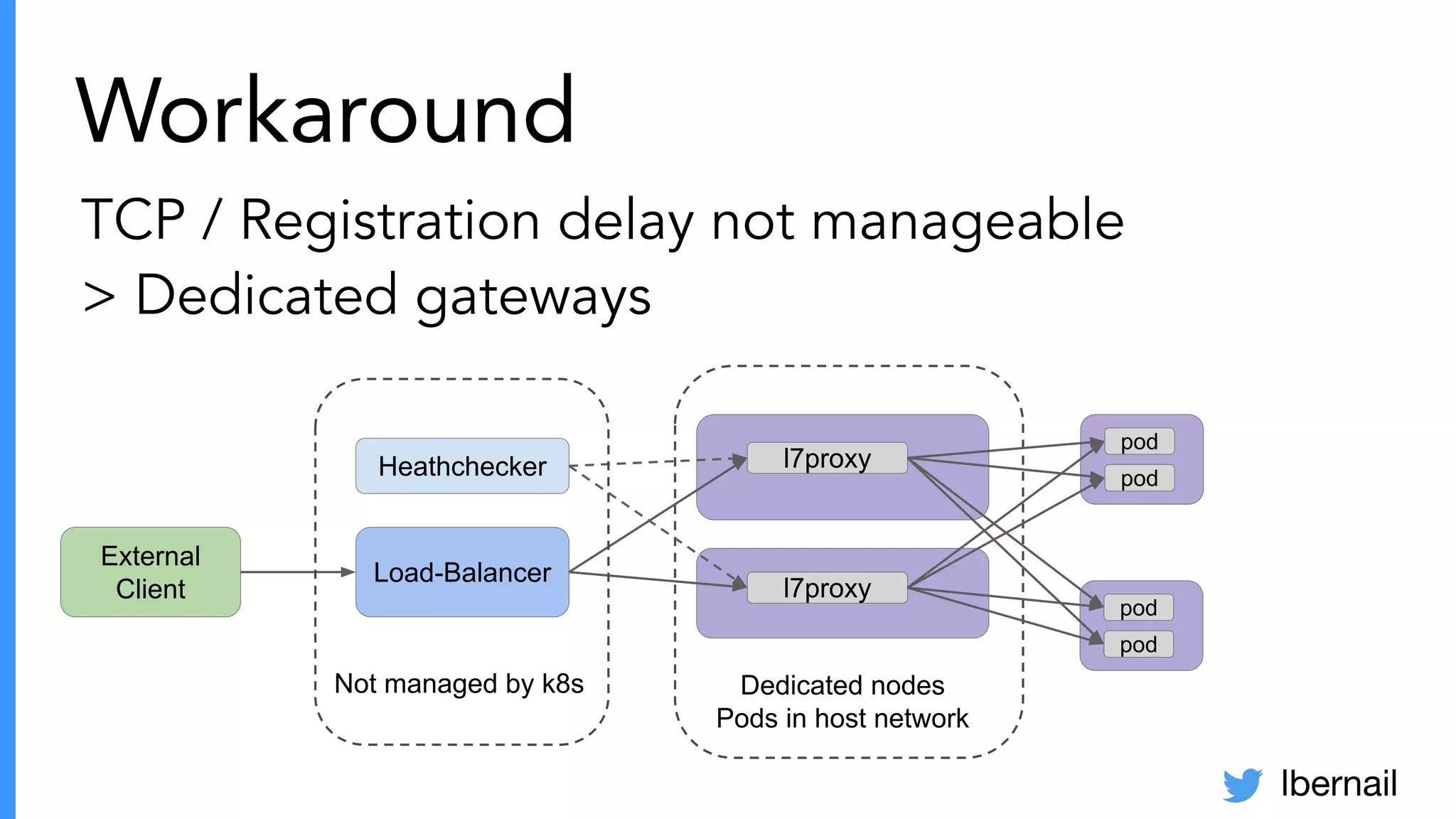






The document elaborates on the complexities and challenges faced in deploying Kubernetes at scale by Datadog, including the necessity for a resilient control plane, management of certificates, and efficient networking strategies. It discusses incidents related to certificate management, networking inefficiencies, and the importance of graceful termination in services while highlighting learnings from practical experiences. The presentation emphasizes that self-managed Kubernetes is challenging and encourages using managed services, underscoring the necessity for team building and user training.















![[오픈소스컨설팅] Linux Network Troubleshooting](https://cdn.slidesharecdn.com/ss_thumbnails/opensourceconsultingnetworktroubleshootingyjlee20210412-210413014206-thumbnail.jpg?width=640&height=640&fit=bounds)








































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















