Downloaded 10 times







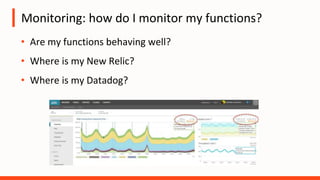
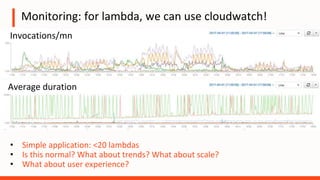

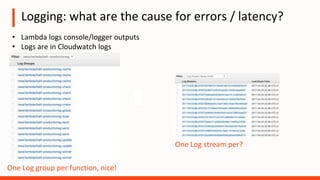




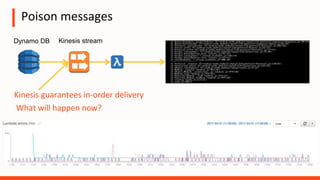

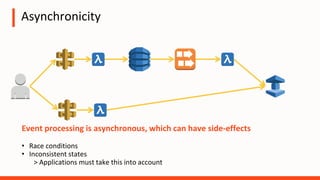













The document discusses the operational challenges associated with serverless architectures, highlighting issues in observability, event-based architecture, and security. It emphasizes the importance of monitoring functions, understanding service behavior, and managing new services like DynamoDB and Kinesis. Additionally, it addresses continuous delivery challenges and the need for new practices in deploying and testing serverless applications.
















































































