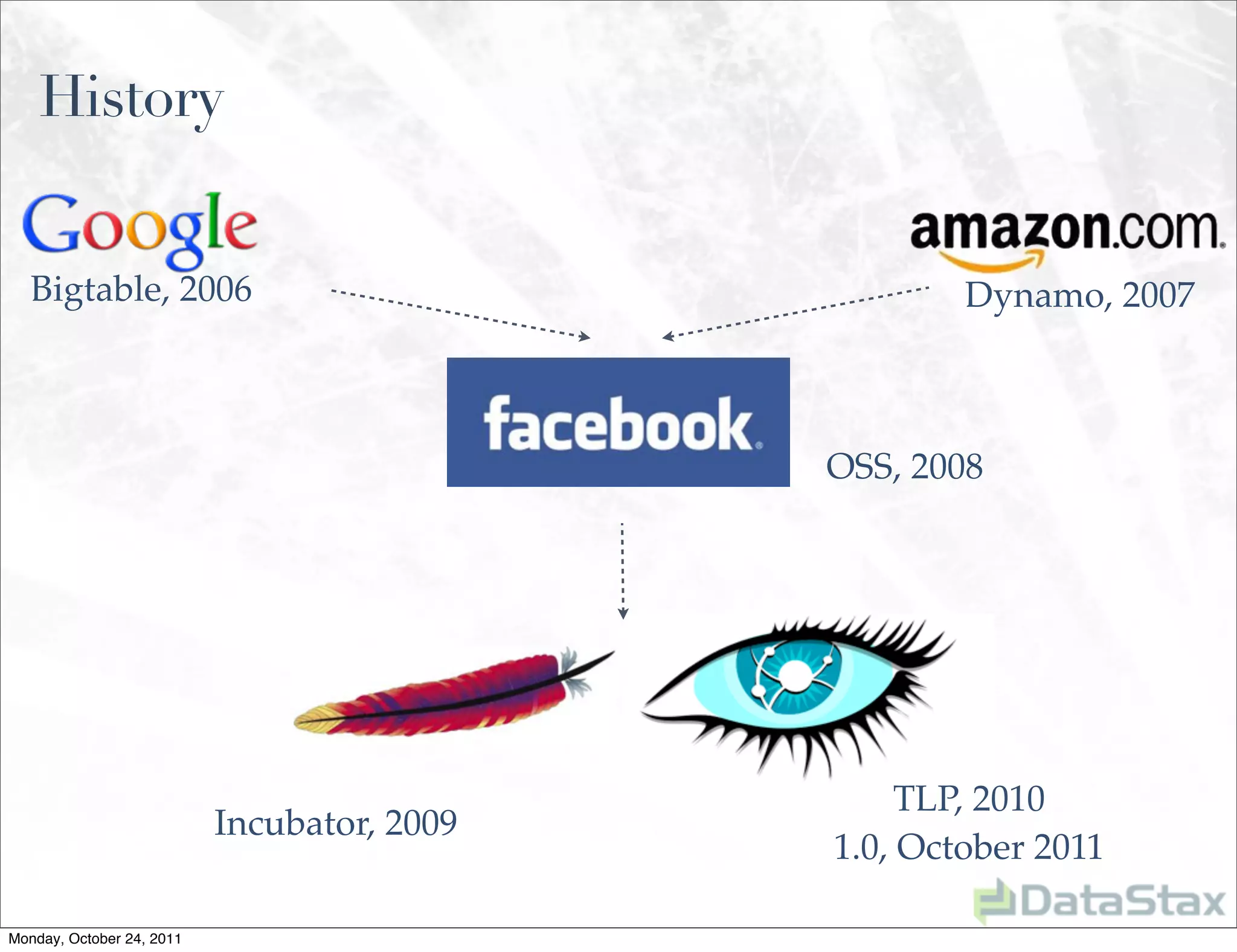
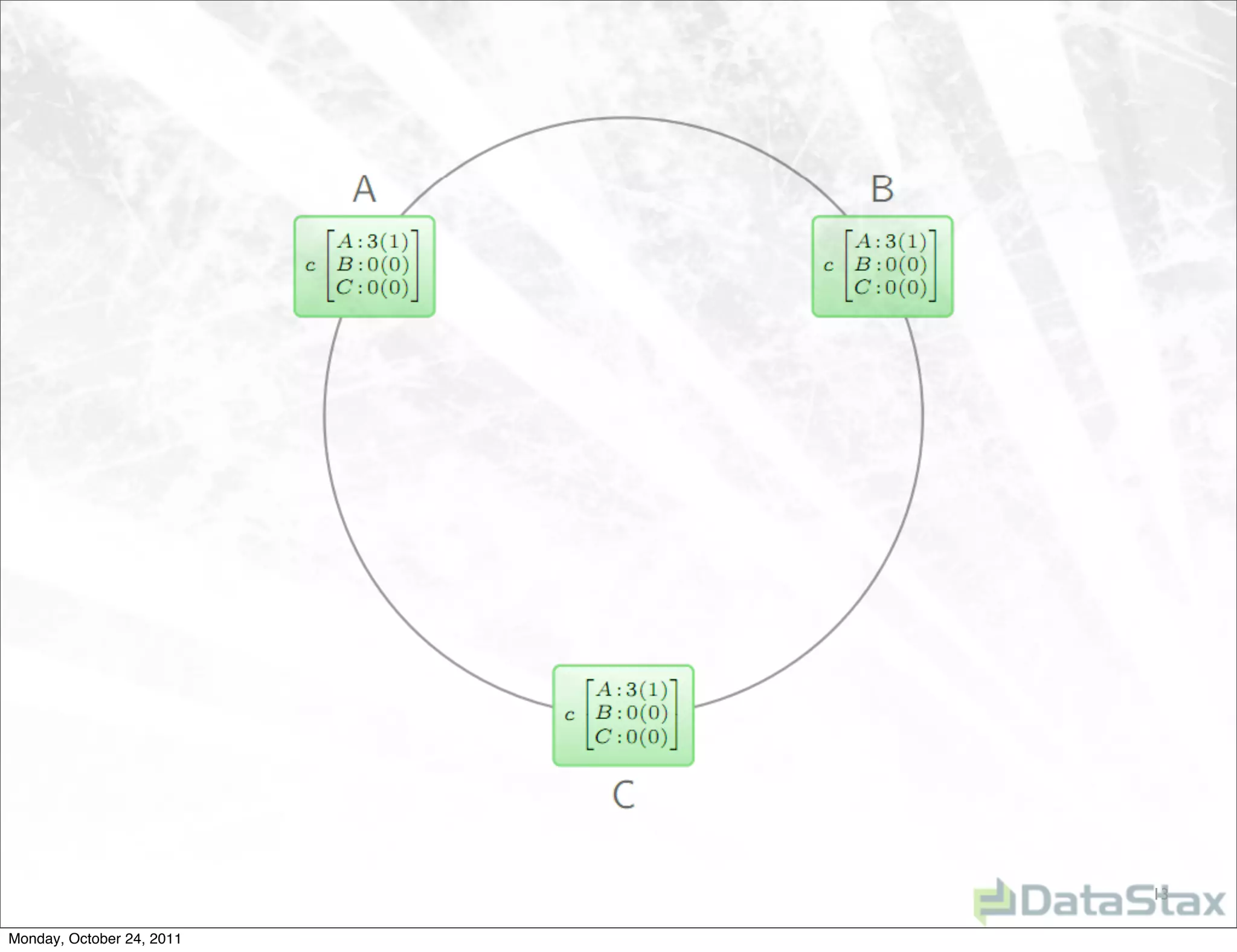
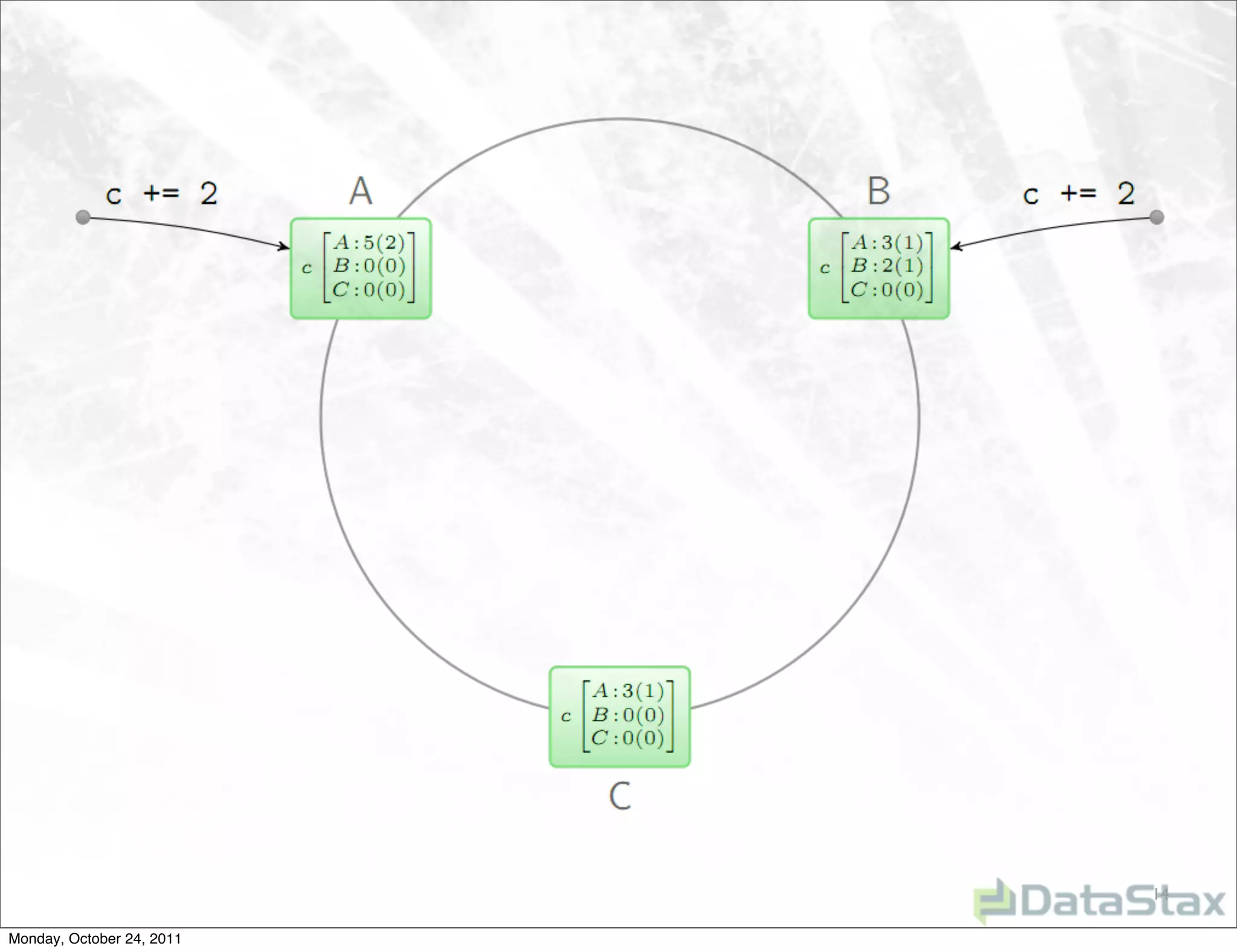
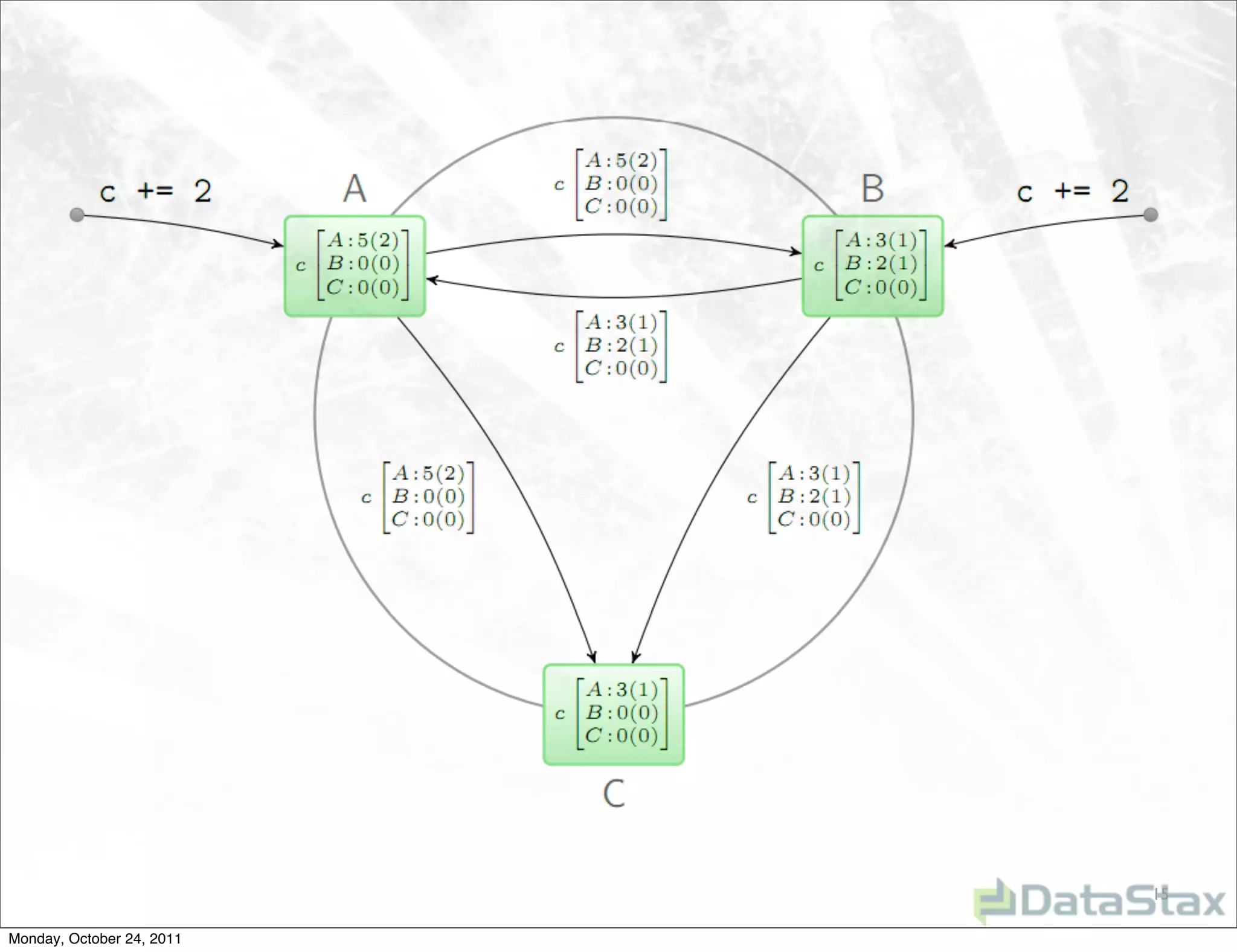
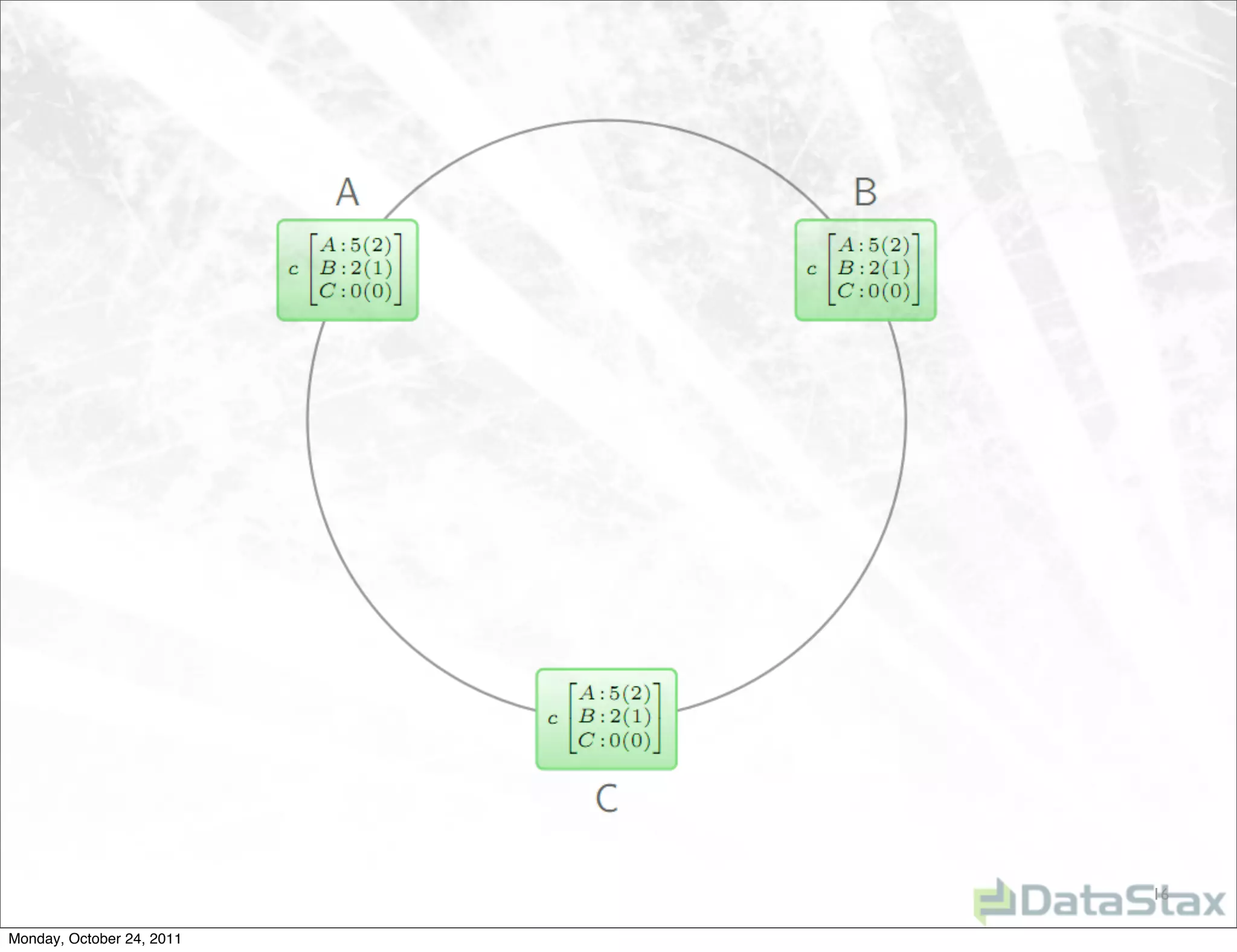
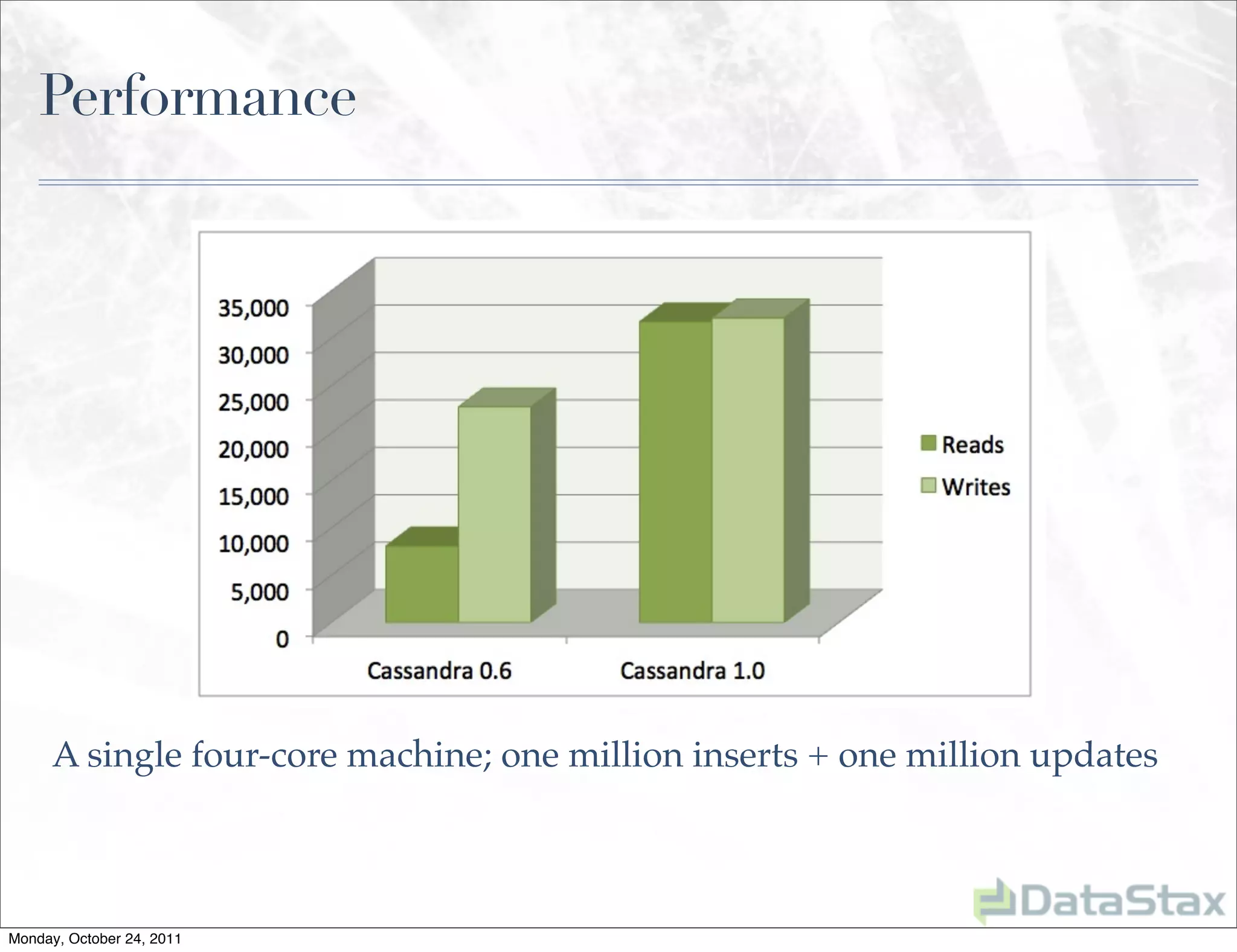
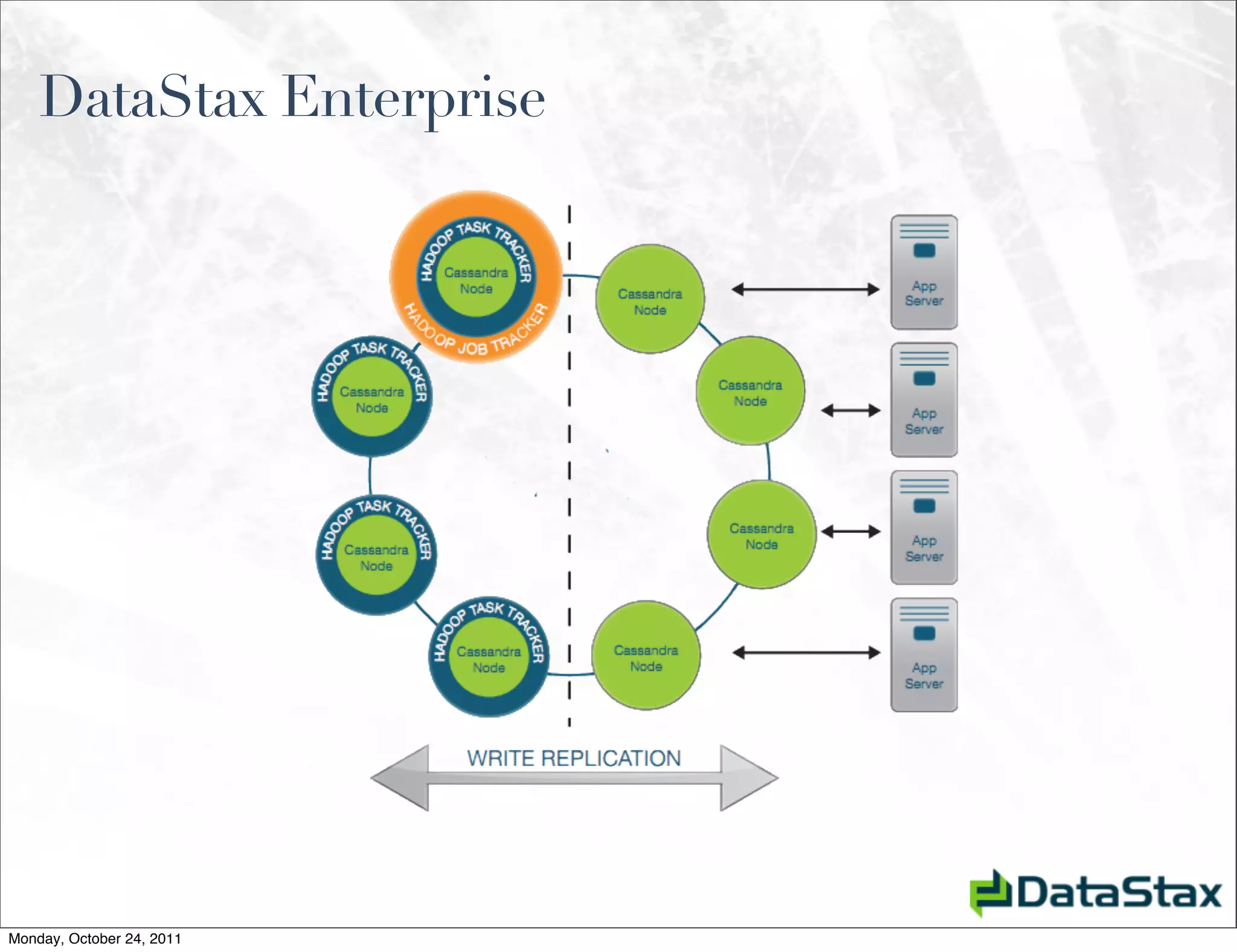
Apache Cassandra is an open source distributed database that provides linearly scalable performance and high availability without a single point of failure. It allows for multi-master and multi-datacenter replication and has a variety of users across different industries. Version 1.0 was released in October 2011, with ongoing work to improve the storage engine, add specialized replication modes, and build an ecosystem of related tools.