Download as PDF, PPTX


















![Current Implementation of GPU Enabler
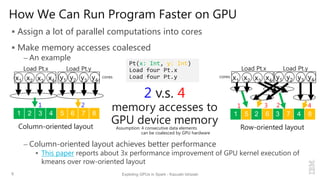
Execute user-provided GPU kernels from map()/reduce() functions
– GPU memory managements and data copy are automatically handled
Generate GPU native code for simple map()/reduce() methods
– “spark.gpu.codegen=true” in spark-defaults.conf
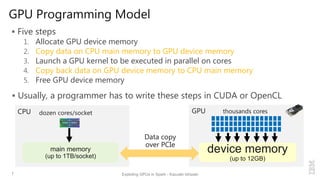
23 Exploting GPUs in Spark - Kazuaki Ishizaki
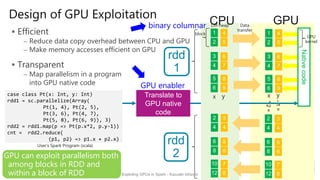
rdd1 = sc.parallelize(1 to n, 2).convert(ColumnFormat) // rdd1 uses binary columnar RDD
sum = rdd1.map(i => i * 2)
.reduce((x, y) => (x + y))
// CUDA
__global__ void sample_map(int *inX, int *inY, int *outX, int *outY, long size) {
long ix = threadIdx.x + blockIdx.x * blockDim.x;
if (size <= ix) return;
outX[ix] = inX[ix] * 2;
outY[ix] = inY[ix] – 1;
}
// Spark
mapFunction = new CUDAFunction(“sample_map", // CUDA method name
Array("this.x", "this.y"), // input object has two fields
Array("this.x“, “this.y”), // output object has two fields
this.getClass.getResource("/sample.ptx")) // ptx is generated by CUDA complier
rdd1 = sc.parallelize(…).convert(ColumnFormat) // rdd1 uses binary columnar RDD
rdd2 = rdd1.mapExtFunc(p => Pt(p.x*2, p.y‐1), mapFunction)](https://image.slidesharecdn.com/hscj2016spark-gpuishizaki-160208153842/85/Exploiting-GPUs-in-Spark-23-320.jpg)
![How to Use GPU Exploitation version
Easy to install by one-liner and to run by one-liner
– on x86_64, mac, and ppc64le with CUDA 7.0 or later with any JVM such as IBM
JDK or OpenJDK
Run script for AWS EC2 is available, which support spot instances24 Exploting GPUs in Spark - Kazuaki Ishizaki
$ wget https://s3.amazonaws.com/spark‐gpu‐public/spark‐gpu‐latest‐bin‐hadoop2.4.tgz &&
tar xf spark‐gpu‐latest‐bin‐hadoop2.4.tgz && cd spark‐gpu
$ LD_LIBRARY_PATH=/usr/local/cuda/lib64 MASTER='local[2]' ./bin/run‐example SparkGPULR 8 3200 32 5
…
numSlices=8, N=3200, D=32, ITERATIONS=5
On iteration 1
On iteration 2
On iteration 3
On iteration 4
On iteration 5
Elapsed time: 431 ms
$
Available at http://kiszk.github.io/spark-gpu/
• 3 contributors
• Private communications
with other developers](https://image.slidesharecdn.com/hscj2016spark-gpuishizaki-160208153842/85/Exploiting-GPUs-in-Spark-24-320.jpg)
![Achieved 3.15x Performance Improvement by GPU
Ran naïve implementation of logistic regression
Achieved 3.15x performance improvement of logistic regression over
without GPU on a 16-core IvyBridge box with an NVIDIA K40 GPU card
– We have rooms to improve performance
25 Exploting GPUs in Spark - Kazuaki Ishizaki
Details are available at https://github.com/kiszk/spark-gpu/wiki/Benchmark
Program parameters
N=1,000,000 (# of points), D=400 (# of features), ITERATIONS=5
Slices=128 (without GPU), 16 (with GPU)
MASTER=local[8] (without and with GPU)
Hardware and software
Machine: nx360 M4, 2 sockets 8‐core Intel Xeon E5‐2667 3.3GHz, 256GB memory, one NVIDIA K40m card
OS: RedHat 6.6, CUDA: 7.0](https://image.slidesharecdn.com/hscj2016spark-gpuishizaki-160208153842/85/Exploiting-GPUs-in-Spark-25-320.jpg)












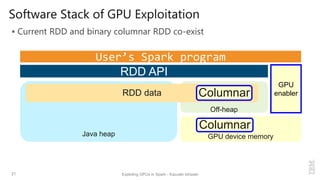
Kazuaki Ishizaki from IBM Tokyo discusses the exploitation of GPUs in Spark to accelerate computation-heavy applications, aiming to enhance performance without requiring users to alter their Spark programs. The presentation outlines the design and implementation of a binary columnar format and a GPU enabler, achieving a performance improvement of 3.15x for logistic regression by effectively utilizing GPU capabilities. Future directions include further integration in Spark 2.0 and beyond, targeting improvements in performance through optimized data handling and execution mechanisms.


























![[OpenInfra Days Korea 2018] Day 2 - CEPH 운영자를 위한 Object Storage Performance T...](https://cdn.slidesharecdn.com/ss_thumbnails/openinfradayobjectstorageperformancefinal2-180704062033-thumbnail.jpg?width=640&height=640&fit=bounds)












































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)















