Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Hirotaka Kawata
12,182 views
本当にわかる Spectre と Meltdown
セキュリティ・キャンプ全国大会2018
Engineering
◦
Related topics:
Insights on Software Development
•
Read more
42
Save
Share
Embed
Embed presentation
Download
Downloaded 110 times
1
/ 107
2
/ 107
3
/ 107
4
/ 107
5
/ 107
6
/ 107
7
/ 107
8
/ 107
9
/ 107
10
/ 107
11
/ 107
12
/ 107
Most read
13
/ 107
14
/ 107
15
/ 107
16
/ 107
17
/ 107
18
/ 107
19
/ 107
20
/ 107
21
/ 107
22
/ 107
23
/ 107
24
/ 107
25
/ 107
26
/ 107
27
/ 107
28
/ 107
29
/ 107
30
/ 107
31
/ 107
32
/ 107
33
/ 107
34
/ 107
35
/ 107
36
/ 107
37
/ 107
38
/ 107
39
/ 107
40
/ 107
41
/ 107
42
/ 107
43
/ 107
44
/ 107
45
/ 107
46
/ 107
47
/ 107
48
/ 107
49
/ 107
50
/ 107
51
/ 107
52
/ 107
53
/ 107
54
/ 107
Most read
55
/ 107
56
/ 107
57
/ 107
58
/ 107
59
/ 107
60
/ 107
61
/ 107
62
/ 107
63
/ 107
64
/ 107
65
/ 107
66
/ 107
67
/ 107
Most read
68
/ 107
69
/ 107
70
/ 107
71
/ 107
72
/ 107
73
/ 107
74
/ 107
75
/ 107
76
/ 107
77
/ 107
78
/ 107
79
/ 107
80
/ 107
81
/ 107
82
/ 107
83
/ 107
84
/ 107
85
/ 107
86
/ 107
87
/ 107
88
/ 107
89
/ 107
90
/ 107
91
/ 107
92
/ 107
93
/ 107
94
/ 107
95
/ 107
96
/ 107
97
/ 107
98
/ 107
99
/ 107
100
/ 107
101
/ 107
102
/ 107
103
/ 107
104
/ 107
105
/ 107
106
/ 107
107
/ 107
More Related Content
PDF
SpectreとMeltdown:最近のCPUの深い話
by
LINE Corporation
PDF
Docker Compose 徹底解説
by
Masahito Zembutsu
PDF
CEDEC 2018 最速のC#の書き方 - C#大統一理論へ向けて性能的課題を払拭する
by
Yoshifumi Kawai
PDF
エンジニアなら知っておきたい「仮想マシン」のしくみ v1.1 (hbstudy 17)
by
Takeshi HASEGAWA
PDF
実践イカパケット解析
by
Yuki Mizuno
PPTX
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~
by
Miki Shimogai
PDF
CUDAのアセンブリ言語基礎のまとめ PTXとSASSの概説
by
Takateru Yamagishi
PDF
コンテナの作り方「Dockerは裏方で何をしているのか?」
by
Masahito Zembutsu
SpectreとMeltdown:最近のCPUの深い話
by
LINE Corporation
Docker Compose 徹底解説
by
Masahito Zembutsu
CEDEC 2018 最速のC#の書き方 - C#大統一理論へ向けて性能的課題を払拭する
by
Yoshifumi Kawai
エンジニアなら知っておきたい「仮想マシン」のしくみ v1.1 (hbstudy 17)
by
Takeshi HASEGAWA
実践イカパケット解析
by
Yuki Mizuno
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~
by
Miki Shimogai
CUDAのアセンブリ言語基礎のまとめ PTXとSASSの概説
by
Takateru Yamagishi
コンテナの作り方「Dockerは裏方で何をしているのか?」
by
Masahito Zembutsu
What's hot
PDF
今日からできる!簡単 .NET 高速化 Tips
by
Takaaki Suzuki
PDF
Dockerからcontainerdへの移行
by
Kohei Tokunaga
PDF
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
PDF
例外設計における大罪
by
Takuto Wada
PDF
DSIRNLP #3 LZ4 の速さの秘密に迫ってみる
by
Atsushi KOMIYA
PDF
ゲーム開発者のための C++11/C++14
by
Ryo Suzuki
PDF
プログラムを高速化する話
by
京大 マイコンクラブ
PDF
Scapyで作る・解析するパケット
by
Takaaki Hoyo
PDF
いつやるの?Git入門 v1.1.0
by
Masakazu Matsushita
PDF
目grep入門 +解説
by
murachue
PPTX
世界一わかりやすいClean Architecture
by
Atsushi Nakamura
PDF
Docker入門: コンテナ型仮想化技術の仕組みと使い方
by
Yuichi Ito
PDF
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
PPTX
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
PDF
組み込み関数(intrinsic)によるSIMD入門
by
Norishige Fukushima
PDF
SAT/SMTソルバの仕組み
by
Masahiro Sakai
PPTX
LUT-Network その後の話(2022/05/07)
by
ryuz88
PPTX
30分で分かる!OSの作り方
by
uchan_nos
PPT
Glibc malloc internal
by
Motohiro KOSAKI
PDF
Docker Compose入門~今日から始めるComposeの初歩からswarm mode対応まで
by
Masahito Zembutsu
今日からできる!簡単 .NET 高速化 Tips
by
Takaaki Suzuki
Dockerからcontainerdへの移行
by
Kohei Tokunaga
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
例外設計における大罪
by
Takuto Wada
DSIRNLP #3 LZ4 の速さの秘密に迫ってみる
by
Atsushi KOMIYA
ゲーム開発者のための C++11/C++14
by
Ryo Suzuki
プログラムを高速化する話
by
京大 マイコンクラブ
Scapyで作る・解析するパケット
by
Takaaki Hoyo
いつやるの?Git入門 v1.1.0
by
Masakazu Matsushita
目grep入門 +解説
by
murachue
世界一わかりやすいClean Architecture
by
Atsushi Nakamura
Docker入門: コンテナ型仮想化技術の仕組みと使い方
by
Yuichi Ito
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
組み込み関数(intrinsic)によるSIMD入門
by
Norishige Fukushima
SAT/SMTソルバの仕組み
by
Masahiro Sakai
LUT-Network その後の話(2022/05/07)
by
ryuz88
30分で分かる!OSの作り方
by
uchan_nos
Glibc malloc internal
by
Motohiro KOSAKI
Docker Compose入門~今日から始めるComposeの初歩からswarm mode対応まで
by
Masahito Zembutsu
Similar to 本当にわかる Spectre と Meltdown
PDF
Spectre/Meltdownとその派生
by
MITSUNARI Shigeo
PDF
プロセスとコンテキストスイッチ
by
Kazuki Onishi
PDF
SpectreBustersあるいはLinuxにおけるSpectre対策
by
Masami Hiramatsu
PDF
あるコンテキストスイッチの話
by
nullnilaki
PDF
0章 Linuxカーネルを読む前に最低限知っておくべきこと
by
mao999
PDF
バイナリより低レイヤな話 (プロセッサの心を読み解く) - カーネル/VM探検隊@北陸1
by
Hirotaka Kawata
PDF
Linuxのプロセススケジューラ(Reading the Linux process scheduler)
by
Hiraku Toyooka
PDF
CPUの同時実行機能
by
Shinichiro Niiyama
PPTX
Interrupts on xv6
by
Takuya ASADA
PDF
4章 Linuxカーネル - 割り込み・例外 4
by
mao999
PDF
[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理
by
Yuto Takei
PDF
【学習メモ#7th】12ステップで作る組込みOS自作入門
by
sandai
PDF
PEZY-SC programming overview
by
Ryo Sakamoto
PDF
Cpu cache arch
by
Shinichiro Niiyama
PPTX
Meltdown を正しく理解する
by
Norimasa FUJITA
PDF
Meltdown/Spectreの脆弱性、リスク、対策
by
Isaac Mathis
PDF
Code jp2015 cpuの話
by
Shinichiro Niiyama
PPTX
20200709 fjt7tdmi-blog-appendix
by
Akifumi Fujita
PDF
2012-04-25 ASPLOS2012出張報告(公開版)
by
Takahiro Shinagawa
PDF
C base design methodology with s dx and xilinx ml
by
ssuser3a4b8c
Spectre/Meltdownとその派生
by
MITSUNARI Shigeo
プロセスとコンテキストスイッチ
by
Kazuki Onishi
SpectreBustersあるいはLinuxにおけるSpectre対策
by
Masami Hiramatsu
あるコンテキストスイッチの話
by
nullnilaki
0章 Linuxカーネルを読む前に最低限知っておくべきこと
by
mao999
バイナリより低レイヤな話 (プロセッサの心を読み解く) - カーネル/VM探検隊@北陸1
by
Hirotaka Kawata
Linuxのプロセススケジューラ(Reading the Linux process scheduler)
by
Hiraku Toyooka
CPUの同時実行機能
by
Shinichiro Niiyama
Interrupts on xv6
by
Takuya ASADA
4章 Linuxカーネル - 割り込み・例外 4
by
mao999
[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理
by
Yuto Takei
【学習メモ#7th】12ステップで作る組込みOS自作入門
by
sandai
PEZY-SC programming overview
by
Ryo Sakamoto
Cpu cache arch
by
Shinichiro Niiyama
Meltdown を正しく理解する
by
Norimasa FUJITA
Meltdown/Spectreの脆弱性、リスク、対策
by
Isaac Mathis
Code jp2015 cpuの話
by
Shinichiro Niiyama
20200709 fjt7tdmi-blog-appendix
by
Akifumi Fujita
2012-04-25 ASPLOS2012出張報告(公開版)
by
Takahiro Shinagawa
C base design methodology with s dx and xilinx ml
by
ssuser3a4b8c
More from Hirotaka Kawata
PPTX
ゼロから始める自作 CPU 入門
by
Hirotaka Kawata
PDF
Kotest を使って 快適にテストを書こう - KotlinFest 2024
by
Hirotaka Kawata
PDF
30日でできない!コンピューター自作入門 - カーネル/VM探検隊@つくば
by
Hirotaka Kawata
PDF
サーバーサイド Kotlin を社内で普及させてみた - Server-Side Kotlin Night 2025
by
Hirotaka Kawata
PDF
Micro Python で組み込み Python
by
Hirotaka Kawata
PDF
xv6 + mist32 + mruby
by
Hirotaka Kawata
PDF
KotlinConf 2018 から見る 最近の Kotlin サーバーサイド事情
by
Hirotaka Kawata
PDF
seccamp2012 チューター発表
by
Hirotaka Kawata
PDF
自作コンピューターでなんかする - 第八回 カーネル/VM探検隊&懇親会
by
Hirotaka Kawata
PDF
産学間連携推進室(AC部屋) 2012 成果報告会
by
Hirotaka Kawata
ODP
Open Design Computer Project - Tsukuba.pm
by
Hirotaka Kawata
ODP
About University of Tsukuba Linux User Group
by
Hirotaka Kawata
PDF
Introduction of PyCon JP 2014 in PyCon SG
by
Hirotaka Kawata
ゼロから始める自作 CPU 入門
by
Hirotaka Kawata
Kotest を使って 快適にテストを書こう - KotlinFest 2024
by
Hirotaka Kawata
30日でできない!コンピューター自作入門 - カーネル/VM探検隊@つくば
by
Hirotaka Kawata
サーバーサイド Kotlin を社内で普及させてみた - Server-Side Kotlin Night 2025
by
Hirotaka Kawata
Micro Python で組み込み Python
by
Hirotaka Kawata
xv6 + mist32 + mruby
by
Hirotaka Kawata
KotlinConf 2018 から見る 最近の Kotlin サーバーサイド事情
by
Hirotaka Kawata
seccamp2012 チューター発表
by
Hirotaka Kawata
自作コンピューターでなんかする - 第八回 カーネル/VM探検隊&懇親会
by
Hirotaka Kawata
産学間連携推進室(AC部屋) 2012 成果報告会
by
Hirotaka Kawata
Open Design Computer Project - Tsukuba.pm
by
Hirotaka Kawata
About University of Tsukuba Linux User Group
by
Hirotaka Kawata
Introduction of PyCon JP 2014 in PyCon SG
by
Hirotaka Kawata
本当にわかる Spectre と Meltdown
1.
本当にわかる Spectre と Meltdown 川田裕貴
@hktechno 1 セキュリティ・キャンプ全国大会2018 講義資料 URL: https://goo.gl/uTwX2c
2.
自己紹介 @hktechno 川田 裕貴
(かわた ひろたか) ● LINE 株式会社 開発1センター LINE 開発1室 ○ メッセンジャープラットフォームの開発 ○ 主に、スタンプ・絵文字・着せかえ、たまに IoT ● 自作 CPU 開発にハマっていた ○ アウト・オブ・オーダー実行できる自作 CPU ○ 主にコンパイラを作っていた ○ http://open-arch.org/ ○ http://amzn.asia/gtThKbh 2
3.
経歴? 2008年 セキュリティ・プログラミングキャンプ参加 2009, 2010,
2012 チューター, 2015 講師 2009年 筑波大学 情報学群 情報科学類 入学 2011年 IPA 未踏IT人材発掘・育成事業採択 (スーパークリエイターという謎の称号を頂く) 2014年 筑波大学大学院 コンピュータ・サイエンス専攻 入学 2016年 LINE 株式会社 入社 3
4.
本日の進め方 ● CPU の基本的な仕組み:
60分 ○ パイプライン、キャッシュ、投機的実行、分岐予測 ○ Spectre / Meltdown の理解に必要な知識の説明 ● Spectre / Meltdown の説明: 30分 ● Spectre Variant 1 PoC を作ってみよう: 90分 ○ Spectre Variant 1 の対策を考えてみよう ○ Spectre Variant 1 の考えた対策を実装してみよう ● Meltdown の PoC デモとか: 10分 ● Spectre Variant 4 の説明: 10分 ○ Foreshadow の説明も...? 4
5.
Spectre・Meltdown って何? 5
6.
Spectre と Meltdown
について CPU を対象としたサイドチャネル攻撃に対する脆弱性 ● 2018年1月に Google の Project Zero などが共同で公開した 論文が発端 ○ https://meltdownattack.com/ ● オリジナルの手法は大きく分けて3つ (Variant 1,2,3) ○ Variant 3 のことを特に Meltdown と呼ぶ ● 現代の CPU アーキテクチャを巧妙に操ることにより、 サイドチャネル攻撃を可能に ○ 具体的には、メモリ内容の吸い取り 6
7.
Spectre / Meltdown
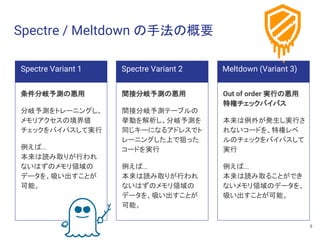
の手法の概要 公開当初、大きく3つの手法が公表された https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html Code Name 通称 CVE Spectre Variant 1 Bounds Check Bypass CVE-2017-5753 Variant 2 Branch Target Injection CVE-2017-5715 Meltdown Variant 3 Rouge Cache Data Load CVE-2017-5754 7
8.
Spectre / Meltdown
その後 その後、同じような脆弱性がいくつも発見されている... Code Name 通称 CVE Meltdown Variant 3a Rouge System Register Read CVE-2018-3640 SpectreNG Variant 4 Speculative Store Bypass CVE-2018-3639 Foreshadow (-NG) L1 Terminal Fault CVE-2018-3615 CVE-2018-3620 CVE-2018-3646 8
9.
Spectre / Meltdown
の手法の概要 条件分岐予測の悪用 分岐予測をトレーニングし、 メモリアクセスの境界値 チェックをバイパスして実行 例えば... 本来は読み取りが行われ ないはずのメモリ領域の データを、吸い出すことが 可能。 Spectre Variant 2 間接分岐予測の悪用 間接分岐予測テーブルの 挙動を解析し、分岐予測を 同じキーになるアドレスでト レーニングした上で狙った コードを実行 例えば... 本来は読み取りが行われ ないはずのメモリ領域の データを、吸い出すことが 可能。 Meltdown (Variant 3) Out of order 実行の悪用 特権チェックバイパス 本来は例外が発生し実行さ れないコードを、特権レベ ルのチェックをバイパスして 実行 例えば... 本来は読み取ることができ ないメモリ領域のデータを、 吸い出すことが可能。 Spectre Variant 1 9
10.
サイドチャネル攻撃とは 攻撃対象に直接手を加えるのではなく、動作を観察することによ り、その挙動の違いから情報を得ようとする手法 ● Spectre, Meltdown
においては、本来読み取れない領域にあ るメモリ内のデータを推測する手法 ○ 具体的には、メモリアクセスの時間の差を使う ● メモリ内のデータを ”直接” 読み取るわけではない ○ (実際は読み取っているわけだが... 詳細は後述) ● 元のプログラムに手を加える必要がなく、 攻撃を成功することができる (可能性がある) 10
11.
Meltdown と Spectre
の難しい点 よく CPU アーキテクチャを理解していないと、理解困難 ● アセンブリが書けるだけでは、知識が足りない ● 繊細な CPU の気持ちを、よくわかっている必要がある ハードウェア由来の脆弱性、ソフトウェアでの対策が困難 ● 不可能ではないが、パフォーマンスの低下を伴う ● Spectre Variant 2 については、一部のアーキテクチャでは ハードウェア支援がないと対策がとても難しい 11
12.
サイドチャネル攻撃 - Flush
+ Reload メモリアクセスのレイテンシの差を利用した攻撃 1. キャッシュをクリア (特に、以下の array2 の領域) ○ キャッシュを追い出す (Eviction) させてもいい 2. メモリを間接的にアクセスさせる ○ y = array2[array[x] * 4096] ○ array[x] のメモリ内容を基に array2 にアクセスする ○ 4096 をかけるのは、プリフェッチを防ぐため 3. array2 のアクセスレイテンシを調べる ○ キャッシュに乗っていればレイテンシ低⇓ ○ 過去にアクセスされた可能性大 => 値がわかる 12
13.
時間のかかる何か if (Array 境界値チェック) array1[array2[x]] その先の何か サイドチャネル攻撃
- Flush + Reload array2 攻撃対象 array1 CPU 時間かかるなぁ ここはよく true だから今回も true のときの 処理を投機的に実行だ! 間違ってたらあとでやりなおす! 13
14.
サイドチャネル攻撃 - Flush
+ Reload array2 攻撃対象 data[x] = 0xa array1 CPU 時間のかかる何か if (Array 境界値チェック) array1[array2[x]] その先の何か まだ終わってない x は確定していた! array[0xa] もアクセスできる! キャッシュに乗る! 準備完了 先に実行だ! 14
15.
サイドチャネル攻撃 - Flush
+ Reload array2 攻撃対象 data[x] = 0xa array1 CPU array1 を Flush 時間のかかる何か if (Array 境界値チェック) array1[array2[x]] その先の何か array1 を Reload array1 のキャッシュを消す array1 のアクセスレイテンシをチェック 過去にアクセスしたことがあれば速い。 レイテンシの差で、array2 のデータがわかる... 15
16.
基本的な CPU の仕組み 命令セットだけではわからない、CPU
内部の深い仕組み 16
17.
低レイヤとは システムソフトウェア VM OS kernel アセンブラ バイナリ CPUアーキテクチャ CPUのお話 その他のなにか 17
18.
低レイヤとは システムソフトウェア VM OS kernel アセンブラ バイナリ CPUアーキテクチャ その他のなにか 今日の話 18
19.
外の世界から見える CPU CPU の違いってなんだろう? ●
命令セットの違い ○ ARM vs x86 ○ 命令が増えた (e.g. AVX-512 とか...) ● クロック (2.4GHz, 3GHz, 4GHz…) ○ クロック数が変わってないから速度が変わらない? ● プロセス (14nm, 10nm, Tri-gate transistor…) ○ プロセスが細かくなったら何が良いの? CPU って中身どうなってるの??? 19
20.
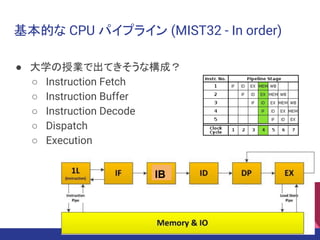
基本的な CPU パイプライン
(MIST32 - In order) ● 大学の授業で出てきそうな構成? ○ Instruction Fetch ○ Instruction Buffer ○ Instruction Decode ○ Dispatch ○ Execution IB 20
21.
Intel Skylake の内部 これが現実
⇨ ● 現代の CPU はとても複雑 ○ これでも単純化済 ● 命令の流れは一緒? ○ いろんなバッファ ○ 並列化 ● 日々進化する内部構造 /(^o^)\ よくわからない わかると楽しい\(^o^)/ 21
22.
Skylake の内部のパイプライン Skylake の詳細ブロック図 ●
Frontend ○ フェッチ ○ デコーダ (x86 では重要) ● Execution Engine ○ 実行ユニット ○ 投機的実行の核心部 ● Memory Subsystem ○ データ用メモリアクセス部 22
23.
Intel x86 の内部的な命令:
uOps (Micro-Ops) よく見る x86 の命令は、内部的な実行命令とは違う ● x86 アセンブラ1命令 => 複数の uOps ○ 最近は、逆の場合もある (Macro Fusion) ● なぜ命令を変換するのか? ○ x86 は CISC (命令がいろいろできるが複雑) ○ 時代・効率・回路規模は RISC ○ 設計が古いが、“互換性が重要” ○ 命令セットの設計に依存しない実行回路に ● Pentium III (P6) 以降に採用 23
24.
Intel x86 のフロントエンド デコーダが複雑 だが強い
RISC に負けないように... ● 命令セットがクソ 設計が大変古い => uOps で解決 ○ デコーダが大変複雑 ○ 消費電力、回路規模に悪影響... ● デコーダをなるべく動かさない設計 ○ 1度デコードしたところは、再度デコードしない ○ uOp Cache (以前は Trace cache) ○ Loop stream detector 24
25.
Intel x86 における、マイクロコード
(Microcode) ある1命令を、プログラム可能な uOps に変換する仕組み ● 利用目的 ○ ハードウェアの不具合 (エラッタ) の修正 ○ 複雑な命令の ● ハードウェアは基本的に修正パッチを当てられない ○ 出荷した後は不具合が修正不可能 ○ マイクロコードなら後からパッチを当てられる ● 利用例 ○ Haswell における TSX 無効化 ○ Spectre / Meltdown 対策における命令追加 25
26.
Intel x86 の実行ユニット 1コアの中に、複数の並列実行可能な実行ポート ●
スーパースカラ + 投機的実行 ○ 投機的実行の詳細は後ほど詳しく ● Skylake では、実行ポートは8ポート ○ Haswell 以降増えた https://www.anandtech.com/show/6355/intels-haswell-architecture/8 ● ポートごとにできることが違う ○ ALU, FPU ○ Branch ○ Load / Store 26
27.
Intel x86 のキャッシュとメモリアクセス ●
L1, L2, LLC (L3) の 3-Layer キャッシュ ○ L1 は Instruction, Data の2つのキャッシュ ● キャッシュラインは 64 byte ○ L1, L2: 8-way セットアソシアティブキャッシュ ○ 基本的にこの単位で、領域がキャッシュされる ● ページサイズは、基本的に 4096 byte ○ ページ境界を超えてプリフェッチはされない 27
28.
現代の CPU と Meltdown
/ Spectre の関係 28
29.
Meltdown / Spectre
がなぜ起きるのか 現代の CPU が命令を実行する際に行う、高度なハードウェアレ ベルでの最適化が原因 ● 特に、”投機的実行 (Speculative Execution)” と呼ばれる、命 令を先読みして高速化する手法が問題 CPU 内で行われる投機的実行の例 ● 命令のプリフェッチ ● ☆ アウト・オブ・オーダー実行 (順序を守らない実行) ● ☆ 分岐予測器を組み合わせた投機的実行 29
30.
“投機的” に命令列を実行して、間違っていたら結果を捨てる ● 書かれた命令の順番通りには実行しないこともある ○
何もしないで待っているより、何かを実行 ○ とにかく、パイプラインに隙間が生まれないように ● 間違って、実際には実行しない命令を、先読みして実行してし まうことがある ○ 最終的な結果には影響が出ないように結果を捨てる ○ 現代の CPU では、間違うことはかなり少ない うまく使うと脆弱性につながる可能性が...? 現代の CPU における投機的実行 30
31.
Out of Order Execution アウト・オブ・オーダー実行 CPU
の命令が上から順番に実行され るなんて、誰が言った! 31
32.
アウト・オブ・オーダー実行 (Out of Order
Execution, OoO) 先読みした命令の依存関係を解析して、実行できる命令から実際 の記述順序を無視して先に実行する ● 命令間のレジスタ依存関係を動的に解析する ○ 例えば、即値ロード命令は他の命令と依存関係がない ○ 即値ロード命令の例: mov eax, 0x1 ● CPU は、複数の命令実行ポートを持っている ○ すべての命令が同時に実行完了するとは限らない ● 依存しているレジスタの結果が準備されたら、先に実行 ○ レジスタマッピングや、書き戻しのバッファリングにより整 合性を保つ 32
33.
アウト・オブ・オーダー実行の例 mov eax, [eax] xor
ebx, ebx add ebx, eax inc ecx add eax, ecx Load (遅い) ↑の命令とは依存がない ↑の命令とは依存がない ※ 簡単な例で、特にアセンブリに意味はない 33
34.
アウト・オブ・オーダー実行の例 mov eax, [eax] xor
ebx, ebx add ebx, eax inc ecx add eax, ecx 1 1 2 1 2 ⇓実行順 命令の順番を入れ替えても構わない しかも、開いてる実行ポートで並列に実行できる Load (遅い) ↑の命令とは依存がない 先に実行が可能 ↑の命令とは依存がない 先に実行が可能 34
35.
OoO に関する疑問・破壊する常識 ● あるレジスタ
(eax や ebx) は CPU 内に1つじゃないの? ○ レジスタ・リネーミングを利用しています ○ 実はすべてただのエイリアスです ● CPU 内部で ”同時” に実行できる命令は1つじゃないの? ○ 複数の命令実行ポートが並列に並べられています ○ 例えば、Haswell 以降なら8実行ポート ● メモリアクセスを行う命令も並列に実行するの? ○ Intel の最近の CPU はメモリアクセスも OoO です ● なんでコンパイラでやらないの? ○ 成功していたら Itanium は死んでいない (VLIW) 35
36.
アウト・オブ・オーダー実行を支える技術 - 1 レジスタ・リネーミング
(Register Renaming) ● 物理レジスタを、内部の仮想レジスタにリネームする ● 命令の依存をより少なくできる mov eax, [eax] inc eax mov [eax], eax mov eax, ebx mov eax, [eax] 同じ eax レジスタ しかし、依存はない 実は先に実行可能 36
37.
アウト・オブ・オーダー実行を支える技術 - 1 レジスタ・リネーミング
(Register Renaming) ● 内部的なレジスタファイル内の物理レジスタと、論理レジスタ (eax, ebx…) との対応を持つ ○ 論理レジスタの数倍の物理レジスタを持っている mov r1, [r1] inc r1 mov [r1], r1 mov r3, r2 mov r3, [r3] レジスタ依存はない 実は先に実行可能 37
38.
レジスタ・リネーミング (Register Renaming) まとめると... ●
Intel x86 のレジスタ少なすぎない? ○ どうせリネーミングするからあまり問題にならない ● 内部的なレジスタファイルの大きさ (Skylake) ○ Integer 180個 ○ Vector 168個 ● リネーミング時に依存性の排除を行う ○ 0 や 1 の即値やクリアは特殊な扱いをする場合も ○ Zeroing Idioms, Ones Idioms 38
39.
アウト・オブ・オーダー実行を支える技術 - 2 Tomasulo
のアルゴリズム ● Reservation Station ○ 命令の依存関係を待つところ ○ ソースレジスタが利用可能かを監視して、 実行可能であれ ば実行を開始する ○ Unified な方式、実行ポートごとに持たせる方式 ● Re-order Buffer ○ 命令のコミットを制御するバッファ ○ 演算の結果は一度ここへ書かれる ※ 実際の Intel の CPU がこの通り実装されているわけではない 39
40.
Reservation Station の例 Reservation
Station 命令1 SRC1 NG SRC2 OK 命令2 NG NG 命令3 OK NG 命令4 OK OK Reorder Buffer, Register File Execution Unit へ 40
41.
Reorder Buffer を使ったデータの流れ Reorder
Buffer Stage 1. 割り当て Writeback Stage 2. 結果の書き込み Retire / Commit Reorder Buffer Register File 3. コミット ※ 実際の Intel の CPU がこの通り実装されているわけではない 41
42.
メモリアクセスのアウト・オブ・オーダー実行 レジスタとだいたい同じような仕組みで実装可能 ● メモリアクセスも順序は入れ替わる ○ LOAD
命令はできるものから先に実行 ○ 同じアドレスの LOAD は STORE より先に実行しない ○ Store Data の実行ポートは1つしかない ● 専用のバッファを持つ ○ 多分、専用のスケジューラを持っている ○ バッファのサイズ以上は先読みされない 42
43.
Reservation Station &
Reorder Buffer まとめると... ● CPU 内部では Reorder Buffer と Reservation Station の仕 組みにより、命令の実行順序が入れ替わる ● メモリアクセスも順番が入れ替わることがある Skylake における実装 ● Reorder Buffer 224 エントリ ● Reservation Station 97 エントリ 43
44.
Branch Prediction 分岐予測 運命の分かれ道 44
45.
分岐予測 (Branch Prediction) ブランチ命令で分岐する場合、行き先を予測して先に命令を読み 出し・実行を行う ●
Intel x86 でいうとジャンプ系の命令 Jxx (jne, je, jz…) ● 分岐するかしないか (“Taken” or “Not Taken”) および、 その分岐先をハードウェアで動的に予測する ○ 基本的に、過去の分岐結果をもとに分岐先を予測する ○ CPU 内部に過去の分岐履歴を保存している ● 予測した分岐先の命令を先読みして、実行する ○ 現代の CPU では予測成功率 99% 以上 (個人的な感想) 45
46.
分岐予測の例 - 簡単な分岐命令 mov
eax, [eax] cmp eax, 0 je is_zero ... ... is_zero: ... ... 実行完了するまで Jump するかわからない Load (遅い) Block 1 Block 2 Block1 or Block2 どちらかを投機的に実行したいが、高 確率で正解を選びたい 基本的な if 文であれば PC 相対ジャンプであることが多い 46
47.
分岐予測器ってどこにいるの フロントエンドにいる ● 分岐先アドレスを予測 ● ブランチ: CPU
にとって大きなコスト ● 分岐ミス: 長いパイプラインが止まる ❌ 分岐予測成功したらラッキー ⭕ 分岐予測ミスは致命的 47
48.
分岐予測器 (Branch Predictor) 古典的な実装 ●
分岐しない (or する) 方向で常に予測しておく ○ x86 だと Pentium 以前の CPU はこれ (i486 とか) ● 飽和カウンター (Bi-modal Counter) ○ 4つのステートを持って、1度ミスしただけでは予測方向が 変わらないような方式 ○ ループの分岐予測には有効 48
49.
分岐予測器 - 最近の
CPU の実装 いくつかの方式の組み合わせで、あらゆるパターンでも予測 ● 局所的分岐予測 ○ 同じアドレスの命令の、過去の分岐履歴を利用 ○ 同じアドレスで、同じパターンを繰り返す場合有用 ● グローバル分岐予測 ○ 過去のコア全体の分岐履歴のパターンをもとに、次の分岐 の挙動を予測 ● 上記の組み合わせを bit 演算で行い、予測テーブルを引く ○ PC + 局所履歴 + グローバル履歴 49
50.
分岐予測の例 - 絶対アドレス間接ジャンプ (Indirect
Branch) レジスタに格納されたアドレスにジャンプする場合 ● 例えばjXX [eax], call [eax] ● レジスタに格納されたアドレスが確定するまで、投機的実行が できない ○ これまでの手法は、PC 相対 + 即値ジャンプの場合 ○ 間接ジャンプで、特にLoad が噛むととても遅い ● 間接ジャンプ先も、実は予測可能では? ○ 同じ PC のジャンプは、よく同じアドレスにジャンプするので はないか? ※ PC (Program Counter): Intel では IP (Instruction Pointer) 実行中命令のアドレスのこと 50
51.
間接分岐予測の概要 Intel x86 の最近の実装 Indirect
Branch はちょっと特殊 アドレスだけでなく、history も 51
52.
Branch Target Buffer
(BTB) ブランチ命令のジャンプ先アドレスを記憶しておくバッファ ● 同じ PC のジャンプは、よく同じ場所に飛ぶことが多い ○ 間接的 (Indirect branch) であっても同じ ○ これをキャッシュしておけば、投機的実行を実際のアドレス 確定前に行うことが可能 ● PC => ブランチ先 PC のバッファを持つ ○ 最近の Intel x86 CPU の場合... ○ PC を XOR で圧縮して、BTB のキーとする ○ キー内の一部の bit は他の bit と共有される ○ つまり、エントリを共有する場合がある 52
53.
BTB の構造 -
Intel x86 Direct Branch Prediction 下位 31bit + XOR Folding でビット演算をして Lookup ● 下位 13 bit はそのまま ● 残りの 18bit に対して謎の XOR Folding を行う ○ 下記表参照 ⇨ ○ 規則性...? ● エントリの内容 ○ 下位32bitのアドレス ○ 4GB (2^32) を超えてジャンプ するかどうか ○ 上位 32bit のアドレス bit A bit B 0x40.0000 0x2000 0x80.0000 0x4000 0x100.0000 0x8000 0x200.0000 0x1.0000 0x400.0000 0x2.0000 0x800.0000 0x4.0000 0x2000.0000 0x10.0000 0x4000.0000 0x20.0000 53
54.
余談: なぜ BTB
は頑張ってビット幅を減らすのか 連想メモリ (CAM) は回路規模が厳しいから (多分) ● 大きな bit 列を比較 == 大きな規模のコンパレーター ○ エントリ数 * bit 幅に比例して大きくなる ○ 半分のビット幅にできたら、エントリが沢山入る ○ ただ、比較をするための回路でも馬鹿にできない ● ハードウェア上に大きな連想メモリを置くのは難しい ○ キャッシュ, TLB, BTB… ○ いろいろなものが、CAM の制限を受けている ○ 回路を作ってみるとわかるかも? 54
55.
BTB の概念と間接ジャンプの場合 分岐予測器はフロントエンドにいる ● パイプラインの隙間を開けない ○
ブランチを検知したら次のアドレスをすぐに確定 ○ 予測したブランチ先アドレスから、命令をフェッチ ○ 命令をデコードしたり、計算している暇はない ● レジスタを使った間接ジャンプでない場合は... ○ true or false で分岐先が確定 ○ 基本的に、分岐先を格納するものは1つで良い 間接ジャンプの場合は...? 分岐先の候補が複数あるかも? 55
56.
BTB の構造 -
Intel x86 - Indirect Branch Prediction 複数ある分岐予測先を予測するために... ● Branch History Buffer (BHB) を使う ○ 分岐元下位ビットを Branch buffer state に利用 ○ Branch buffer state は、右シフトしつつ新しい情報が加え られる ● 過去の分岐履歴が変わると、BTB エントリが別になる ○ 分岐履歴により、複数の分岐予測先を持てる 56
57.
Branch History Buffer
の挙動 (予測) void bhb_update(uint58_t *bhb_state, unsigned long src, unsigned long dst) { *bhb_state <<= 2; *bhb_state ^= (dst & 0x3f); *bhb_state ^= (src & 0xc0) >> 6; *bhb_state ^= (src & 0xc00) >> (10 - 2); *bhb_state ^= (src & 0xc000) >> (14 - 4); *bhb_state ^= (src & 0x30) << (6 - 4); *bhb_state ^= (src & 0x300) << (8 - 8); *bhb_state ^= (src & 0x3000) >> (12 - 10); *bhb_state ^= (src & 0x30000) >> (16 - 12); *bhb_state ^= (src & 0xc0000) >> (18 - 14); } 57
58.
余談: Return Stack
Buffer (RSB) call, ret 命令に特化したスタックバッファ ● call や ret も間接分岐命令だが... ● ret 命令は、直前の call の次の命令へジャンプ ○ call, ret は常にペアになっていることが多い ○ スタックへのアクセスは Load なのでとても遅い ● call 時に、アドレスをどこかに記憶しておけば... ○ => Return Stack Buffer ○ ret 命令後の投機的実行が高速に可能 ○ 複数の return address をスタックでキャッシュする 58
59.
余談: 現代の CPU
の分岐予測器の進化 分岐予測器の進化は、最近でも続いている (というかアツい) ● 電力をそれほど消費せずに性能向上が可能 ○ 分岐予測のミスは大きなペナルティ ○ ブランチ命令の先のパイプラインが止まってしまう ● ニューラルネットワーク分岐予測機 ○ AMD の CPU? Intel も? ● 各社詳しい仕様は公開していない ○ 改良されたという事実のみが記載されている ○ 外側から観察して挙動を推測するのみ 59
60.
Spectre / Meltdown
の手法解説 60
61.
Spectre Variant 1 Bounds Check
Bypass 61
62.
Spectre Variant 1 分岐予測をコントロールして、実際とは異なる方向に予測させた 上で、メモリ領域を吸い出す if
(x < array1_size) y = array2[array1[x] * 4096]; ● 予め正規の x で何度か実行し、分岐予測を訓練させる ● x を悪意のあるもの (array1_size 以上など) に設定 ○ array2 の領域の読み取りが投機的実行されてしまう ○ Flush + Reload により読み取り可能 62
63.
Spectre Variant 1
- 大まかな流れ cache_flush_array2(); // flush for (N) read(training_x); // training read(x + malicious_x); // attack check_array2_latency(); // reload --- void read(x) { if (x < array1_size) y = array2[array1[x] * 4096]; } 63
64.
Spectre Variant 1
を利用した攻撃の影響範囲 実行中の権限で読めるすべてのデータを読み取り可能 ● Intel 以外の CPU でも多く発生 ● ページテーブルに乗っていれば何でも読める ○ マップされてない領域は読めない ○ 特権昇格は不可能 ● コードを流し込めればいいので、うまくいくと...? ○ 仕組みが単純なので、色んな所に流し込める ○ カーネル空間に対して、eBPF という抜け道 ○ JavaScript 上で Spectre できたら? 64
65.
Spectre Variant 2 Branch Target
Injection 65
66.
正直 Variant 2
は結構難しい... 66
67.
Spectre Variant 2 BTB
と分岐履歴をコントロールして、上手に特定のアドレスの命 令を投機的実行させる ● BTB は、コア内で共通である ● 同じコア内の違うプロセス・スレッドで、うまいこと BTB と分岐 履歴を訓練することができる ○ 例えば、SMT (HT) で動作している場合など ○ キーは、アドレス下位ビットが XOR 圧縮される ● その中でアクセスしたデータはキャッシュに残る ○ もしかしたらデータを抜き出せるかもしれない ○ もちろん、レジスタは破棄される 67
68.
Spectre Variant 2
- BTB Injection BTB・BHB をうまく騙して、共有させる ● まずは BTB・BHB を訓練 ○ 投機的実行を騙して、実行させたいフローを再現 ● BTB のエントリは、共有される ○ 簡単にコントロールすることができる ● 例えば Direct branch prediction BTB の場合 ○ e.g. 0x100.0000 と 0x140.2000 はエントリが一緒 ■ ※ BTB の解説ページ参照 ■ 0x40.0000 と 0x2000 は XOR される ○ しかし、Direct branch BTB injection は成功率が低い? 68
69.
Spectre Variant 2 うまいこと
BHB を訓練させ、BTB を引く ● BHB は、過去の分岐履歴を保持する ● 分岐履歴を訓練させることは可能 ○ また、BHB はうまくやると 0 の状態を作れる ■ BHB の挙動スライドを参照 ■ このビット演算は XOR とシフトなので、反転してシフトしたものを流し込む と 0 にすることが可能 ○ その状態から、ジャンプ先アドレスを推測することも可能 ● 訓練は、他のプロセスから行える ○ うまく攻撃対象のコードへ誘導できるかも 69
70.
Meltdown Rouge Cache Data
Load 70
71.
Meltdown - Spectre
Variant 3 ユーザー権限で任意のメモリ領域の内容を推測可能な脆弱性 ● このシリーズの中で最もリスクが高い (個人的な感想) ● カーネル空間に物理メモリがそのままマップされている ○ Linux (x86_64) の場合 0xffff880000000000 ○ 通常は、ユーザーモードから読むことは不可能 ● 投機的実行と CPU の特権レベルの関わりが影響 ○ 特権レベルを無視して CPU が投機的実行を行う ○ 投機的実行を行ったあとに、特権違反により例外発生 ○ キャッシュの内容は...? ○ Intel の CPU のみで発生 71
72.
Meltdown の裏側 -
投機的実行 コードでは3行で説明できるぐらい簡単 ● 裏で何が起きているのかを説明するのが難しい ... raise_exception(); // 実際はここまで // 以下の行には到達しない, でも OoO で実行されてる access(probe_array[data * 4096]); CPU の投機的実行は何を行うのだろう? 72
73.
Meltdown の裏側 -
投機的実行 kernel_adder の内容を Flush+Reload で推測する例 raise_exception(); access(probe_array[*kernel_addr * 4096]); 投機的実行により、kernel_addr と proble_array の load が raise_exception() より先に行われる ● 特権レベルの確認より先にメモリの読み取りが行われる ● proble_array を Flush + Reload で *kernel_addr を吸い出し 73
74.
Meltdown の裏側 -
投機的実行 Meltdown のアセンブリの例 ; rcx = kernel address ; rbx = probe array retry: mov al, byte [rcx] ; 実際はここで例外 shl rax, 0xc jz retry mov rbx, qword [rbx + rax] 74
75.
仮想アドレス空間のメモリマップ - Linux
x86_64 物理メモリすべての領域が 0xffff880000000000 からマップ ● ユーザー領域は仮想アドレス空間の先頭に配置 ● 後半部分に、物理メモリすべてがストレートマップ ○ つまり、物理メモリに乗っていれば、すべての ユーザー空間・カーネル空間の領域にアクセス可能 75
76.
なぜ、物理メモリをすべてマップするのか? システムコール・コンテキストスイッチの高速化のため ● ページテーブル切り替えのコストを削減 ○ カーネル空間が別ページテーブルであれば... ■
システムコール毎に、ページテーブル切替 + TLB フラッシュ ○ カーネル空間のアドレスがページテーブル (プロセス) ごと に異なるならば... ■ Global Page が使えない => カーネル空間の TLB が毎回消される ● TLB フラッシュは大きなコスト ○ ページウォーク => メモリアクセス ○ カーネル空間を常に TLB に載せておきたい 76
77.
まとめ 77
78.
Spectre / Meltdown
まとめ 高度で複雑な CPU 高速化によって、思いがけない問題が ● 一般的なコンピューター全てで動作するという怖さ ○ 成功率・実現性などを考えたとしても、できる可能性がある ということを、見逃してはいけない ● CPU を作っている人たちはどう思っていただろう? ○ 問題として捉えていたのかどうか ○ 自分だったら、見逃してしまっていたかも... ○ とはいえ、Meltdown は明らかに問題がある ● この後も、様々な変種が発見されていく...? ○ セキュリティ技術者にとってはチャンス? 78
79.
Spectre Variant 1
実習編 79 演習コード URL: https://goo.gl/52P4UY
80.
Spectre Variant 1
の PoC を作ってみよう 同じプログラム内の配列を直接読み出さずに Spectre する ● これまでの仕組みを利用して、”CPU を騙してみよう” ○ 理解してしまったら単純な仕組みだが... ○ 書いてみたらちょっと難しい ○ PoC を書いてみたからわかることも ● 何個か実装にあたって気をつけない点が ○ CPU の気持ちがわからないといけない ○ 投機的実行のデバッグはほぼ不可能 80
81.
実装のコツ - Flush
+ Reload ● 必要な配列 char *secret; // 攻撃対象の文字列 uint8_t array1[適当な長さ]; // ダミー配列 uint8_t array2[256 * ???]; // Flush+Reload用 ● 気をつけること: キャッシュライン・プリフェッチ ○ array1 と array2 の配置 ○ array2 の長さ: char == 8bit == 256 ■ それぞれの要素がキャッシュに乗る乗らないを判別するには? 81
82.
実装のコツ - Flush ●
Flush には Intrinsic を使う ○ 特殊なアセンブリを実行する組み込み関数 ● その他利用すると便利な Intrinsics ○ #include <x86intrin.h> ○ _mm_clflush(addr) ■ 特定アドレスのキャッシュをフラッシュ ○ __rdtscp(&junk); ■ クロックサイクル単位の高精度タイムスタンプカウンタを読む ■ Reload で利用 ○ _mm_mfence(); ■ メモリフェンス命令 ■ メモリアクセスが、必ずこの命令のあとで実行される 82
83.
実装のコツ - Reload メモリアクセスのレイテンシを読み取る例 int
junk = 0; uint64_t time1, time2; time1 = __rdtscp(&junk); junk = *addr; time2 = __rdtscp(&junk) - time1; ● junk が最適化でいなくならないように ○ どこかでなにか使ってあげてください ● addr は、必ず volatile をつけること ○ addr のメモリを必ず読んで、レイテンシを測るため 83
84.
実装のコツ - 分岐予測 if
(x < array1_size) y = array2[array1[x] * 4096]; ● 正しい分岐を何度か成功させ学習させる ○ array1_size 以下の x を利用して “何度か” 実行 ○ array1_size 以上の “非正規な” x を利用して実行 ● コンパイラの最適化で消されないように ○ y は何も操作しない && ローカル変数では ○ y はメモリをいじるように volatile ○ なにか演算をさせたほうが良い 84
85.
実装のコツ - 分岐予測 if
(x < array1_size) y = array2[array1[x] * 4096]; ● 分岐予測 + 投機的なメモリアクセスが成功する条件 ○ 分岐予測後メモリアクセスが完了するまでに、 条件分岐が実際に確定してはいけない ○ if の前に何らかの時間稼ぎが必要 ● 時間稼ぎに使えそうなもの ○ 適当なメモリアクセス (条件を確定させないためには? ○ 適当な膨大な量の計算 ○ OoO で Reorder・LOAD されることも考慮にいれて... 85
86.
実装のコツ - 分岐予測 学習ループ内に条件分岐を生やすとうまく行かないことも ●
例えば、実際に攻撃対象の非正規 x を指定するときなど ● ループから出るのも条件が変わるので微妙 ● 以下のような技も必要かも // if (j % 6 == 0) x = malicious_x; // else x = training_x; x = ((j % 6) - 1) & ~0xFFFF; x = (x | (x >> 16)); x = training_x ^ (x & (malicious_x ^ training_x)); 86
87.
Spectre Variant 1
の PoC を作ってみよう すぐに終わって先に進みたい猛者たちに... ● コンパイラの最適化を有効にしてみよう ○ -O1 多分そのまま動く/ -O0 より成功率高い? ○ -O2, -O3 ちょっと考えないと難しい ● パラメーターをいじったりループ回数を変更して、投機的実行 の結果・CPU の動作を観察してみよう ○ 分岐予測の訓練回数を減らす・増やす ○ メモリアクセスを減らす・増やす ○ array2 のオフセットを減らす・増やす 87
88.
Spectre / Meltdown
対策を考えてみよう コンパイラ・CPU・カーネル... どんな対策でも OK ● Variant 1 ★☆☆ ○ 境界値チェックが投機的実行されても安全な方法は? ○ パッチを当てて、確かめてみよう ● Variant 2 ★★★ ○ 間接ブランチ命令を使わないでジャンプ...? ● Meltdown / Variant 3 ★★☆ ○ ユーザー空間とカーネル空間の分離...? ※ 答えを知ってる人は、それを自分なりに説明してみよう 88
89.
派生手法 89 Spectre Variant 4
(SpectreNG) Foreshadow
90.
Spectre Variant 4
(Spectre NG) Speculative Store Bypass (投機的ストアバイパス) https://blogs.technet.microsoft.com/srd/2018/05/21/analysis-and-mitigation-of-speculative-store-bypass-cve-2018-3639/ ● LOAD 命令は投機的に実行される ● 手前にある STORE のアドレスが確定していなくても、LOAD は先読みされる mov [rdi+rcx],al movzx r8,byte [rsi+rcx] shl r8,byte 0xc mov eax,[rdx+r8] 90 ⇦ これはどうなる?
91.
Spectre Variant 4
(Spectre NG) STORE のアドレスが確定したあと... ● 以下の条件の場合、movzx が先に実行されてしまう ○ ”rdi” が未確定、“rsi” が確定済み ○ しかし、rsi と rdi が最終的に同じだったら? mov [rdi+rcx],al movzx r8,byte [rsi+rcx] shl r8,byte 0xc mov eax,[rdx+r8] 91
92.
Foreshadow, Foreshadow-NG NEW! L1
Terminal Fault を利用したメモリ内容の抜き取り ● ページテーブルエントリ (PTE) は P bit (present) のような、有 効か無効かという情報を保持している ○ もし、PTE が無効なら Terminal fault が発生 ● Intel の CPU はこのような Fault が発生するとしても、先に L1 へアクセスしに行く ○ 無効な PTE を使うかも ○ 高速化のため ○ 結果は捨てるが... ○ Page walk の時間内に... 92
93.
本当にわかる Spectre と Meltdown
対策編 川田裕貴 @hktechno 93 セキュリティ・キャンプ全国大会2018 講義資料 URL: https://goo.gl/uTwX2c PoC コード: https://goo.gl/Uozhy6
94.
Spectre Variant 1 Bounds Check
Bypass 対策編 94
95.
Spectre Variant 1
対策 array の index のビットをマスクする ● array の外側にアクセスできないようにすればいい ○ ブランチ命令はいくらでも学習可能なので使えない ○ 投機的実行が起きても問題ないように ● ビット演算のみで行う ○ パフォーマンス低下もそれほどではない ○ cmp size,index; sbb mask,mask; => x と AND ● Linux Kernel : array_index_nospec ○ https://github.com/torvalds/linux/blob/v4.17/include/linux/nospec.h ○ https://github.com/torvalds/linux/blob/v4.17/arch/x86/include/asm/barrier.h 95
96.
Spectre Variant 1
対策 既存のもの (CPU, ソフトウェア) に対する対策はほぼ不可能 ● CPU の microcode だけで治せるような問題ではない ● Intel 以外の CPU でも存在 ○ 高速化のためにみんなやっていること ○ 問題があることにどのベンダーも気づいていなかった ○ 将来的にはどうなるのかまだわからない... ● ソフトウェア側では対応可能だが... ○ コンパイル済みのものは不可能 ○ コンパイラが、コンパイル時に行うのも難しい ○ 手でコードを入れるしかない 96
97.
Spectre Variant 1
対策 JavaScript や eBPF に対する対策 ● 根本的な対策ではない ● JavaScript ○ JavaScript 上でも、仕組み的には Spectre できる ○ Timer の精度を下げると Spectre しづらくなる ● eBPF ○ 無効にする ○ Spectre に使われそうな部分に、きちんと対策をしておく 97
98.
Spectre Variant 2 Branch Target
Injection 対策編 98
99.
Spectre Variant 2
対策 Indirect branch が BTB を共有するのが問題だった ● ハードウェアによる対策 (microcode update) ○ 命令の追加: IBRS, IBPB, STIPB ○ IBRS: BTB の利用の抑制する命令 ● Indirect branch を使わなければ良い 99
100.
Spectre Variant 2
対策 - Retpoline ROP のような手法を使って、投機的実行を騙す ret は RSB (Return Stack Buffer) を利用して投機的実行する call retpoline_call_target 2: /* 投機的実行はこっちに行く */ lfence /* stop speculation */ jmp 2b retpoline_call_target: lea 8(%rsp), %rsp /* スタック操作 */ ret /* 2: には戻らない */ 100
101.
Spectre Variant 2
対策 - Retpoline しかし、Retpoline にも問題があることがわかった ● Return Stack Buffer (RSB) が枯渇したとき ○ BTB を引きにいく場合がある ○ どうも、Skylake 以降でこの修正が入った? ● うまいこと RSB を枯渇させられると、死んでしまう 101
102.
Meltdown Rouge Cache Data
Load 対策編 102
103.
Meltdown 対策 Kernel Page
Table Isolation : KPTI ● カーネルページテーブルの分離 ○ ユーザープロセスのページテーブルから、カーネル領域が 見えないように ○ Linux では KAISER という仕組みを実装 ● パフォーマンス低下の問題 ○ 最近の Intel CPU (Haswell 以降) では、緩和される ■ PCID のサポートの有無 ○ 新しい Kernel + CPU を使っていれば問題ない ○ 古い CPU では、パフォーマンス低下が大きめ 103
104.
TLB (Translation Lookaside
Buffer) と ページテーブルの関係 ページテーブルをキャッシュするものが TLB ● ページテーブルを引く (page walk) はとても遅い ● よくアクセスする領域は TLB にキャッシュする ○ ページテーブル切替時に、TLB はフラッシュされる ● KPTI を行うことで、カーネルを呼ぶたび TLB フラッシュ ○ とても遅くなる 104 これまで KPTI User -> Kernel いらない TLB フラッシュ必要 プロセス切替 TLB フラッシュ必要 TLB フラッシュ必要
105.
KPTI と PCID PCID
(Process Contex Identifers) により性能低下を抑制 ● KPTI の問題: TLB が syscall でフラッシュされること ● プロセスごとに PCID を設定 ● PCID を TLB にタグ付け、指定したタグだけフラッシュ ○ INVPCID 命令 ○ PCID, INVPCID は、比較的最近 x86 に追加された機能 105 仮想アドレス タグ (PCID) 物理アドレス 0x10000000 100 0x00001000 0x10000000 200 0x00002000 0x20000000 100 0x00003000
106.
PCID のメリット PCID を導入すると、部分的に
TLB フラッシュが可能 106 これまで KPTI KPTI + PCID User -> Kernel いらない 全フラッシュ 一部フラッシュ プロセス切替 全フラッシュ 全フラッシュ 一部フラッシュ
107.
参考文献 https://spectreattack.com/ https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with -side.html https://blogs.technet.microsoft.com/srd/2018/05/21/analysis-and-mitigation-of-s peculative-store-bypass-cve-2018-3639/ https://www.slideshare.net/mhiramat/spectrebusterslinuxspectre https://speakerdeck.com/sat/tu-jie-dewakaruspectretomeltdown http://mmi.hatenablog.com/entry/2018/02/02/003325 https://github.com/crozone/SpectrePoC https://github.com/IAIK/meltdown https://github.com/paboldin/meltdown-exploit https://github.com/tbodt/spectre https://foreshadowattack.eu/ 107
Download











![サイドチャネル攻撃 - Flush + Reload
メモリアクセスのレイテンシの差を利用した攻撃
1. キャッシュをクリア (特に、以下の array2 の領域)
○ キャッシュを追い出す (Eviction) させてもいい
2. メモリを間接的にアクセスさせる
○ y = array2[array[x] * 4096]
○ array[x] のメモリ内容を基に array2 にアクセスする
○ 4096 をかけるのは、プリフェッチを防ぐため
3. array2 のアクセスレイテンシを調べる
○ キャッシュに乗っていればレイテンシ低⇓
○ 過去にアクセスされた可能性大 => 値がわかる
12](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-12-320.jpg)
![時間のかかる何か
if (Array 境界値チェック)
array1[array2[x]]
その先の何か
サイドチャネル攻撃 - Flush + Reload
array2
攻撃対象
array1
CPU
時間かかるなぁ
ここはよく true だから今回も true のときの
処理を投機的に実行だ!
間違ってたらあとでやりなおす!
13](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-13-320.jpg)
![サイドチャネル攻撃 - Flush + Reload
array2
攻撃対象
data[x] = 0xa
array1
CPU
時間のかかる何か
if (Array 境界値チェック)
array1[array2[x]]
その先の何か
まだ終わってない
x は確定していた!
array[0xa] もアクセスできる!
キャッシュに乗る!
準備完了
先に実行だ!
14](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-14-320.jpg)
![サイドチャネル攻撃 - Flush + Reload
array2
攻撃対象
data[x] = 0xa
array1
CPU
array1 を Flush
時間のかかる何か
if (Array 境界値チェック)
array1[array2[x]]
その先の何か
array1 を Reload
array1 のキャッシュを消す
array1 のアクセスレイテンシをチェック
過去にアクセスしたことがあれば速い。
レイテンシの差で、array2 のデータがわかる...
15](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-15-320.jpg)
















![アウト・オブ・オーダー実行の例
mov eax, [eax]
xor ebx, ebx
add ebx, eax
inc ecx
add eax, ecx
Load (遅い)
↑の命令とは依存がない
↑の命令とは依存がない
※ 簡単な例で、特にアセンブリに意味はない
33](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-33-320.jpg)
![アウト・オブ・オーダー実行の例
mov eax, [eax]
xor ebx, ebx
add ebx, eax
inc ecx
add eax, ecx
1
1
2
1
2
⇓実行順
命令の順番を入れ替えても構わない
しかも、開いてる実行ポートで並列に実行できる
Load (遅い)
↑の命令とは依存がない
先に実行が可能
↑の命令とは依存がない
先に実行が可能
34](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-34-320.jpg)

![アウト・オブ・オーダー実行を支える技術 - 1
レジスタ・リネーミング (Register Renaming)
● 物理レジスタを、内部の仮想レジスタにリネームする
● 命令の依存をより少なくできる
mov eax, [eax]
inc eax
mov [eax], eax
mov eax, ebx
mov eax, [eax]
同じ eax レジスタ
しかし、依存はない
実は先に実行可能
36](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-36-320.jpg)
![アウト・オブ・オーダー実行を支える技術 - 1
レジスタ・リネーミング (Register Renaming)
● 内部的なレジスタファイル内の物理レジスタと、論理レジスタ
(eax, ebx…) との対応を持つ
○ 論理レジスタの数倍の物理レジスタを持っている
mov r1, [r1]
inc r1
mov [r1], r1
mov r3, r2
mov r3, [r3]
レジスタ依存はない
実は先に実行可能
37](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-37-320.jpg)








![分岐予測の例 - 簡単な分岐命令
mov eax, [eax]
cmp eax, 0
je is_zero
...
...
is_zero:
...
...
実行完了するまで
Jump するかわからない
Load (遅い)
Block 1
Block 2
Block1 or Block2
どちらかを投機的に実行したいが、高
確率で正解を選びたい
基本的な if 文であれば PC 相対ジャンプであることが多い
46](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-46-320.jpg)



![分岐予測の例 - 絶対アドレス間接ジャンプ
(Indirect Branch)
レジスタに格納されたアドレスにジャンプする場合
● 例えばjXX [eax], call [eax]
● レジスタに格納されたアドレスが確定するまで、投機的実行が
できない
○ これまでの手法は、PC 相対 + 即値ジャンプの場合
○ 間接ジャンプで、特にLoad が噛むととても遅い
● 間接ジャンプ先も、実は予測可能では?
○ 同じ PC のジャンプは、よく同じアドレスにジャンプするので
はないか?
※ PC (Program Counter): Intel では IP (Instruction Pointer)
実行中命令のアドレスのこと
50](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-50-320.jpg)











![Spectre Variant 1
分岐予測をコントロールして、実際とは異なる方向に予測させた
上で、メモリ領域を吸い出す
if (x < array1_size)
y = array2[array1[x] * 4096];
● 予め正規の x で何度か実行し、分岐予測を訓練させる
● x を悪意のあるもの (array1_size 以上など) に設定
○ array2 の領域の読み取りが投機的実行されてしまう
○ Flush + Reload により読み取り可能
62](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-62-320.jpg)
![Spectre Variant 1 - 大まかな流れ
cache_flush_array2(); // flush
for (N) read(training_x); // training
read(x + malicious_x); // attack
check_array2_latency(); // reload
---
void read(x) {
if (x < array1_size)
y = array2[array1[x] * 4096];
}
63](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-63-320.jpg)








![Meltdown の裏側 - 投機的実行
コードでは3行で説明できるぐらい簡単
● 裏で何が起きているのかを説明するのが難しい
...
raise_exception(); // 実際はここまで
// 以下の行には到達しない, でも OoO で実行されてる
access(probe_array[data * 4096]);
CPU の投機的実行は何を行うのだろう?
72](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-72-320.jpg)
![Meltdown の裏側 - 投機的実行
kernel_adder の内容を Flush+Reload で推測する例
raise_exception();
access(probe_array[*kernel_addr * 4096]);
投機的実行により、kernel_addr と proble_array の load が
raise_exception() より先に行われる
● 特権レベルの確認より先にメモリの読み取りが行われる
● proble_array を Flush + Reload で *kernel_addr を吸い出し
73](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-73-320.jpg)
![Meltdown の裏側 - 投機的実行
Meltdown のアセンブリの例
; rcx = kernel address
; rbx = probe array
retry:
mov al, byte [rcx] ; 実際はここで例外
shl rax, 0xc
jz retry
mov rbx, qword [rbx + rax]
74](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-74-320.jpg)






![実装のコツ - Flush + Reload
● 必要な配列
char *secret; // 攻撃対象の文字列
uint8_t array1[適当な長さ]; // ダミー配列
uint8_t array2[256 * ???]; // Flush+Reload用
● 気をつけること: キャッシュライン・プリフェッチ
○ array1 と array2 の配置
○ array2 の長さ: char == 8bit == 256
■ それぞれの要素がキャッシュに乗る乗らないを判別するには?
81](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-81-320.jpg)


![実装のコツ - 分岐予測
if (x < array1_size)
y = array2[array1[x] * 4096];
● 正しい分岐を何度か成功させ学習させる
○ array1_size 以下の x を利用して “何度か” 実行
○ array1_size 以上の “非正規な” x を利用して実行
● コンパイラの最適化で消されないように
○ y は何も操作しない && ローカル変数では
○ y はメモリをいじるように volatile
○ なにか演算をさせたほうが良い
84](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-84-320.jpg)
![実装のコツ - 分岐予測
if (x < array1_size)
y = array2[array1[x] * 4096];
● 分岐予測 + 投機的なメモリアクセスが成功する条件
○ 分岐予測後メモリアクセスが完了するまでに、
条件分岐が実際に確定してはいけない
○ if の前に何らかの時間稼ぎが必要
● 時間稼ぎに使えそうなもの
○ 適当なメモリアクセス (条件を確定させないためには?
○ 適当な膨大な量の計算
○ OoO で Reorder・LOAD されることも考慮にいれて...
85](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-85-320.jpg)




![Spectre Variant 4 (Spectre NG)
Speculative Store Bypass (投機的ストアバイパス)
https://blogs.technet.microsoft.com/srd/2018/05/21/analysis-and-mitigation-of-speculative-store-bypass-cve-2018-3639/
● LOAD 命令は投機的に実行される
● 手前にある STORE のアドレスが確定していなくても、LOAD
は先読みされる
mov [rdi+rcx],al
movzx r8,byte [rsi+rcx]
shl r8,byte 0xc
mov eax,[rdx+r8]
90
⇦ これはどうなる?](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-90-320.jpg)
![Spectre Variant 4 (Spectre NG)
STORE のアドレスが確定したあと...
● 以下の条件の場合、movzx が先に実行されてしまう
○ ”rdi” が未確定、“rsi” が確定済み
○ しかし、rsi と rdi が最終的に同じだったら?
mov [rdi+rcx],al
movzx r8,byte [rsi+rcx]
shl r8,byte 0xc
mov eax,[rdx+r8]
91](https://image.slidesharecdn.com/meltdown2fspectre3-180817120407/85/Spectre-Meltdown-91-320.jpg)






















































![[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理](https://cdn.slidesharecdn.com/ss_thumbnails/basic-07-180228134341-thumbnail.jpg?width=640&height=640&fit=bounds)





















